Weka 常用分类算法效果比较
2017-01-12 13:39
393 查看
本实验是福建矿产分布分类识别实验,使用常用的weka 分类识别算法,第一组实验只使用数据中的数值型数据,第二组实验在数值型特征基础上加上了标称属性分类。
2-NN
3-NN
Naive Bayes
Bayes Net
Complement Naive Bayes
Simple Logistic
Logistic
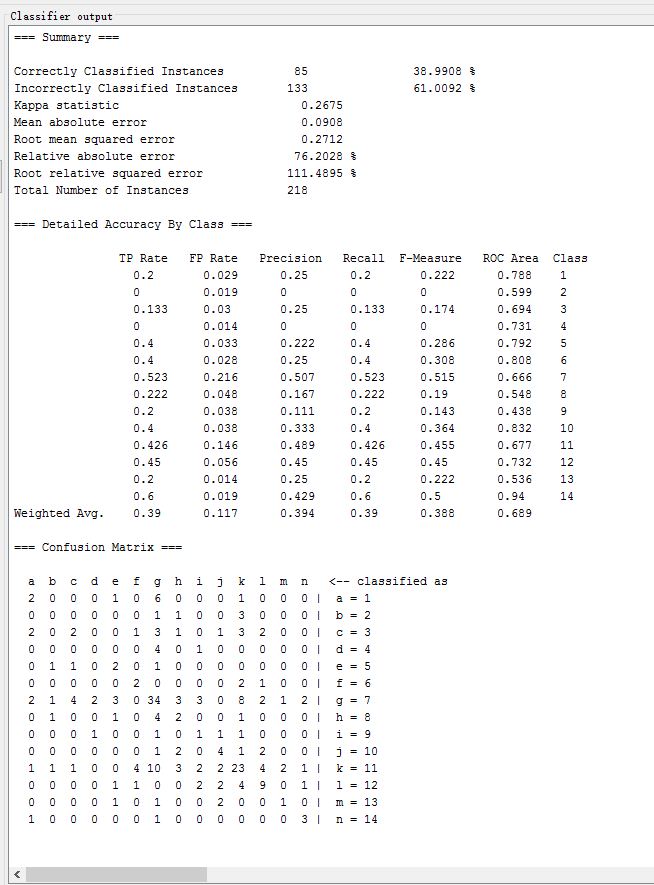
MultilayerPerceptron
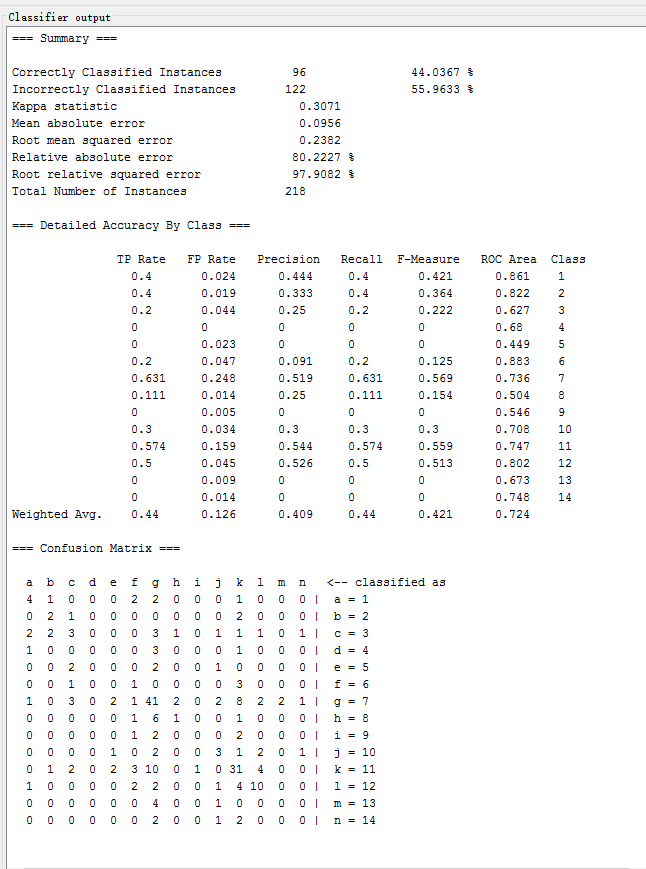
SMO
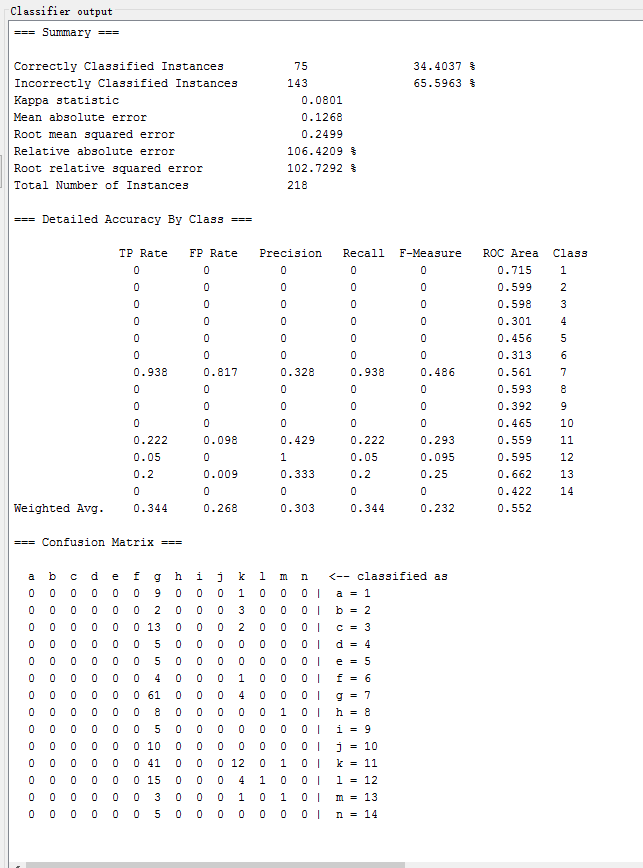
KStar
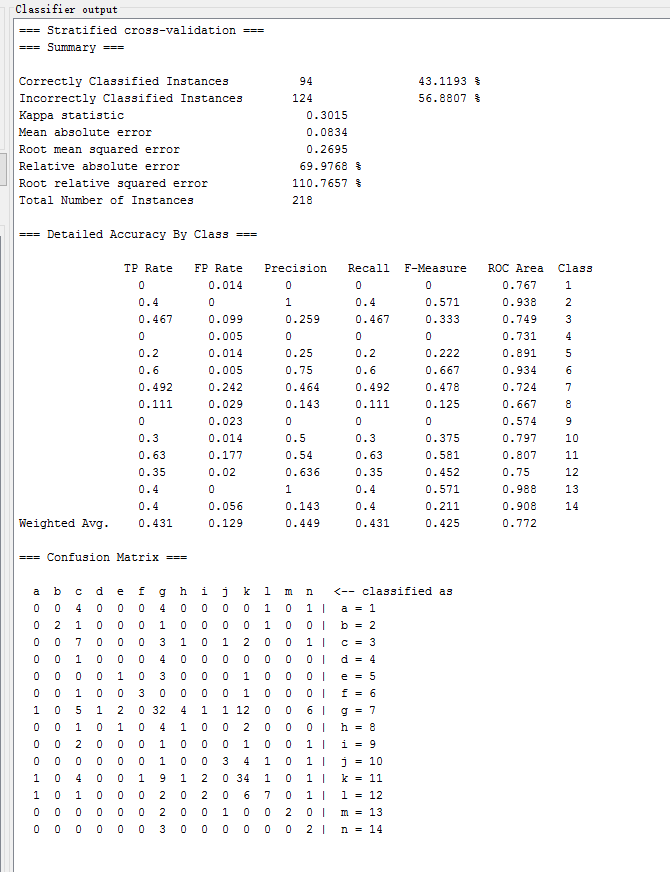
C4.5改进J48
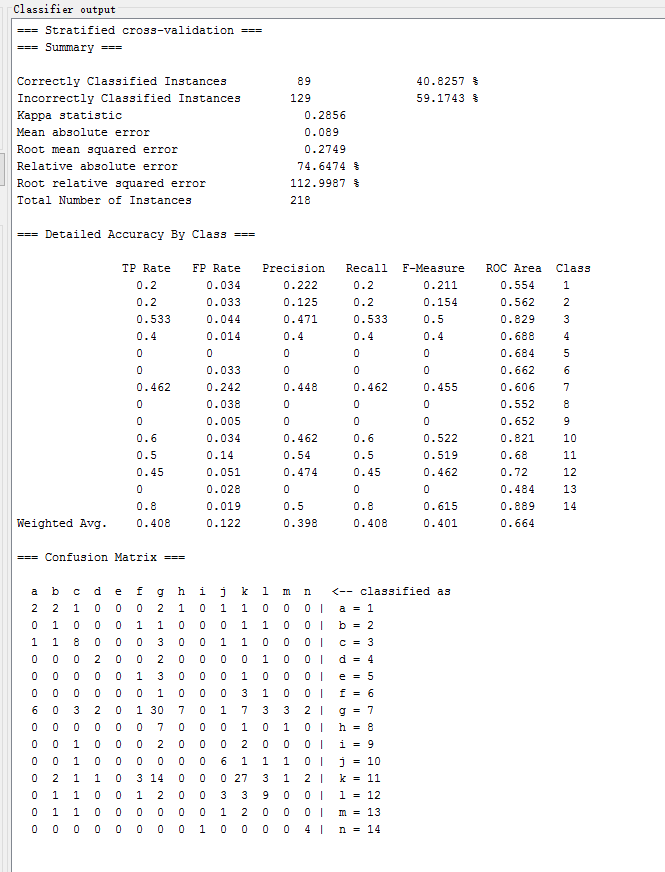
Simple Cart 4.5
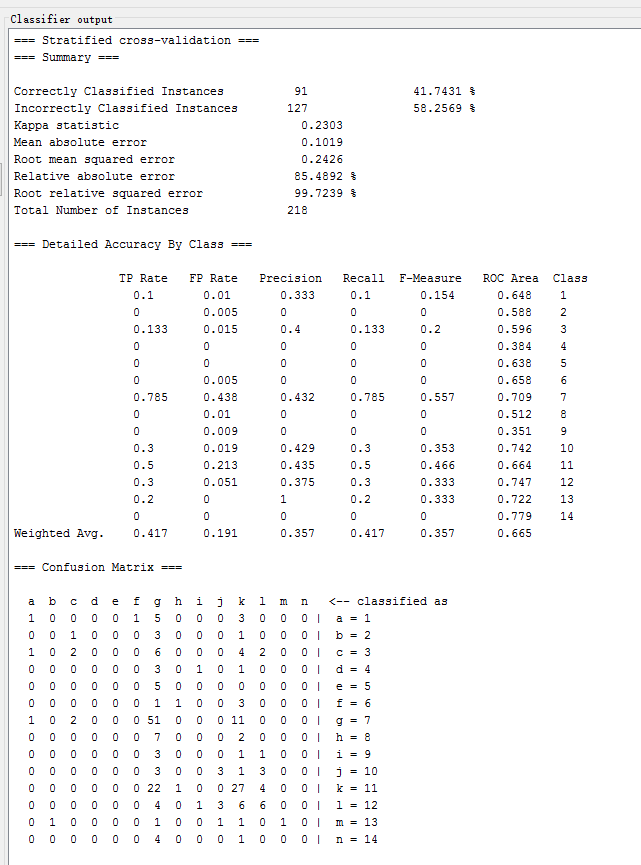
Random Forest SVM
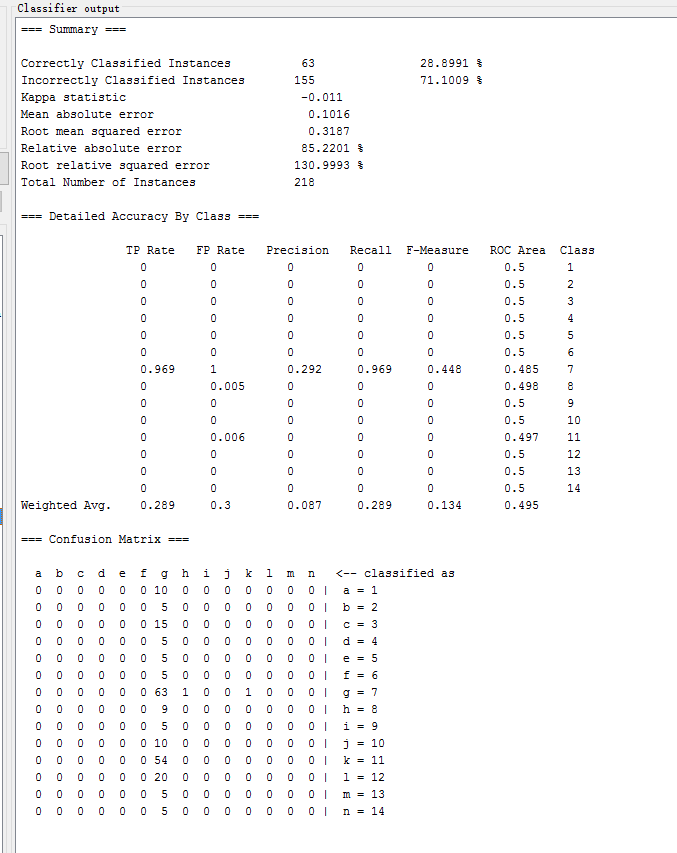
数据集前6个属性是标称属性

