网络程序设计课程总结
2017-01-03 01:39
232 查看
ustc se SA16225133 寇亚飞
课程目标
课程安排
commitpr
项目地址
关于A1a
关于A2
关于A3
其他方面的一些学习
课程心得
A2 血常规检验报告的图像OCR识别
A3 根据血常规检验的各项数据预测年龄和性别
- 提交了imgproc.py文件,对剪裁好的图片进行OCR识别,最终用在了项目中。

- 分享了开源ocr识别库,tesseract。
主项目地址:聚集了大家的智慧,有多种不同实现,同时有项目所需环境的安装及配置
我fork的分支地址:我自己的一些实现
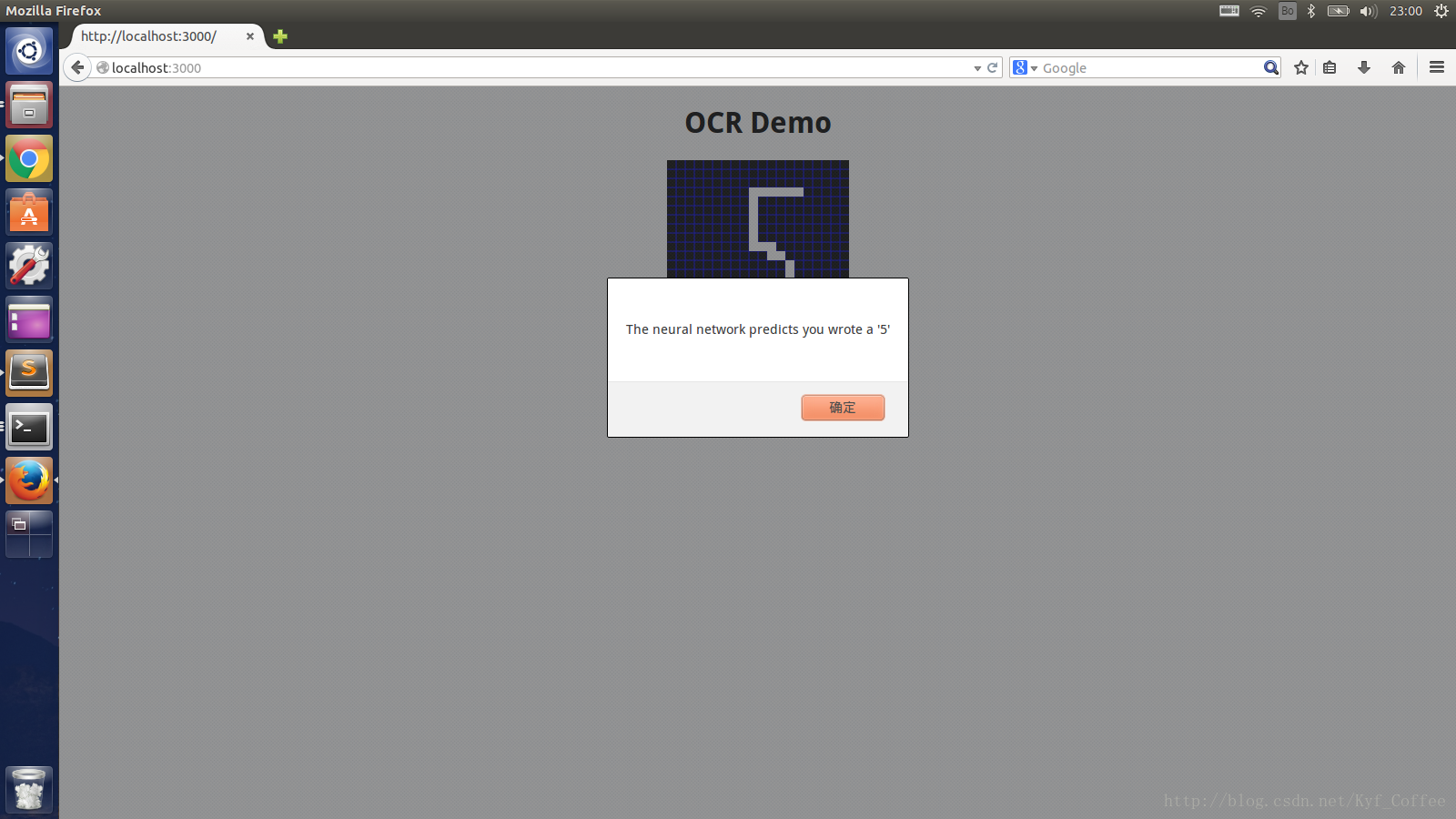
在该项目中,我使用深度学习框架keras实现了手写字符的识别,集成到了web系统中,这里有使用说明。
效果图:
对于图像剪裁,在处理过程中的整理思路非常明确,我们并没有将目标定位于完全适用各种血常规报告单。因此将我们所采用的报告单的图片格式作为识别标准,通过对图片的预处理,包括灰度化、模糊、开闭运算等等,然后重点根据图片的特征,即图中的三条基准线,对图片进行水平方向上的梯度检测,然后根据检测出的线的位置,逐步确定表头表尾,最终就很容易实现了剪裁。这部分的细节在这位同学的PPT中介绍的很清楚,这里就不多余赘述。看一下实现的效果。
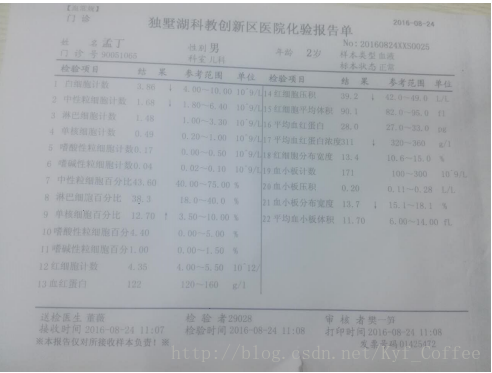
这是原始图片
描绘出边缘

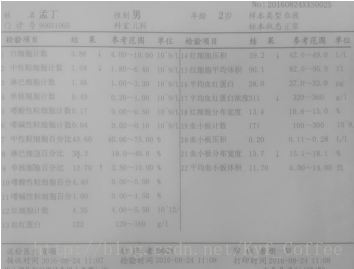
在确定表头和表尾后对图片进行透视投影变换,得到最终要剪切的标准图片
我在项目中的主要贡献就在接下来的OCR部分。讲一下我的主要思路。首先对于剪裁后的图片,如

参考Tesseract官方给出的提高识别率的方法。
对图片进行二值化处理,这里我使用了ostu算法对图像进行二值化处理,它是一种高效的二值化算法,可以参考wiki里关于算法的详细介绍。
为了处理图片中的噪声点,对图片进行了腐蚀操作
将图片放大,Tesseract对于较大的图片有较好的识别结果
再次腐蚀被放大的噪声点
膨胀使图片内容饱满便于识别
直方图均衡化,提高图片的对比度
中值滤波去除孤立的噪声点
经过以上步骤的处理,同时在Tesseract配置文件中加入了适合我们识别项目的白名单,Tesseract能够很好的工作,加上后期对识别结果的字符串操作,识别结果基本满意。以下是上述操作的代码实现:
A2部分接下来的工作就是搭建web系统,将上述一系列剪裁、识别等实现放在web页面中展示,并将结果存入mongoDB中。
在这部分,使用了python的Flask框架,它是一个轻量级的web框架。数据的具体流程是启动服务器,连接到mongo数据库,前台接受图片,执行矫正、识别操作,调用相应模块,将结果存入mongodb中。
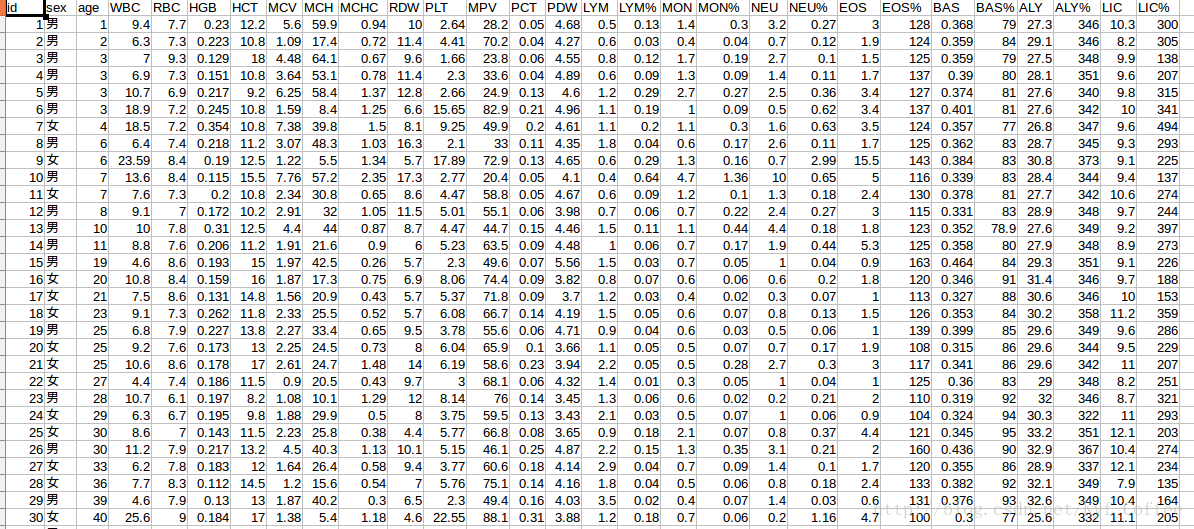
