『阿男的Linux内核世界』*11 Process和Thread的设计*
2017-01-05 10:50
375 查看
『阿男的Linux内核世界』*11 Process和Thread的设计*
阿男给大家在这篇文章里面讲解一下Linux针对Process和Thread的设计。
我们在学习操作系统设计的时候,知道了Process是一种比较"重"的设计:每一个Process都拥有独立的内存空间,独立的生命周期;同时我们知道了Thread是相比较而言比较轻的资源:多个Threads运行在一个Process之内,共享这个Process的内存资源和CPU资源,但是各个Thread可以有自己的代码执行权力,每一个Thead可以运行在不同的代码位置。
其实我们可以看到,Linux的内核发展到今天,对于运行在上面的程序,早已经"虚拟化"了:每一个程序都拥有自以为独立的内存空间,拥有自以为独立的CPU资源,而操作系统负责管理实际的硬件资源,然后把这些资源分配给各个Processes,并且负责调度这些Processes的执行顺序并且管理它们的运行状态。
在Process和Thread的实现方面,Linux Kernel并没有做过多区分,而是用统一的
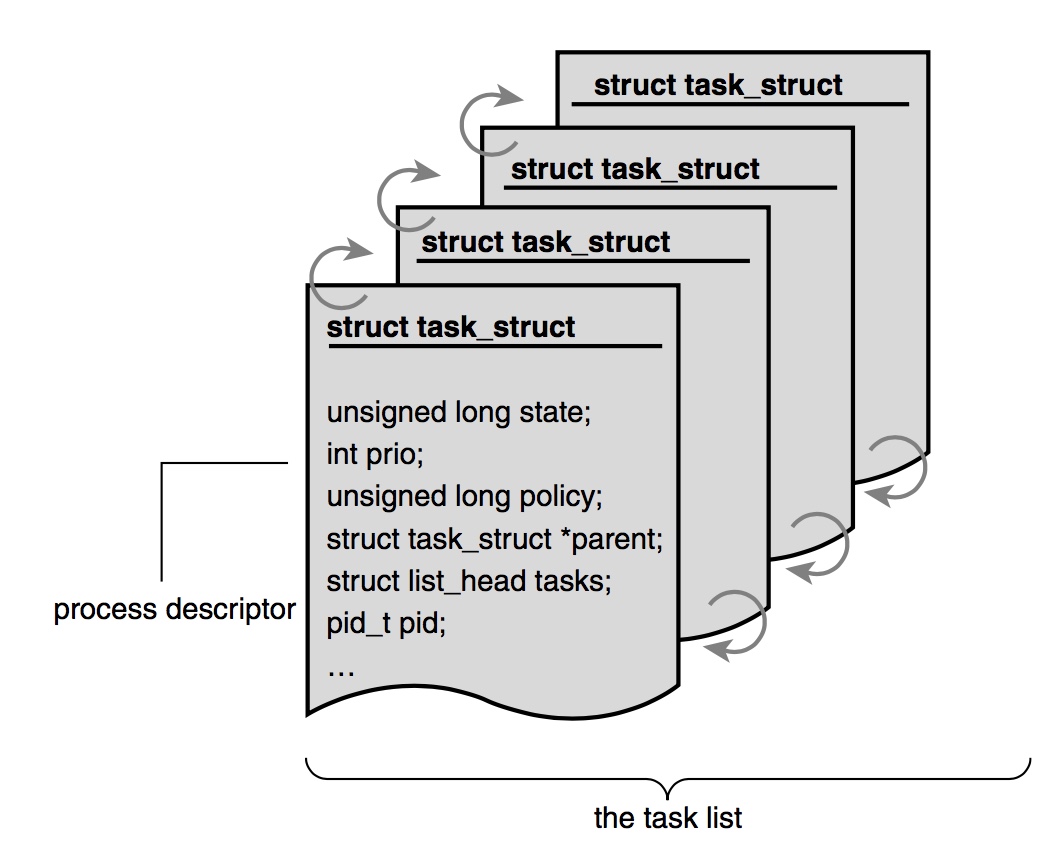
(图片来自
上面是这个
上面包含了这个
此外,
为什么在Linux Kernel里面,Thread和Process共用一个
此时,Kernel只需要在
实际上Linux Kernel可以支持定义的

通过上面各种flag的组合,我们可以微调各种创建出来的
从上面的代码可以看到,
但是新的Linux Kernel早已经对
下面是
可以看到也是调用
最后我们看创建thread所用的system call
而clone实际上也是
注意最新版的Linix内核代码中,这些地方的实现细节有所变化,但是整体设计并未改变。这些细节阿男后续会为大家再慢慢讲,我们目前要学习的是设计思想。
阿男给大家在这篇文章里面讲解一下Linux针对Process和Thread的设计。
我们在学习操作系统设计的时候,知道了Process是一种比较"重"的设计:每一个Process都拥有独立的内存空间,独立的生命周期;同时我们知道了Thread是相比较而言比较轻的资源:多个Threads运行在一个Process之内,共享这个Process的内存资源和CPU资源,但是各个Thread可以有自己的代码执行权力,每一个Thead可以运行在不同的代码位置。
其实我们可以看到,Linux的内核发展到今天,对于运行在上面的程序,早已经"虚拟化"了:每一个程序都拥有自以为独立的内存空间,拥有自以为独立的CPU资源,而操作系统负责管理实际的硬件资源,然后把这些资源分配给各个Processes,并且负责调度这些Processes的执行顺序并且管理它们的运行状态。
在Process和Thread的实现方面,Linux Kernel并没有做过多区分,而是用统一的
task_struct来描述:
(图片来自
Linux Kernel Development)
task_struct的定义位于
include/linux/sched.h^1,阿男在注解里给出了链接,大家可以自行查看一下。可以看到这个struct里面的内容非常丰富,包含了process方方面面的信息,比如:
1274/* signal handlers */ 1275 struct signal_struct *signal; 1276 struct sighand_struct *sighand;
上面是这个
task_struct所包含的signal handler信息。还有:
1174/* task state */ 1176 int exit_state; 1177 int exit_code, exit_signal; 1184 pid_t pid; 1185 pid_t tgid; 1186
上面包含了这个
task_struct的很多状态信息,比如
exit_code,还有
pid,这些我们比较熟悉的内容。
此外,
task_struct之间的继承关系的信息当然也会有:
1189 1190 /* 1191 * pointers to (original) parent process, youngest child, younger sibling, 1192 * older sibling, respectively. (p->father can be replaced with 1193 * p->real_parent->pid) 1194 */ 1195 struct task_struct *real_parent; /* real parent process */ 1196 struct task_struct *parent; /* recipient of SIGCHLD, wait4() reports */ 1197 /* 1198 * children/sibling forms the list of my natural children 1199 */ 1200 struct list_head children; /* list of my children */ 1201 struct list_head sibling; /* linkage in my parent's children list */ 1202 struct task_struct *group_leader; /* threadgroup leader */