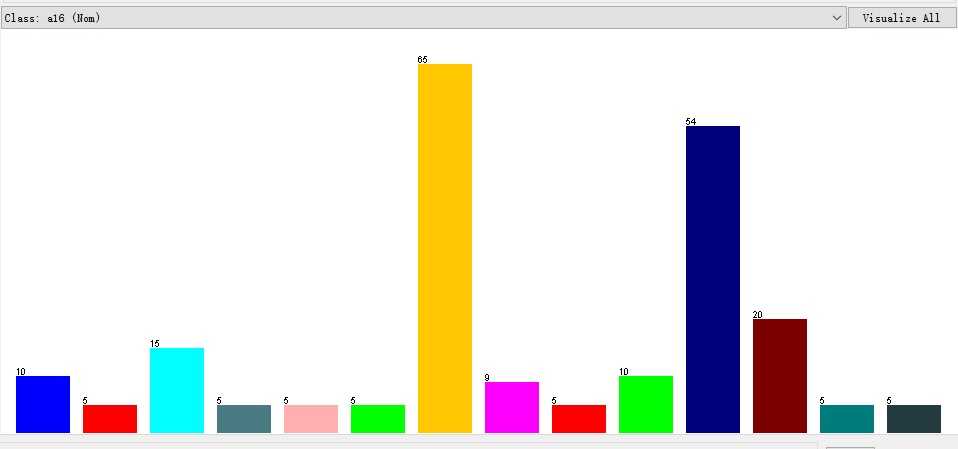
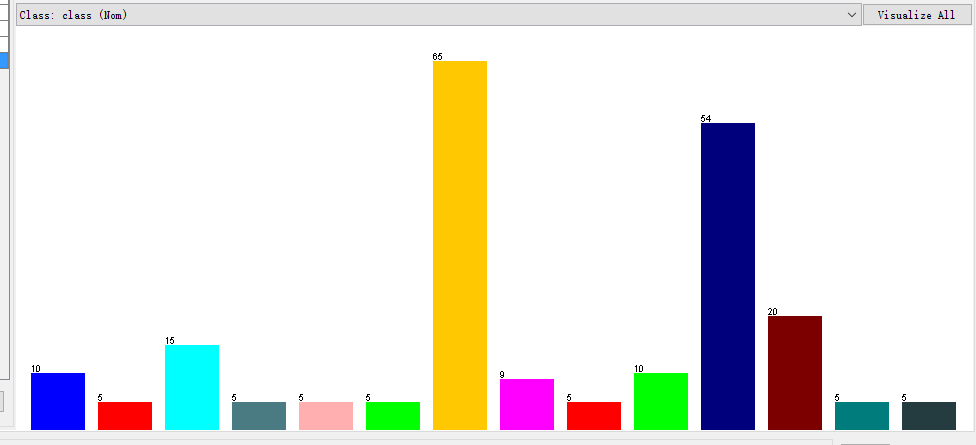
各类数据分布图:
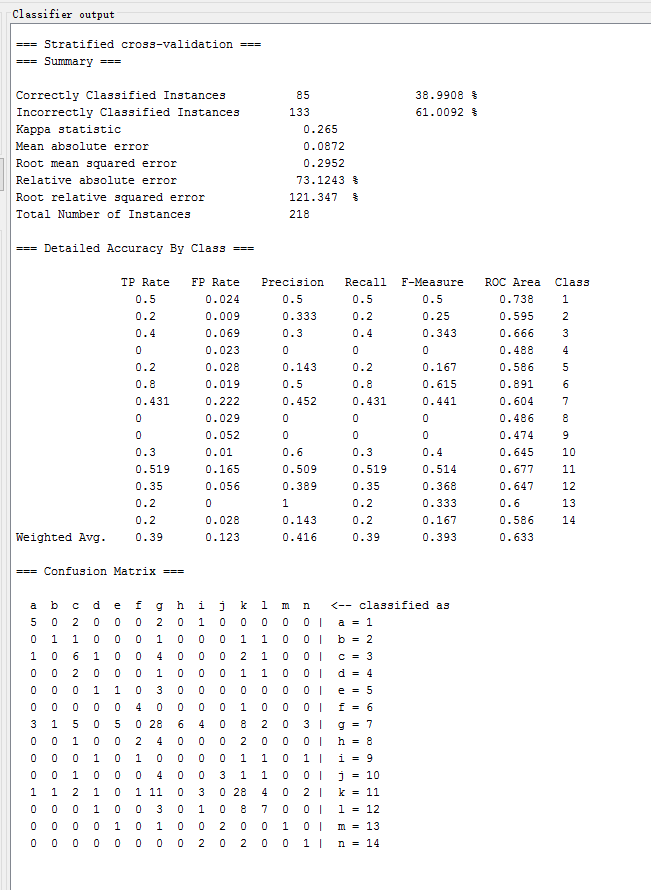
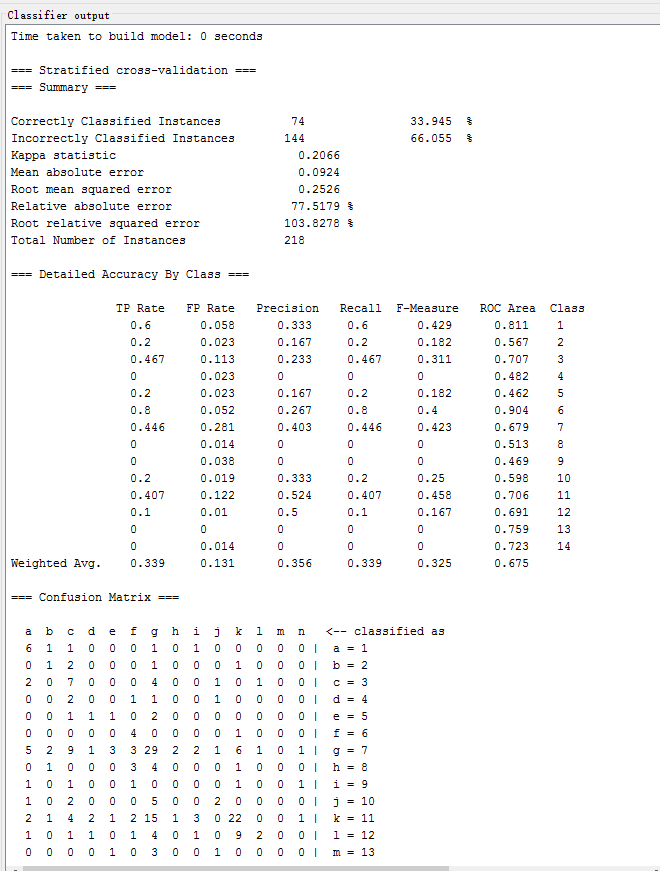
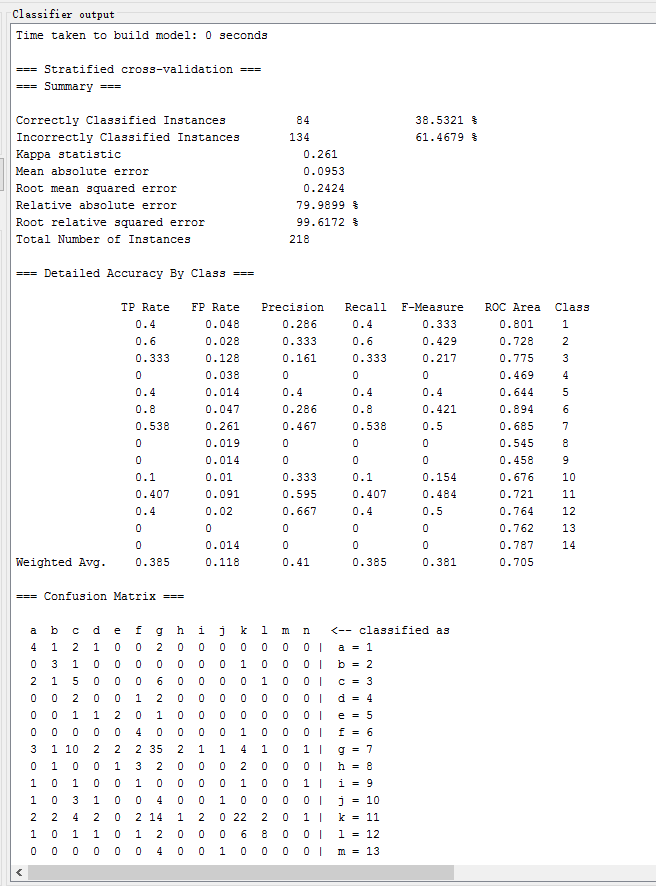
测试以下常用的分类方法,记录各方法的识别正确率、Kappa系数、均方根误差、相对绝对误差如下表所示:
Random Forest
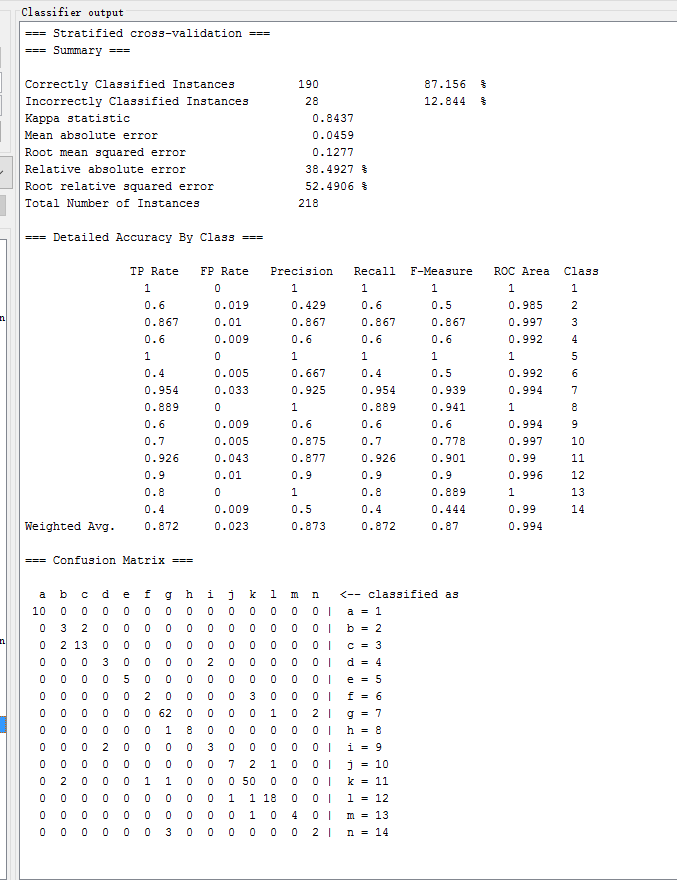
C4.5改进J48
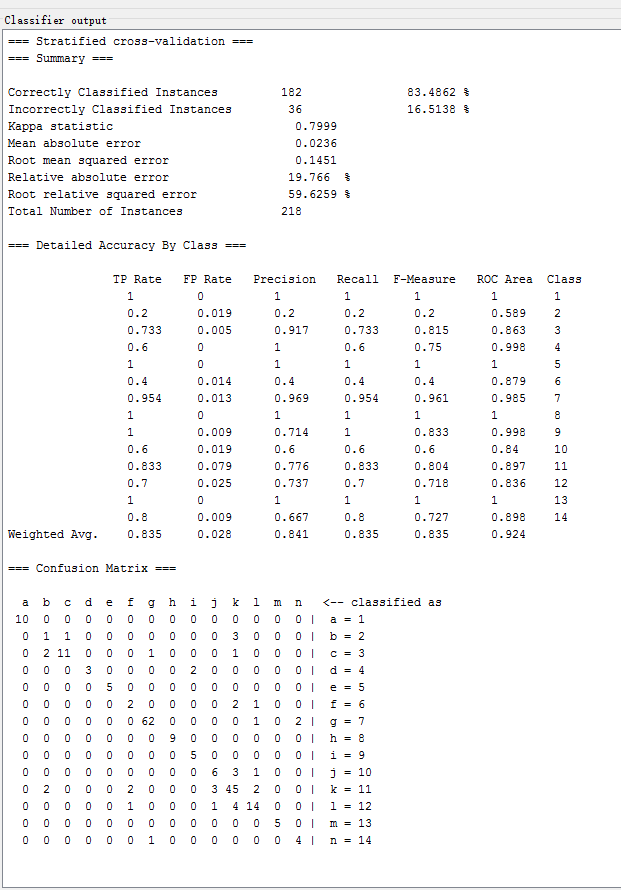
Simple Logistic
NN
Random Forest、Multiple Layer Perceptron、C4.5、Simple Logistic 等算法的分类效果最好。
1. 数值型数据在weka 平台上
数值型数据分布
横坐标代表类别数,一共有14类数据,纵坐标代表每类数据的样本个数分布。在weka中采用多种传统分类方法实验结果
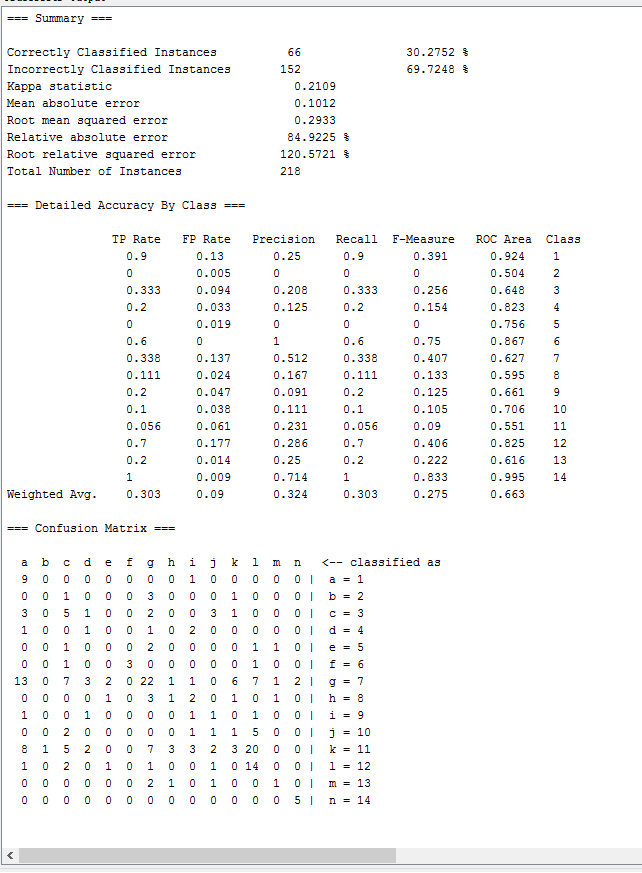
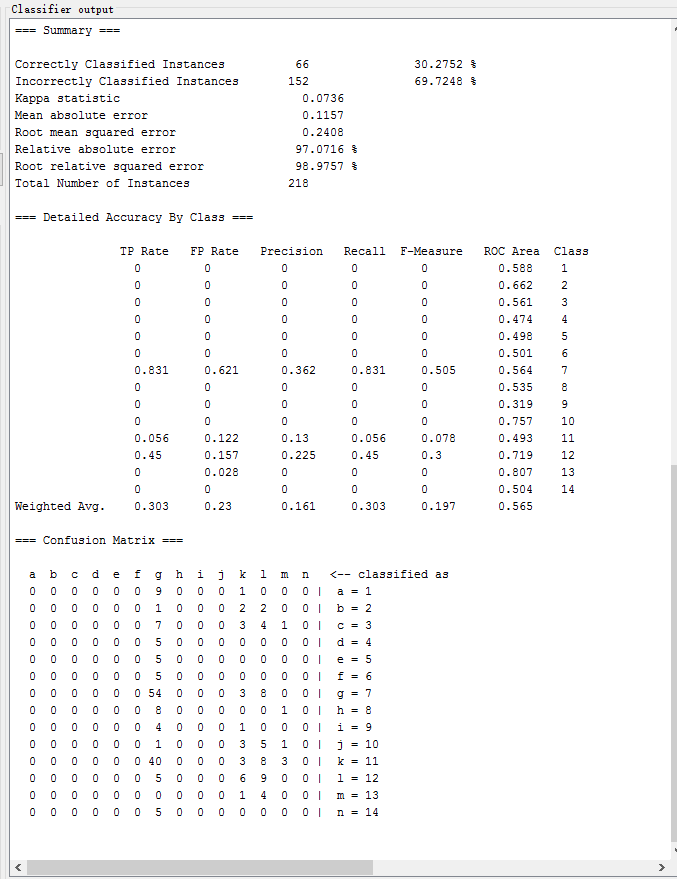
