深度优先算法和广度优先算法
2017-01-05 07:37
176 查看
算法:深度优先算法和广度优先算法(基于邻接矩阵)
1.写在前面
图的存储结构有两种:一种是基于二维数组的邻接矩阵表示法。另一种是基于链表的的邻接表。
在邻接矩阵中,可以如下表示顶点和边连接关系:

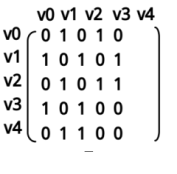
说明:
将顶点对应为下标,根据横纵坐标将矩阵中的某一位置值设为1,表示两个顶点向联接。
图示表示的是无向图的邻接矩阵,从中我们可以发现它们的分布关于斜对角线对称。
我们在下面将要讨论的是下图的两种遍历方法(基于矩阵的):
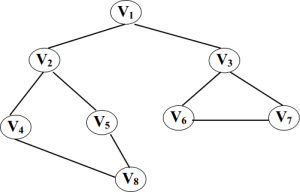
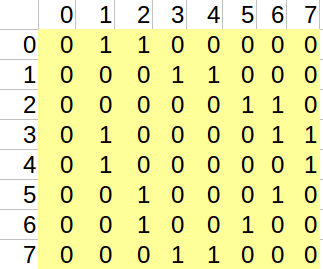
我们已经说明了我们要用到的是邻接矩阵表示法,那么我首先要来构造图:
矩阵图的数据结构如下表示:
#define MaxVnum 50
typedef double AdjMatrix[MaxVnum][MaxVnum]; //表示一个矩阵,用来存储顶点和边连接关系
typedef struct {
int vexnum,arcnum; //顶点的个数,边的个数
AdjMatrix arcs; //图的邻接矩阵
}Graph;这样我们可以首先来创建上述图,为了方便,我们直接在代码中书写矩阵,而不用每次调试手动输入了
void CreateGraph(Graph &G)
{
G.vexnum=8;
G.arcnum=9;
G.arcs[0][1]=1;
G.arcs[0][2]=1;
G.arcs[1][3]=1;
G.arcs[1][4]=1;
G.arcs[2][5]=1;
G.arcs[2][6]=1;
G.arcs[3][1]=1;
G.arcs[3][7]=1;
G.arcs[3][6]=1;
G.arcs[4][1]=1;
G.arcs[4][7]=1;
G.arcs[5][2]=1;
G.arcs[5][6]=1;
G.arcs[5][5]=1;
G.arcs[6][2]=1;
G.arcs[6][5]=1;
G.arcs[7][3]=1;
G.arcs[7][4]=1;
}这样我们就已经完成了准备工作,我们可以正式来学习我们的两种遍历方式了。
2.深度优先遍历算法
分析深度优先遍历
从图的某个顶点出发,访问图中的所有顶点,且使每个顶点仅被访问一次。这一过程叫做图的遍历。深度优先搜索的思想:
①访问顶点v;
②依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
③若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。
比如:
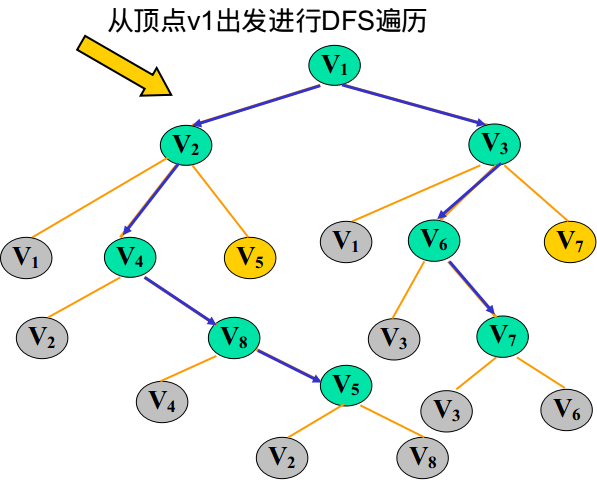
在这里为了区分已经访问过的节点和没有访问过的节点,我们引入一个一维数组bool visited[MaxVnum]用来表示与下标对应的顶点是否被访问过,
流程:
☐ 首先输出 V1,标记V1的flag=true;
☐ 获得V1的邻接边 [V2 V3],取出V2,标记V2的flag=true;
☐ 获得V2的邻接边[V1 V4 V5],过滤掉已经flag的,取出V4,标记V4的flag=true;
☐ 获得V4的邻接边[V2 V8],过滤掉已经flag的,取出V8,标记V8的flag=true;
☐ 获得V8的邻接边[V4 V5],过滤掉已经flag的,取出V5,标记V5的flag=true;
☐ 此时发现V5的所有邻接边都已经被flag了,所以需要回溯。(左边黑色虚线,回溯到V1,回溯就是下层递归结束往回返)
☐
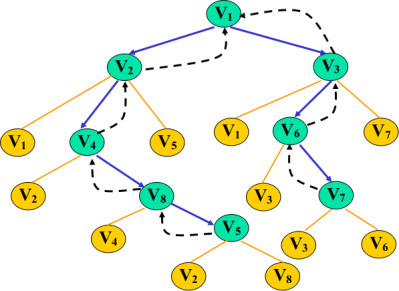
☐ 回溯到V1,在前面取出的是V2,现在取出V3,标记V3的flag=true;
☐ 获得V3的邻接边[V1 V6 V7],过滤掉已经flag的,取出V6,标记V6的flag=true;
☐ 获得V6的邻接边[V3 V7],过滤掉已经flag的,取出V7,标记V7的flag=true;
☐ 此时发现V7的所有邻接边都已经被flag了,所以需要回溯。(右边黑色虚线,回溯到V1,回溯就是下层递归结束往回返)
深度优先搜索的代码
bool visited[MaxVnum];
void DFS(Graph G,int v)
{
visited[v]= true; //从V开始访问,flag它
printf("%d",v); //打印出V
for(int j=0;j<G.vexnum;j++)
if(G.arcs[v][j]==1&&visited[j]== false) //这里可以获得V未访问过的邻接点
DFS(G,j); //递归调用,如果所有节点都被访问过,就回溯,而不再调用这里的DFS
}
void DFSTraverse(Graph G) {