首先是用到的数据格式,如下
data.py的功能是加载所需数据,并做了一些简单的处理,如将分类问题结果转换为one-hot类型数据,对年龄数据为了提高准确率,划分了区间。
然后是用到的模型,在model.py中,使用keras深度学习框架,分别实现了年龄预测和性别预测。
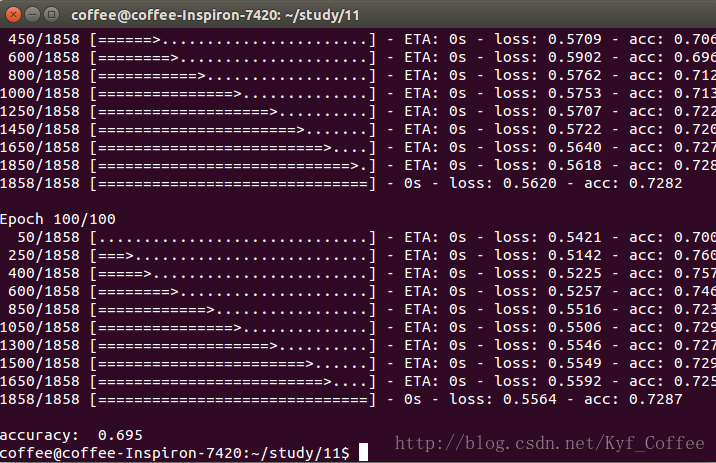
性别预测模型中使用了4层的全连接神经网络,输入层维度为26,第一个隐藏层20个节点,采用的激励函数为tanh,dropout参数为0.2(防止过拟合在每次训练中随机屏蔽百分之20的节点),第二个隐藏层15个节点,激励函数和dropout同第一层,输出层为2分类,采用softmax激励函数。经过100次迭代,batch_size为50(每50个数据更新一次权值),在200个测试集上准确率在70%左右。
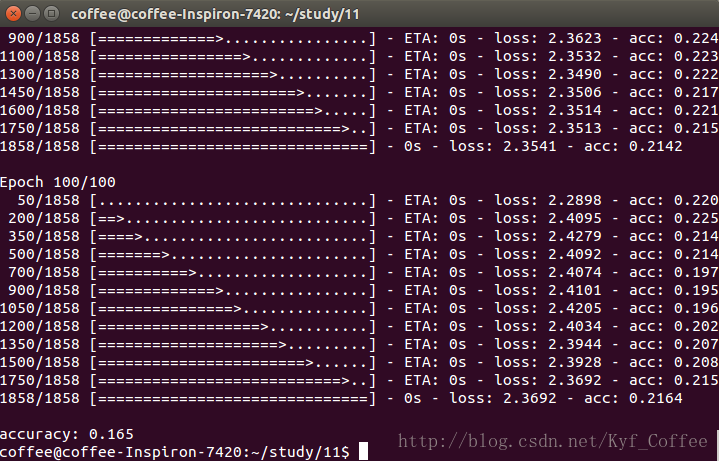
年龄预测模型使用了4层的全连接神经网络,输入同性别预测相同,第一个隐藏层节点为25,第二个隐藏层节点为20,在年领预测上效果很差,在测试上准确率只有15%左右。
在k_predict.py中调用训练好的模型实现预测,在首次加载时可能要训练模型。
将结果集成到web系统中,在view,py中添加下边代码。
在index.html里添加下边代码:
最终项目的展示效果为:
系统主界面
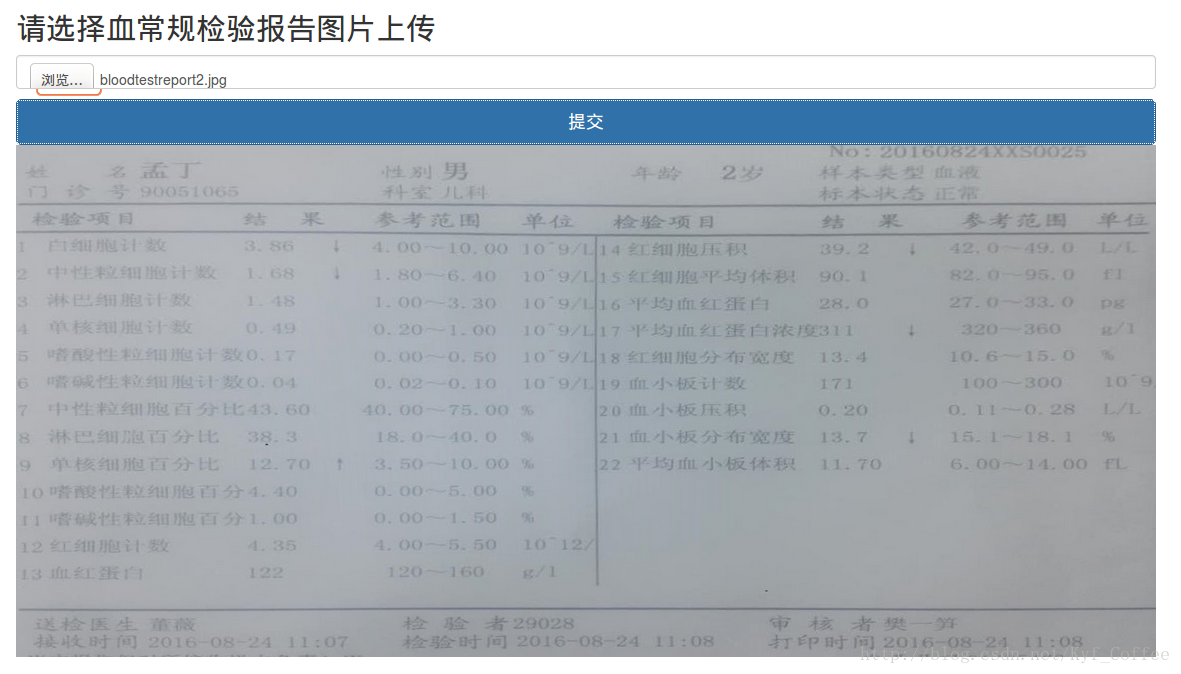
提交后的显示结果
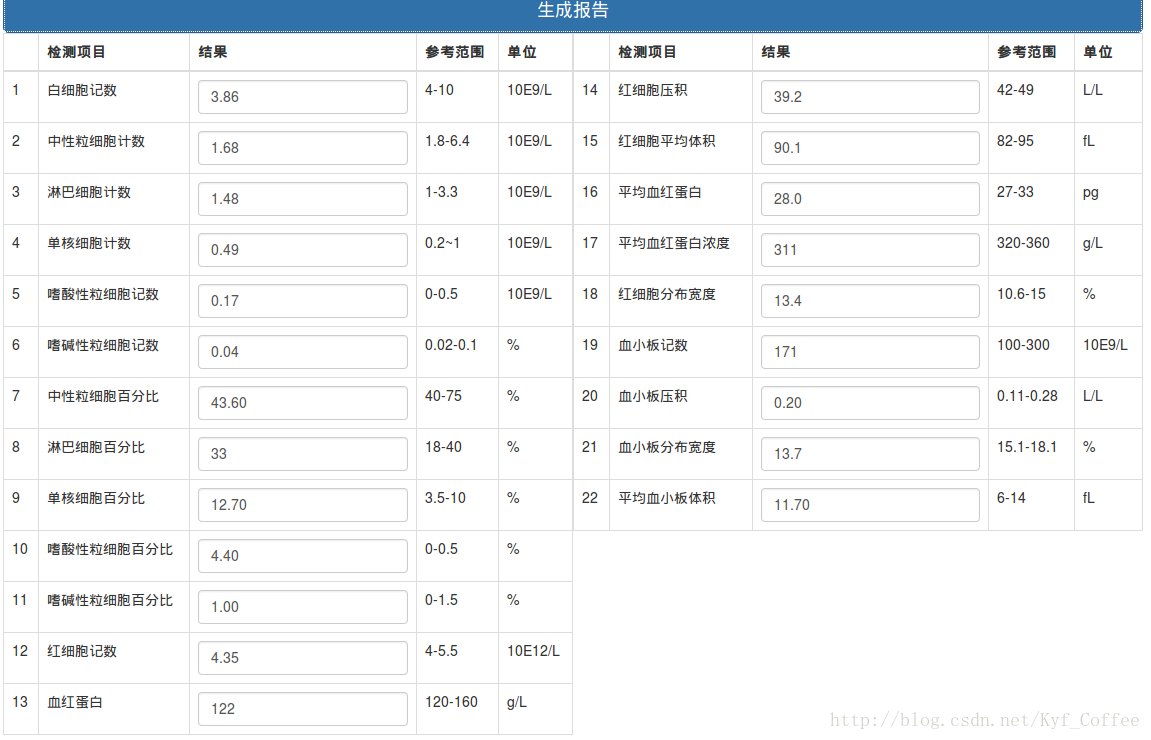
OCR识别结果
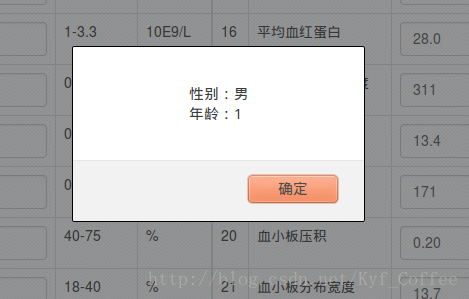
预测结果
年龄预测的结果依然不理想,可能是我模型的设置不太好,准确度仍旧在15%左右。
这部分代码可以在我的代码仓库中Test2文件夹下,里边有使用说明,包括数据清洗文件predata.py和模型文件model.py
由于我们的项目数据维度较低,不太适合使用卷机神经网络,在学习过程中,为了提高自己对卷积神经网络的理解和使用,做了一个交通标志识别的小demo,加深了对CNN的理解和使用,这里有该项目的详细说明和代码,在此就不做过多的说明。
在这门课的学习中,我了解到了很多机器学习的算法,从最简单的knn,到决策树,随机森林,svm,LR,贝叶斯等等,以及bp神经网络,卷积神经网络,递归神经网络包括LSTM等等,现在的状态就是对这些算法有了大致的了解,深入细节还是一知半解甚至有的还啥都不懂,在算法这一块,后边还有很多书要啃。
在数据处理这块儿,由于在学习过程中,不断的看资料,了解一些信息,在工业界可能做机器学习数据挖掘方面,百分之七八十甚至更多的时间都是在对数据进行处理,其中特征工程非常重要,经常听到好的数据加上一般的模型效果可能好与差得数据(特征工程做的不好)配上复杂高大上的算法,数据决定了上限,而模型只是逼近上限的不同方式。因此在课程项目中,我一直在考虑在特征工程方向下手对我们的数据怎么处理,怎么提取特征可能会使结果更好一些,可惜由于各方面的技能、经验的严重缺失,一直没有什么好的成果,这一块儿后边还要继续学而且应该是重点学!
