从ACID到CAP/BASE
2017-01-06 00:00
218 查看
接下来会学习一下Zookeeper,在学习Zookeeper之前,还是要介绍一些分布式事务的基础理论知识。
事务的ACID,我们在介绍MySql的时候,已经介绍到了。所以在此就不做介绍了。 然而,随着分布式计算的发展,事务在分布式计算领域中也的到了广泛的应用。在单机数据库中,很容易实现一套满足ACID特性的事务处理,但在分布式数据库中进行事务处理就具有非常大的挑战。
因为分布式环境存在着一下几个问题:
通信异常
网络分区
网络三态
节点故障
ACID理论在单机系统中,已经使用的比较成熟。在分布式系统下,出现了CAP和BASE的理论。
分布式系统无法同时满足上述三个需求,而只能满足其中的两项。
对于一个分布式系统而言,分区容错性可以说是一个最基本的要求。因为分布式系统必然需要部署到不同的节点,必然会出现网络因素。而有
7fe0
网络的地方,必要会出现网络异常情况,因此分区容错性是一个分布式系统必然要面对的问题。因此只能根据业务特点在C(一致性)和A(可用性)之间寻求平衡。
BASE理论面向大型的高可用可扩展的分布式系统,不同于ACID的强一致性,而是通过牺牲强一致性获得可用性,并允许出现一段时间的不一致,但最终会达到一致状态。
然而,在应用过程中,会根据具体的业务场景,选择不同的一致性原理实现。
更多精彩内容,欢迎关注微信公众号:Java小笔记(ijavanote)
事务的ACID,我们在介绍MySql的时候,已经介绍到了。所以在此就不做介绍了。 然而,随着分布式计算的发展,事务在分布式计算领域中也的到了广泛的应用。在单机数据库中,很容易实现一套满足ACID特性的事务处理,但在分布式数据库中进行事务处理就具有非常大的挑战。
因为分布式环境存在着一下几个问题:
通信异常
分布式的过程必然引入网络因素,网络本身的不可靠行,使得问题变得复杂。包括消息的延迟以及消息的丢失等。
网络分区
网络发生异常的情况下,分布式各个节点之间网络延迟不断增大,最终导致只有部分节点之间可以正常通信。这就是通常所说的“脑裂”。这对分布式一致性提出了非常大的挑战。
网络三态
由于网络可能出现各式各样的问题,每一次请求和响应,都会有“三态”——成功、失败与超时。成功与失败,在单机系统中也会出现,在网络异常情况下就会出现超时的现象。而超时可能是没有发送出去,也可能是没有响应回来。
节点故障
这是分布式环境下经常遇到的问题,分布式系统下每个节点宕机,都是有可能的。
ACID理论在单机系统中,已经使用的比较成熟。在分布式系统下,出现了CAP和BASE的理论。
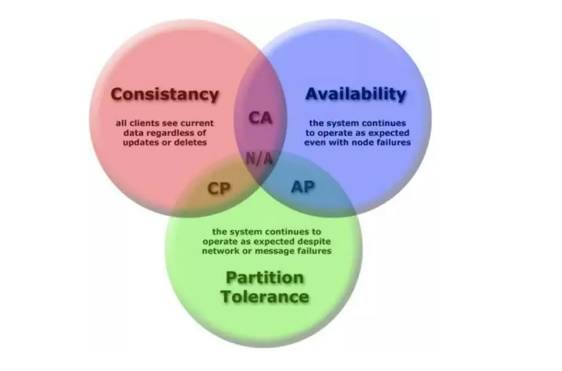
CAP理论
CAP是说,一个分布式系统不可能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三个基本需求,最多只能满足其中的两项。一致性
在分布式环境中,各个分布式节点上的多个副本之间保持一致。如果一个被修改,则所有的都被修改。
可用性
可用性是指系统的服务必须一直处于可用状态,必须对用户的每一次请求,在有效的时间内返回结果。
分区容错性
分布式系统遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务。
分布式系统无法同时满足上述三个需求,而只能满足其中的两项。
1. CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但其实分区不是你想不想的问题,而是始终会存在,因此CA的系统更多的是允许分区后各子系统依然保持CA。 2. CP without A:如果不要求A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。 3. AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
对于一个分布式系统而言,分区容错性可以说是一个最基本的要求。因为分布式系统必然需要部署到不同的节点,必然会出现网络因素。而有
7fe0
网络的地方,必要会出现网络异常情况,因此分区容错性是一个分布式系统必然要面对的问题。因此只能根据业务特点在C(一致性)和A(可用性)之间寻求平衡。
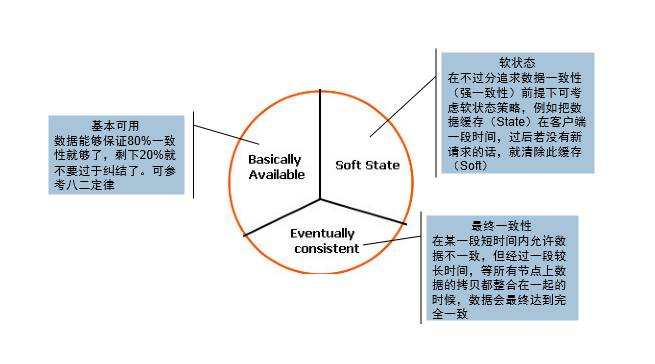
BASE理论
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)的简写。这种理论是建立在无法做到强一致,而是系统达到最终一致。基本可用
系统发生不可预知的故障时,允许损失部分可用性。比如响应时间上增加,功能上的损失。
弱状态
系统中的数据存在中间状态,这个状态不影响系统的可用性,即数据在不同副本之间进行数据同步的过程存在延时。
最终一致性
系统中的所有数据副本,在经过一段时间的同步后,最终能达到一个一致的状态。而不需要实时数据的一致。
BASE理论面向大型的高可用可扩展的分布式系统,不同于ACID的强一致性,而是通过牺牲强一致性获得可用性,并允许出现一段时间的不一致,但最终会达到一致状态。
然而,在应用过程中,会根据具体的业务场景,选择不同的一致性原理实现。
更多精彩内容,欢迎关注微信公众号:Java小笔记(ijavanote)

相关文章推荐
- ACID、Data Replication、CAP与BASE
- ACID、BASE和CAP原理
- CAP原理和BASE思想 ACID模型
- [zz]CAP理论,ACID和BASE
- ACID、Data Replication、CAP与BASE
- 分布式系统开发的一些相关理论基础——CAP、ACID、BASE
- ACID、Data Replication、CAP与BASE
- 分布式:ACID, CAP, BASE
- 分布式事务 ACID CAP BASE
- 分布式服务化系统一致性(分布式事务、ACID、BASE、CAP)原理与解决方案
- 分布式一致性算法(四)分布式事务概述:ACID-CAP-BASE和1PC-2PC-3PC
- 你想了解的分布式--从ACID到CAP/BASE
- ACID、Data Replication、CAP与BASE
- 分布式系列文章——从ACID到CAP/BASE
- CAP BASE ACID
- ACID, BASE和CAP
- 事务原理:ACID,CAP和BASE理论及分布式事务一致性案例
- ACID CAP BASE介绍
- 分布式中 CAP BASE ACID 理解
- Zookeeper 架构学习(一):ACID、Data Replication、CAP与BASE