for (int v = 0; v < G.vexnum; v++)
visited[v] = false; //刚开始都没有被访问过
for (int v = 0; v < G.vexnum; ++v)
if (visited[v] == false) //从没有访问过的第一个元素来遍历图
DFS(G, v);
}3.广度优先搜索算法
分析广度优先遍历
所谓广度,就是一层一层的,向下遍历,层层堵截,还是这幅图,我们如果要是广度优先遍历的话,我们的结果是V1 V2 V3 V4 V5 V6 V7 V8。广度优先搜索的思想:
① 访问顶点vi ;
② 访问vi 的所有未被访问的邻接点w1 ,w2 , …wk ;
③ 依次从这些邻接点(在步骤②中访问的顶点)出发,访问它们的所有未被访问的邻接点; 依此类推,直到图中所有访问过的顶点的邻接点都被访问;
说明:
为实现③,需要保存在步骤②中访问的顶点,而且访问这些顶点的邻接点的顺序为:先保存的顶点,其邻接点先被访问。 这里我们就想到了用标准模板库中的queue队列来实现这种先进现出的服务。
老规矩我们还是走一边流程:
说明:
☐将V1加入队列,取出V1,并标记为true(即已经访问),将其邻接点加进入队列,则 <—[V2 V3]
☐取出V2,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V3 V4 V5]
☐取出V3,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V4 V5 V6 V7]
☐取出V4,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V5 V6 V7 V8]
☐取出V5,并标记为true(即已经访问),因为其邻接点已经加入队列,则 <—[V6 V7 V8]
☐取出V6,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V7 V8]
☐取出V7,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V8]
☐取出V8,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[]
广度优先搜索的代码
#include <queue>
using namespace std;
....
void BFSTraverse(Graph G)
{
for (int v=0;v<G.vexnum;v++) //先将其所有顶点都设为未访问状态
visited[v]=false;
queue<int> Q;
for(int v=0;v<G.vexnum;v++)
{
if(visited[v]==false) //若该点没有访问
{
Q.push(v); //将其加入到队列中
visited[v]=true;
while (!Q.empty()) //只要队列不空,遍历就没有结束
{
int t =Q.front(); //取出对头元素
Q.pop();
printf(" %d ",t+1);
for(int j=0;j<G.vexnum;j++) //将其未访问过的邻接点加进入队列
if(G.arcs[t][j]==1&&visited[j]== false)
{
Q.push(j);
visited[j]=true; //在这里要设置true,因为这里该顶点我们已经加入到了队列,为了防止重复加入!
}
}
}
}
}两种算法的复杂度分析
深度优先数组表示:查找所有顶点的所有邻接点所需时间为O(n2),n为顶点数,算法时间复杂度为O(n2)
广度优先
数组表示:查找每个顶点的邻接点所需时间为O(n2),n为顶点数,算法的时间复杂度为O(n2)
分类: C/C++,数据结构,算法第四版

相关文章推荐
- LeetCode266. Palindrome Permutation
- C++11之动态类型引入(影响面广)
- oracle--知识点汇总2---laobai
- 将netbeans界面语言设置为英文
- 将netbeans界面语言设置为英文
- 关于 mysqladmin
- java常用单词
- Leetcode-455. Assign Cookies
- 网上学习编程的七个趋势
- 反汇编分析__stdcall和__cdecl的异同
- android_39_跳转至第2个Activity
- VS2013编译Qt5.6.0静态库,并提供了百度云下载(乌合之众)good
- 在Windows 环境下编译Qt静态库(QT5.32)
- AI方向
- Linux下编译静态MinGW环境,编译windows平台Qt程序(使用MXE)
- win环境下,用虚拟化工具打包Qt动态编译exe的过程(使用Enigma Virtual Box)
- 三维数组的计算方法
- 记录下 QT Linux 静态编译遇到的坑
- Erlang 实现互斥量
- sql