然后项目中用到的web模块,自己可能没有去过多的了解,只是把同学的代码大致读懂,然后搞清楚了数据流向,这块儿内容只能以后慢慢学了,这方面也是很惭愧。
对这门课的整体感受就是信息量巨大,很多来不及消化和实践,在课程结束后还要继续深究。关于git多人合作开发,从开始的迷茫体会不到好处到后来被深深折服,孟宁老师作为项目的总指挥,布置阶段性任务的方式使我们一步实现一个小目标,成就感十足,同时深感人多力量大,以后遇到同样的情况要多做贡献!对于文档,以前一直忽略,现在越来越体会到了其重要性,虽然自己还写的很烂,但要养成写文档的好习惯,不然别说别人看不懂,时间久了自己的代码都要看不懂了。
总之,收获满满,一切才刚刚开始,要学的还有很多!
下边是一些可能会用到的资料分享
CSDN机器学习知识库
Kaggle数据竞赛平台
O’Reilly数据科学的一些文章
课程目标
课程安排
commitpr
项目地址
关于A1a
关于A2
关于A3
其他方面的一些学习
课程心得
课程目标
通过实现一个医学辅助诊断的专家系统原型,具体为实现对血常规检测报告OCR识别结果,预测人物的年龄和性别,学习机器学习的常见算法,重点分析神经网路,理解和掌握常用算法的使用。课程安排
A1a 神经网络实现手写字符识别系统A2 血常规检验报告的图像OCR识别
A3 根据血常规检验的各项数据预测年龄和性别
commit/pr
在课程进行中,我只做了一点点贡献。- 提交了imgproc.py文件,对剪裁好的图片进行OCR识别,最终用在了项目中。
- 分享了开源ocr识别库,tesseract。
项目地址
课程主页:介绍了课程整体安排主项目地址:聚集了大家的智慧,有多种不同实现,同时有项目所需环境的安装及配置
我fork的分支地址:我自己的一些实现
关于A1a
通过实现手写字符识别,作为机器学习的入门,其中用到了用到了BP神经网络,关于BP神经网络的一些理解,可以参考这里。在该项目中,我使用深度学习框架keras实现了手写字符的识别,集成到了web系统中,这里有使用说明。
效果图:
关于A2
A2的主要目的是对血常规报告单进行OCR识别,其中最困难的部分就是对要识别区域的锁定和剪裁。这部分工作由这位大神同学率先完成并延用至今。对于图像剪裁,在处理过程中的整理思路非常明确,我们并没有将目标定位于完全适用各种血常规报告单。因此将我们所采用的报告单的图片格式作为识别标准,通过对图片的预处理,包括灰度化、模糊、开闭运算等等,然后重点根据图片的特征,即图中的三条基准线,对图片进行水平方向上的梯度检测,然后根据检测出的线的位置,逐步确定表头表尾,最终就很容易实现了剪裁。这部分的细节在这位同学的PPT中介绍的很清楚,这里就不多余赘述。看一下实现的效果。