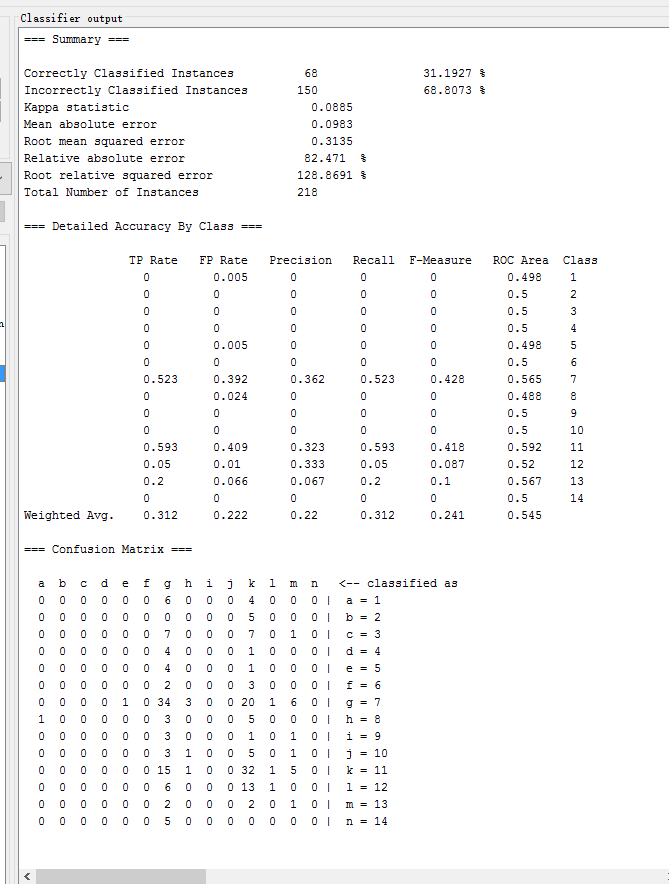
在weka中测试以下常用的分类方法,记录各方法的识别正确率、Kappa系数、均方根误差、相对绝对误差如下表所示:| 方法名 | weka中对应方法 | Correctly Classified rate | Kappa 系数 | Root mean square error | Relative absolute error |
|---|---|---|---|---|---|
| NN | lazy.IB1 | 38.9908 % | 0.265 | 0.2952 | 73.1243 % |
| 2-NN | lazy.IBk(k=2) | 33.945 % | 0.2066 | 0.2526 | 77.5179 % |
| 3-NN | lazy.IBk(k=3) | 38.5321 % | 0.261 | 0.2424 | 79.9899 % |
| Naive Bayes | bayes.NaiveBayes | 30.2752 % | 0.2109 | 0.2933 | 84.9225 % |
| Bayes Net | bayes.BayesNet | 30.2752 % | 0.0736 | 0.2408 | 97.0716 % |
