Spark 实现自己的RDD,让代码更优雅
2017-01-15 00:00
274 查看
你是否在最初书写spark的代码时总是使用object 是否在为代码的重复而忧心,接下来的博客中,我会专注于spark代码简洁性。
1,什么事RDD,官网上有很全面的解释,在此不再赘述,不过我们需要从代码层面上理解什么事RDD,如果他是一个类,他又有哪些重要的属性和方法,现在列出以下几点:
1)partitions():Get the array of partitions of this RDD, taking into account whether the
RDD is checkpointed or not. Partition是一个特质,分布在每一个excutor上的分区,都会有一个Partition实现类去做唯一标识。
2)iterator():Internal method to this RDD; will read from cache if applicable, or otherwise compute it. This should not be called by users directly, but is available for implementors of custom subclasses of RDD. 这是一个RDD的迭代器,传入的参数是Partition和TaskContext,这样就可以在每一个Partition上执行相应的逻辑了。
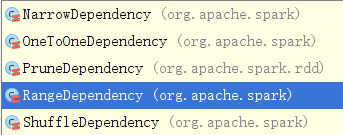
3)dependencies():Get the list of dependencies of this RDD,在1.6中,Dependency共有如下几个继承类,后续博文会详解它,感兴趣的读者可以直接阅读源码进一步了解
4)partitioner():此函数返回一个Option[Partitioner],如果RDD不是key-value pair RDD类型的数据,那么为None,我们和以自己实现这个抽象类。当时看到这里,我就在想为什么不能实现一个特质,而要用
抽象类,个人理解这是属于面向对象的东西了,类是实体的抽象爱,而接口则定义一些行为。
5)preferredLocations():Optionally overridden by subclasses to specify placement preferences.
下面我们自己实现一个和Mysql交互的RDD,只涉及到上面说的部分函数,当然在生产环境中不建议这样做,除非你自己想把自己的mysql搞挂,此处只是演示,对于像Hbase之类的分布式数据库,逻辑类似。
1,什么事RDD,官网上有很全面的解释,在此不再赘述,不过我们需要从代码层面上理解什么事RDD,如果他是一个类,他又有哪些重要的属性和方法,现在列出以下几点:
1)partitions():Get the array of partitions of this RDD, taking into account whether the
RDD is checkpointed or not. Partition是一个特质,分布在每一个excutor上的分区,都会有一个Partition实现类去做唯一标识。
2)iterator():Internal method to this RDD; will read from cache if applicable, or otherwise compute it. This should not be called by users directly, but is available for implementors of custom subclasses of RDD. 这是一个RDD的迭代器,传入的参数是Partition和TaskContext,这样就可以在每一个Partition上执行相应的逻辑了。
3)dependencies():Get the list of dependencies of this RDD,在1.6中,Dependency共有如下几个继承类,后续博文会详解它,感兴趣的读者可以直接阅读源码进一步了解
4)partitioner():此函数返回一个Option[Partitioner],如果RDD不是key-value pair RDD类型的数据,那么为None,我们和以自己实现这个抽象类。当时看到这里,我就在想为什么不能实现一个特质,而要用
抽象类,个人理解这是属于面向对象的东西了,类是实体的抽象爱,而接口则定义一些行为。
5)preferredLocations():Optionally overridden by subclasses to specify placement preferences.