这是原始图片
描绘出边缘
在确定表头和表尾后对图片进行透视投影变换,得到最终要剪切的标准图片
我在项目中的主要贡献就在接下来的OCR部分。讲一下我的主要思路。首先对于剪裁后的图片,如
参考Tesseract官方给出的提高识别率的方法。
对图片进行二值化处理,这里我使用了ostu算法对图像进行二值化处理,它是一种高效的二值化算法,可以参考wiki里关于算法的详细介绍。
为了处理图片中的噪声点,对图片进行了腐蚀操作
将图片放大,Tesseract对于较大的图片有较好的识别结果
再次腐蚀被放大的噪声点
膨胀使图片内容饱满便于识别
直方图均衡化,提高图片的对比度
中值滤波去除孤立的噪声点
经过以上步骤的处理,同时在Tesseract配置文件中加入了适合我们识别项目的白名单,Tesseract能够很好的工作,加上后期对识别结果的字符串操作,识别结果基本满意。以下是上述操作的代码实现:
def digitsimg(src): #灰度化 img_gray = cv2.cvtColor(src,cv2.COLOR_BGR2GRAY) #Otsu thresholding 二值化 ret,result= cv2.threshold(img_gray,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU) #腐蚀去除一些小的点 kernel = cv2.getStructuringElement(cv2.MORPH_CROSS,(3,2)) eroded = cv2.erode(result,kernel) #将结果放大便于识别 result = cv2.resize(result,(128,128),interpolation=cv2.INTER_CUBIC) #腐蚀去除放大后的一些小的点 eroded = cv2.erode(result,kernel) #膨胀使数字更饱满 result = cv2.dilate(eroded,kernel) #直方图均衡化使图像更清晰 cv2.equalizeHist(result) #中值滤波去除噪点 result = cv2.medianBlur(result,5) return result
A2部分接下来的工作就是搭建web系统,将上述一系列剪裁、识别等实现放在web页面中展示,并将结果存入mongoDB中。
在这部分,使用了python的Flask框架,它是一个轻量级的web框架。数据的具体流程是启动服务器,连接到mongo数据库,前台接受图片,执行矫正、识别操作,调用相应模块,将结果存入mongodb中。
关于A3
这部分涉及到了该系统的核心,即对数据进行训练和预测。在主项目地址中,有很多同学采用不同的方式实现。这里讲一下我自己的实现。首先是用到的数据格式,如下
data.py的功能是加载所需数据,并做了一些简单的处理,如将分类问题结果转换为one-hot类型数据,对年龄数据为了提高准确率,划分了区间。