为什么在Linux Kernel里面,Thread和Process共用一个
task_struct呢?阿男觉得这样的设计是非常好的,因为Thread和Process的区别本来就没有那么大,只不过很多时候可能Thread就是一个"更轻"的Process,不具有Process那么多的独立信息。因此Thread可能只需要用到一部分
task_struct里面的元素就好,但没有必要为了Thread定义一个重复的struct。
此时,Kernel只需要在
task_struct里面通过flag来区分一下这个
task_struct对应的是Process和Thread就好,然后就可以针对不同的情况作不同的管理。
实际上Linux Kernel可以支持定义的
task远远要比Process和Thread这两种概念的颗粒度要更细。大家可以看一下
sched.h在一开始的各种flag定义[2]:
通过上面各种flag的组合,我们可以微调各种创建出来的
task,这些
task在资源使用方面的区别远远要比Process和Thread更细致。比如
vfork()函数,其实就是通过这些flag的组合来创建一个
task_struct^3:
249 */
250 int sys_vfork(struct pt_regs *regs)
251 {
252 return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, regs->sp, regs, 0,
253 NULL, NULL);
254 }从上面的代码可以看到,
vfork就是
sys_vfork的wrapper,而
sys_vfork则是调用
do_fork,传递的flag是
CLONE_VFORK | CLONE_VM | SIGCHLD。
vfork其实是一个已经没什么太大意义的函数,它的历史作用是创建一个新的process但是不拷贝caller process的内存空间,这个函数是为了child process执行
exec()函数让自己执行全新的程序而用,这样的情况下拷贝parent process的内存空间就毫无意义了。
但是新的Linux Kernel早已经对
do_fork的实现做了大量优化,使用了copy-on-write技术,也就是说你就算调用
fork()函数,新建立的process也不会马上拷贝parent的内存空间。
下面是
fork的系统调用
sys_fork的代码:
235 int sys_fork(struct pt_regs *regs)
236 {
237 return do_fork(SIGCHLD, regs->sp, regs, 0, NULL, NULL);
238 }可以看到也是调用
do_fork,只是传递的参数不太一样。至于
do_fork内部怎么处理,那就是Kernel的事情,阿男刚才说过,实际上
sys_vfork和
sys_fork所做的事情已经没什么太大区别。
最后我们看创建thread所用的system call
clone,实际上也是通过不同的flag来定制
task_struct:
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0);
而clone实际上也是
do_fork()的一个wrapper。
注意最新版的Linix内核代码中,这些地方的实现细节有所变化,但是整体设计并未改变。这些细节阿男后续会为大家再慢慢讲,我们目前要学习的是设计思想。

相关文章推荐
- Linux程式设计-11.Shell Script(bash)--(5)控制圈for
- 设计模式(11)-装饰模式(Decorator)
- [FxCop.设计规则]11. 不应该使用默认参数
- 设计模式(11)-单例模式(Flyweight)
- 面向对象设计的11原则
- 面向对象设计的11原则
- COM 组件设计与应用11 - IDispatch 及双接口的调用
- C#设计模式(11)-Composite Pattern
- 面向对象设计的11原则--你称得上OO专家么?
- Jexi设计 (11) Sequence Diagram
- 复习进程和线程 process vs thread
- 2005 1 26 process And threAd
- [FxCop.设计规则]11. 不应该使用默认参数
- js-网页设计技巧11则
- Linux程式设计-11.Shell Script(bash)--(1)简介
- Linux程式设计-11.Shell Script(bash)--(3)用於自动备份的Shell Script
- Linux程式设计-11.Shell Script(bash)--(7)流程控制select
- 设计模式笔记(11 OBSERVER & STATE)
- 面向对象设计的11原则
- MATLAB程序设计教程(11)——MATLAB图形用户界面设计