| Complement Naive Bayes | bayes.ComplementNaiveBayes | 31.1927 % | 0.0885 | 0.3135 | 82.471 % |
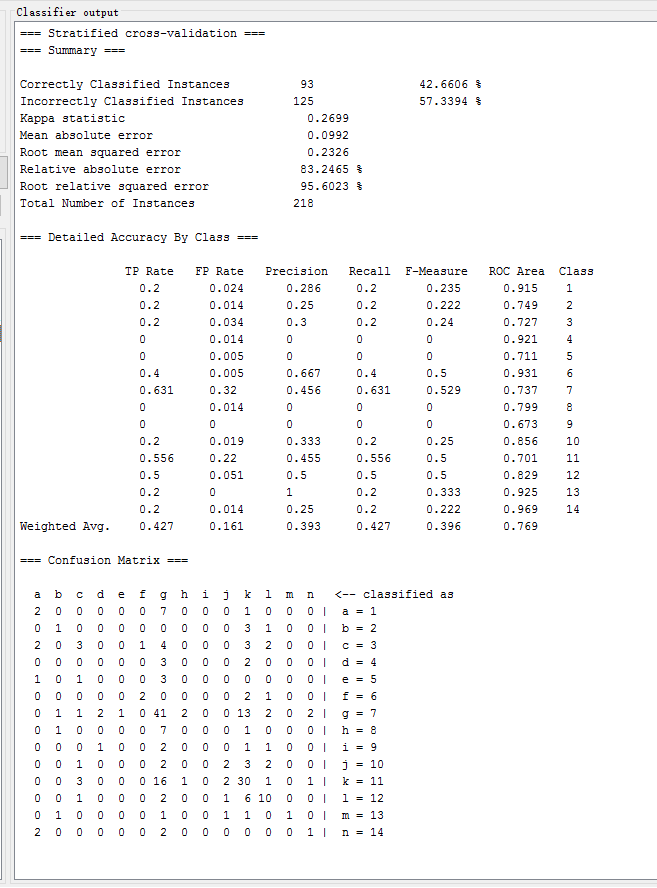
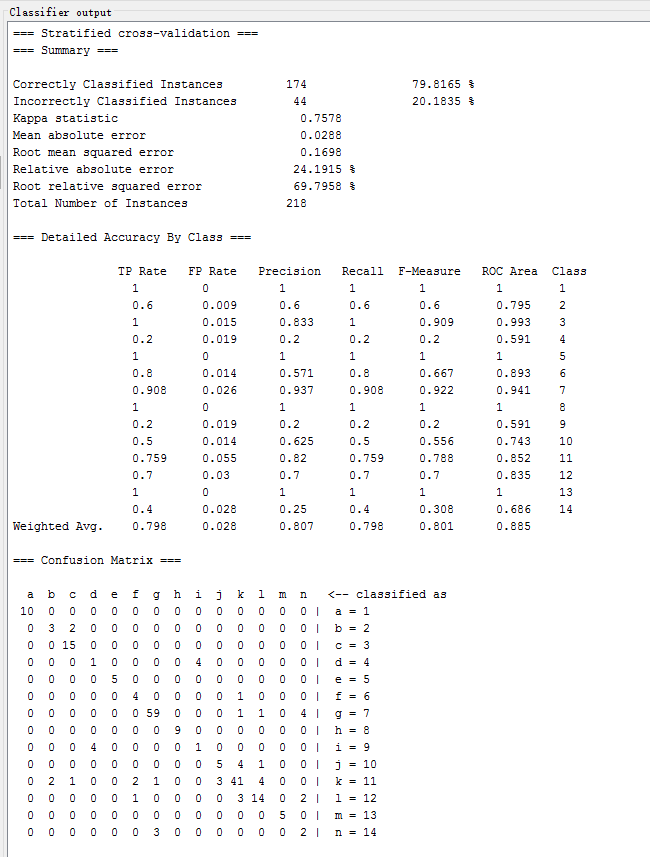
| Simple Logistic | functions.SimpleLogistic | 42.6606 % | 0.2699 | 0.2326 | 83.2465 % |
| Logistic | functions.Logistic | 38.9908 % | 0.2675 | 0.2712 | 76.2028 % |
| MultilayerPerceptron | functions.MultilayerPerceptron | 44.0367 % | 0.3071 | 0.2382 | 80.2227 % |
| SMO | functions.SMO | 34.4037 % | 0.0801 | 0.2499 | 106.4209 % |
| KStar | lazy.KStar | 43.1193 % | 0.3015 | 0.2695 | 69.9768 % |