然后是用到的模型,在model.py中,使用keras深度学习框架,分别实现了年龄预测和性别预测。
nb_classes1 = 2
nb_classes2 = 20
batch_size = 50
nb_epoch = 100
x_train,y1_train,y2_train = load_data('train.csv')
x_test,y1_test,y2_test = load_data('predict.csv')
def gender():
model = Sequential()
model.add(Dense(20,input_shape = (26,)))
model.add(Activation('tanh'))
model.add(Dense(20))
model.add(Activation('tanh'))
model.add(Dropout(0.2))
model.add(Dense(15))
model.add(Activation('tanh'))
model.add(Dropout(0.2))
model.add(Dense(nb_classes1))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])
model.fit(x_train,y1_train,batch_size=batch_size,nb_epoch=nb_epoch,verbose =1,shuffle=True)
score = model.evaluate(x_test, y1_test, verbose=0)
print score[0],score[1]
model.save('gender.h5')
def age():
model = Sequential()
model.add(Dense(25,input_shape=(26,)))
model.add(Activation('tanh'))
model.add(Dense(25))
model.add(Activation('tanh'))
model.add(Dropout(0.2))
model.add(Dense(20))
model.add(Activation('tanh'))
model.add(Dropout(0.2))
model.add(Dense(nb_classes2))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',optimizer = Adam(),metrics=['accuracy'])
model.fit(x_train,y2_train,batch_size= batch_size,nb_epoch = nb_epoch,verbose = 1,shuffle=True)
score = model.evaluate(x_test, y2_test, verbose=0)