下面我们自己实现一个和Mysql交互的RDD,只涉及到上面说的部分函数,当然在生产环境中不建议这样做,除非你自己想把自己的mysql搞挂,此处只是演示,对于像Hbase之类的分布式数据库,逻辑类似。
package com.hypers.rdd
import java.sql.{Connection, ResultSet}
import org.apache.spark.annotation.DeveloperApi
import org.apache.spark.rdd.RDD
import org.apache.spark.{Logging, Partition, SparkContext, TaskContext}
import scala.reflect.ClassTag
//TODO 去重
class HFAJdbcRDD[T: ClassTag]
(sc: SparkContext,
connection: () => Connection, //method
sql: String,
numPartittions: Int,
mapRow: (ResultSet) => T
) extends RDD[T](sc, Nil) with Logging {
/**
* 若是这个Rdd是有父RDD 那么 compute一般会调用到iterator方法 将taskContext传递出去
* @param thePart
* @param context
* @return
*/
@DeveloperApi
override def compute(thePart: Partition, context: TaskContext): Iterator[T] = new Iterator[T] {
val part = thePart.asInstanceOf[HFAJdbcPartition]
val conn = connection()
//如果直接执行sql会使数据重复,因此此处使用分页
val stmt = conn.prepareStatement(String.format("%s limit %s,1",sql,thePart.index.toString), ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY)
logInfo("Get sql data size is " + stmt.getFetchSize)
val rs: ResultSet = stmt.executeQuery()
override def hasNext: Boolean = {
if(rs.next()){
true
}else{
conn.close()
false
}
}
override def next(): T = {
mapRow(rs)
}
}
/**
* 将一些信息传递到compute方法 例如sql limit 的参数
* @return
*/
override protected def getPartitions: Array[Partition] = {
(0 until numPartittions).map { inx =>
new HFAJdbcPartition(inx)
}.toArray
}
}
private class HFAJdbcPartition(inx: Int) extends Partition {
override def index: Int = inx
}package com.hypers.rdd.execute
import java.sql.{DriverManager, ResultSet}
import com.hypers.commons.spark.BaseJob
import com.hypers.rdd.HFAJdbcRDD
//BaseJob里面做了sc的初始化,在此不做演示,您也可以自己new出sparkContext
object HFAJdbcTest extends BaseJob {
def main(args: Array[String]) {
HFAJdbcTest(args)
}
override def apply(args: Array[String]): Unit = {
val jdbcRdd = new HFAJdbcRDD[Tuple2[Int, String]](sc,
getConnection,
"select id,name from user where id<10",
3,
reseultHandler
)
logger.info("count is " + jdbcRdd.count())
logger.info("count keys " + jdbcRdd.keys.collect().toList)
}
def getConnection() = {
Class.forName("com.mysql.jdbc.Driver").newInstance()
DriverManager.getConnection("jdbc:mysql://localhost:3306/db", "root", "123456")
}
def reseultHandler(rs: ResultSet): Tuple2[Int, String] = {
rs.getInt("id") -> rs.getString("name")
}
}

相关文章推荐
- Spark RDD(DataFrame) 写入到HIVE的代码实现
- 发一个自己用JS写的实用看图工具实现代码
- [导入]自己动手实现 lucene 搜索代码高亮显示
- 用java代码实现一个自己的栈.
- 自己动手实现简易代码生成器、采用文本模板文件生成服务层、服务层接口代码的做法参考
- 自己实现了一下C++STL中的next_permutation,名为ant_next_permutation,发下代码
- 可以自己实现重定位的代码
- 问题1:java中没有实现这种“byte a = 0xB2 --> String b = “B2””转换的简单实现需要自己实现。 答:自己编写的转换函数,思路将byte的高低4位分开,分别转换为对应的字符然后合成返回的字符串。 java 代码 1.
- 自己实现纯win32窗口事件(编辑框输入浮点数,静态框实现超链接,以前网上看见过相似代码自己改哈,以后有用)
- 【转】vs2005实现将自己的代码自动添加版权信息技巧
- 自己写代码实现分页导航
- 原创:自己写代码实现遥感影像自动配准
- 根据Merge Sort原理, 自己实现的归并排序算法+详细注释+代码(C#,C/C++) [分享]
- 基于Ogre::Bites实现自己的GUI系统(4)--包含代码下载地址
- 巧用STL中的绑定器和函数对象嵌套调用实现优雅高效的代码
- 自己动手实现 lucene 搜索代码高亮显示
- 自己实现的简单的Vector代码
- 根据Merge Sort原理, 自己实现的归并排序算法+详细注释+代码(C#,C/C++) [分享]
- 实现IDisposable以实现更优雅的代码
- 自己动手实现简易代码生成器、采用文本模板文件生成服务层、服务层接口代码的做法参考