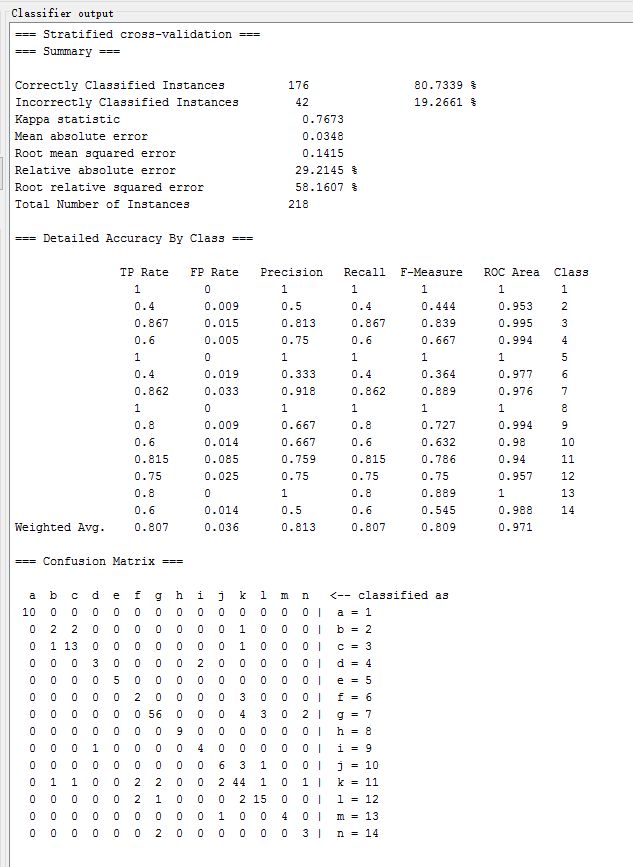
| C4.5改进J48 | trees.J48 | 40.8257 % | 0.2856 | 0.2749 | 74.6474 % |
| Simple Cart 4.5 | trees.SimpleCart | 41.7431 % | 0.2303 | 0.2426 | 85.4892 % |
| Random Forest | trees.RandomForest | 55.0459 % | 0.4149 | 0.2111 | 80.833 % |
| SVM | functions.LibSVM | 28.8991 % | -0.011 | 0.3187 | 85.2201 % |
各方法结果
最近邻算法NN2-NN
3-NN
Naive Bayes
Bayes Net
Complement Naive Bayes
Simple Logistic
Logistic
MultilayerPerceptron
SMO
KStar
C4.5改进J48
Simple Cart 4.5
Random Forest SVM
2 添加标称性数据后实验结果
在原始数值性数据基础上添加非数值属性,同样在weka常用分类方法上检测实验结果数据集前6个属性是标称属性
各类数据分布图:
测试以下常用的分类方法,记录各方法的识别正确率、Kappa系数、均方根误差、相对绝对误差如下表所示:
| 方法名 | weka中对应方法 | Correctly Classified rate | Kappa 系数 | Root mean square error | Relative absolute error |
|---|---|---|---|---|---|
| NN | lazy.IB1 | 79.8165 % | 0.7578 | 0.1698 | 24.1915 % |
| 2-NN | lazy.IBk(k=2) | 76.6055 % | 0.7171 | 0.149 | 29.5295 % |
| 3-NN | lazy.IBk(k=3) | 79.3578 % | 0.7508 | 0.1443 | 31.0323 % |
| Naive Bayes | bayes.NaiveBayes | 45.4128 % | 0.3789 | 0.2647 | 67.4257 % |
| Bayes Net | bayes.BayesNet | 58.7156 % | 0.5219 | 0.2031 | 51.7458 % |
| Simple Logistic | functions.SimpleLogistic | 80.7339 % | 0.7673 | 0.1415 | 29.2145 % |
| Logistic | functions.Logistic | 70.1835 % | 0.6432 | 0.2018 | 35.2254 % |
| MultilayerPerceptron | functions.MultilayerPerceptron | 75.6881 % | 0.7034 | 0.1597 | 34.4279 % |
| SMO | functions.SMO | 72.4771 % | 0.6547 | 0.2424 | 103.3214 % |
| KStar | lazy.KStar | 57.3394 % | 0.479 | 0.2337 | 51.3496 % |
| C4.5改进J48 | trees.J48 | 83.4862 % | 0.7999 | 0.1451 | 74.6474 % |
| Simple Cart 4.5 | trees.SimpleCart | 74.7706 % | 0.6937 | 0.1743 | 33.9928 % |
| Random Forest | trees.RandomForest | 87.156 % | 0.8437 | 0.1277 | 38.4927 % |
| SVM | functions.LibSVM | 28.8991 % | -0.011 | 0.3187 | 85.2201 % |