print score[0],score[1]
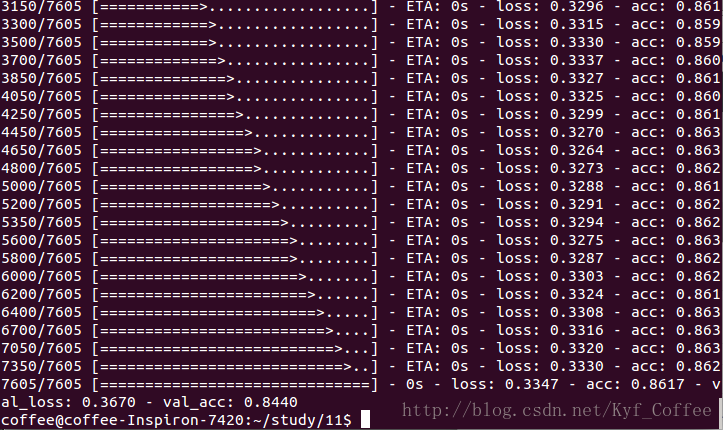
model.save('Age.h5')性别预测模型中使用了4层的全连接神经网络,输入层维度为26,第一个隐藏层20个节点,采用的激励函数为tanh,dropout参数为0.2(防止过拟合在每次训练中随机屏蔽百分之20的节点),第二个隐藏层15个节点,激励函数和dropout同第一层,输出层为2分类,采用softmax激励函数。经过100次迭代,batch_size为50(每50个数据更新一次权值),在200个测试集上准确率在70%左右。
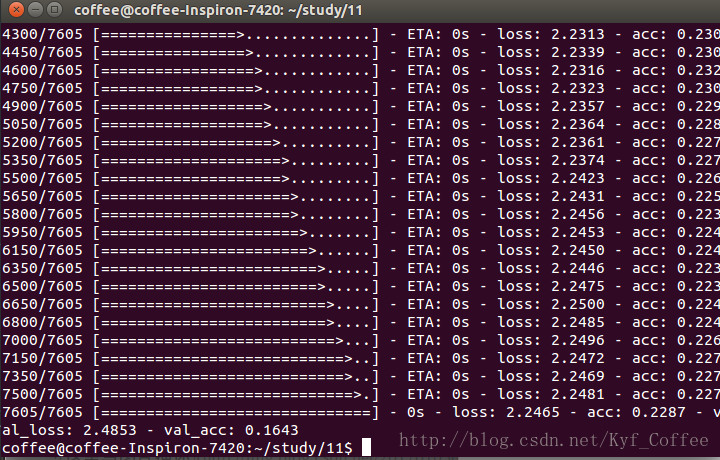
年龄预测模型使用了4层的全连接神经网络,输入同性别预测相同,第一个隐藏层节点为25,第二个隐藏层节点为20,在年领预测上效果很差,在测试上准确率只有15%左右。
在k_predict.py中调用训练好的模型实现预测,在首次加载时可能要训练模型。
from model import train import os from keras.models import load_model FILE_PATH1 = 'gender.h5' FILE_PATH2 = 'Age.h5' def getmodel(): #判断模型是否存在 if os.path.exists(FILE_PATH1 and FILE_PATH2): model1 = load_model(FILE_PATH1) model2 = load_model(FILE_PATH2) else: train() model1 = load_model(FILE_PATH1) model2 = load_model(FILE_PATH2) return model1,model2 def predict(data): model1,model2 = getmodel() result1 = model1.predict_classes(data,batch_size = 1,verbose =0) result2 = model2.predict_classes(data,batch_size = 1,verbose=0) return result1,result2
将结果集成到web系统中,在view,py中添加下边代码。
import k_predict
@app.route("/predict", methods=['POST'])
def predict():
data = json.loads(request.form.get('data'))
ss = data['value']
for i in range(4):
ss.append('0')
arr = numpy.array(ss)
arr = numpy.reshape(arr, [1, 26])
gender, age = k_predict.predict(arr)
result = {
"sex":gender[0],
"age":int(age[0])
}
return json.dumps(result)在index.html里添加下边代码:
test: function(event) {
data = [];
for(var i=0;i<13;i++)
data[i] = Number(this.report_items_left[i].value);
for(var i=0;i<9;i++)
data[13+i] = Number(this.report_items_right[i].value);
var data = {
data: JSON.stringify(({
"value":data
}))
};
$.ajax({
url: "/predict",
type: 'POST',
data: data,
success: function(data) {
var obj = JSON.parse(data)
if(obj.sex == 1)
var sexsex = "男";
else
var sexsex = "女"
alert("性别:" + sexsex + "\n年龄:" + obj.age);
}
})
}<button type="button" v-on:click="test()" class="btn btn-primary btn-lg btn-block">预测年龄和性别pre</button>
最终项目的展示效果为:
系统主界面
提交后的显示结果
OCR识别结果
预测结果
其他方面的一些学习
对于老师给的第二批数据,即train2.csv(8000多个数据)进行了些处理和预测(随机取百分之90做训练,百分之10做预测),使用同样的模型,性别预测的准确度可以提高到85%左右。年龄预测的结果依然不理想,可能是我模型的设置不太好,准确度仍旧在15%左右。
这部分代码可以在我的代码仓库中Test2文件夹下,里边有使用说明,包括数据清洗文件predata.py和模型文件model.py
由于我们的项目数据维度较低,不太适合使用卷机神经网络,在学习过程中,为了提高自己对卷积神经网络的理解和使用,做了一个交通标志识别的小demo,加深了对CNN的理解和使用,这里有该项目的详细说明和代码,在此就不做过多的说明。
课程心得
在当初选课时候,看到了课程介绍要搞神经网络机器学习等方面,自己就有了极大的兴趣,虽然很小白,但确实很想学这方面,毕竟AlphaGO闹的太厉害,对AI有极大的兴趣。后来在选择工程实践时候就也选了孟宁老师的课题,但没想到竟然拿来在课程上做啦,说到这里也很是惭愧,在整个过程中自己的贡献确是很少,有时觉得做的东西并不能有很大的提高或者改进,就觉得没有pr的必要,在课程的不断进行中越来越觉得自己的这种想法不够好,并没能体会到团队的力量反而是自己在那里缓步前进,这一点在后期看了同学五花八门的代码后才有所顿悟,原来每个人的一点小小的贡献,可能就能对其他人有所启发(我就很被启发在某些代码用法上),而少走很多弯路!