C4.5改进J48
Simple Logistic
NN
总结
针对实验一和实验二中的数据结果,我们可以知道,添加标称属性后实验整体的准确度都大幅提高了很多。Random Forest、Multiple Layer Perceptron、C4.5、Simple Logistic 等算法的分类效果最好。

相关文章推荐
- 源码推荐(01.18B):比较常用的分类界面,实现LOL皮肤选择效果
- 分别用5种分类算法对约会网站匹配效果进行改进,比较评分
- SQL Server 2008 T-SQL编程系列课程之常用查询算法比较
- 常用图像插值算法分析与比较
- Mahout分类算法效果评估指标
- 采用Weka中的KNN算法进行文本分类
- 常用算法复杂度比较
- 分词中常用算法比较与设想
- 模式识别之基础---常用分类算法特性归纳
- 比较常用的算法优化小技巧
- 文本分类算法的效果
- [转]文本分类算法的效果
- 常用图像插值算法分析与比较
- 常用分词算法的比较与设想
- STL中比较常用的容器是vector,set和map,比较常用的算法有Sort等。
- 数据挖掘 - 分类算法比较
- 比较线性网络和非线性网络的分类效果
- 数据挖掘分类算法比较
- Weka -- 分类算法之C4.5
- 浅析常用分词算法的比较与设想