以后一定要重视这一点!不然不但帮助不到别人,自己的进步也很慢。在这门课的学习中,我了解到了很多机器学习的算法,从最简单的knn,到决策树,随机森林,svm,LR,贝叶斯等等,以及bp神经网络,卷积神经网络,递归神经网络包括LSTM等等,现在的状态就是对这些算法有了大致的了解,深入细节还是一知半解甚至有的还啥都不懂,在算法这一块,后边还有很多书要啃。
在数据处理这块儿,由于在学习过程中,不断的看资料,了解一些信息,在工业界可能做机器学习数据挖掘方面,百分之七八十甚至更多的时间都是在对数据进行处理,其中特征工程非常重要,经常听到好的数据加上一般的模型效果可能好与差得数据(特征工程做的不好)配上复杂高大上的算法,数据决定了上限,而模型只是逼近上限的不同方式。因此在课程项目中,我一直在考虑在特征工程方向下手对我们的数据怎么处理,怎么提取特征可能会使结果更好一些,可惜由于各方面的技能、经验的严重缺失,一直没有什么好的成果,这一块儿后边还要继续学而且应该是重点学!
然后项目中用到的web模块,自己可能没有去过多的了解,只是把同学的代码大致读懂,然后搞清楚了数据流向,这块儿内容只能以后慢慢学了,这方面也是很惭愧。
对这门课的整体感受就是信息量巨大,很多来不及消化和实践,在课程结束后还要继续深究。关于git多人合作开发,从开始的迷茫体会不到好处到后来被深深折服,孟宁老师作为项目的总指挥,布置阶段性任务的方式使我们一步实现一个小目标,成就感十足,同时深感人多力量大,以后遇到同样的情况要多做贡献!对于文档,以前一直忽略,现在越来越体会到了其重要性,虽然自己还写的很烂,但要养成写文档的好习惯,不然别说别人看不懂,时间久了自己的代码都要看不懂了。
总之,收获满满,一切才刚刚开始,要学的还有很多!
下边是一些可能会用到的资料分享
CSDN机器学习知识库
Kaggle数据竞赛平台
O’Reilly数据科学的一些文章

相关文章推荐
- 网络程序设计课程总结
- 网络程序设计课程项目总结
- 网络程序设计课程项目总结
- 网络程序设计课程项目学习总结
- 网络程序设计课程学习心得总结
- 网络程序设计课程总结
- 网络程序设计课程总结
- windows网络程序设计课程设计
- 中南大学第十一届大学生程序设计竞赛网络预选赛总结
- 网络程序设计学习总结
- 《C语言及程序设计初步》网络课程主页
- CMU J2EE网络开发课程总结笔记
- 网络程序设计结课总结——神经网络篇
- C#程序设计与应用课程教学总结兼2014年回顾
- 2016年秋-网络程序设计 学习总结
- C#程序设计课程总结
- spark网络课程总结
- 《C语言及程序设计提高》网络课程主页
- 《C语言及程序设计进阶》网络课程主页
- 大学网络管理课程复习总结