挑子学习笔记:特征选择——基于假设检验的Filter方法
2017-01-02 12:08
411 查看
转载请标明出处:
http://www.cnblogs.com/tiaozistudy/p/hypothesis_testing_based_feature_selection.html
Filter特征选择方法是一种启发式方法,其基本思想是:制定一个准则,用来衡量每个特征/属性,对目标属性的重要性程度,以此来对所有特征/属性进行排序,或者进行优选操作。常用的衡量准则有假设检验的p值、相关系数、互信息、信息增益等。本文基于候选属性和目标属性间关联性的假设检验,依据p值的大小量化各候选属性的重要性程度。
设有$D $维数据集$\mathfrak D = \{\vec x_n \}_{n=1,...,N} $,其中$\vec x_n = (x_{n1},...,x_{n,D-1},y_n) $,数据集$\mathfrak D $由$D-1 $个候选属性$X_1,...,X_{D-1} $和1个目标属性$Y $刻画。属性在本文中分为两种类型:连续型属性和离散型属性,各属性均有可能是连续型的或者离散型的。本文的工作是通过对候选属性$X \; (\in \{X_1,...,X_{D-1} \})$和目标属性$Y $之间的关联性进行假设检验,量化各候选属性单独预测目标属性的能力,根据属性类型的不同,可以区分为4种情况:
1)$X$和$Y $都是离散型属性;
2)$X$是连续型属性,$Y $是离散型属性;
3)$X$是离散型属性,$Y $是连续型属性;
4)$X$和$Y $都是连续型属性。
对属性$X$和$Y $的关联性作假设检验的思想是:将$X$和$Y $看作是两个随机变量,将数据集$\mathfrak D $中相关属性下的数值看作是随机变量的观测值,即有观测值$x_1,...,x_N $和$y_1,...,y_N $,根据这些观测值构造出与$X$和$Y $独立性/关联性相关,且服从已知分布(主要是$\chi^2 $、$t $和$F $分布)的统计量,最后根据已知分布的概率函数确定独立性检验的p值,用于属性$X$和$Y $关联程度的度量。
[b]表 1:列联表[/b]
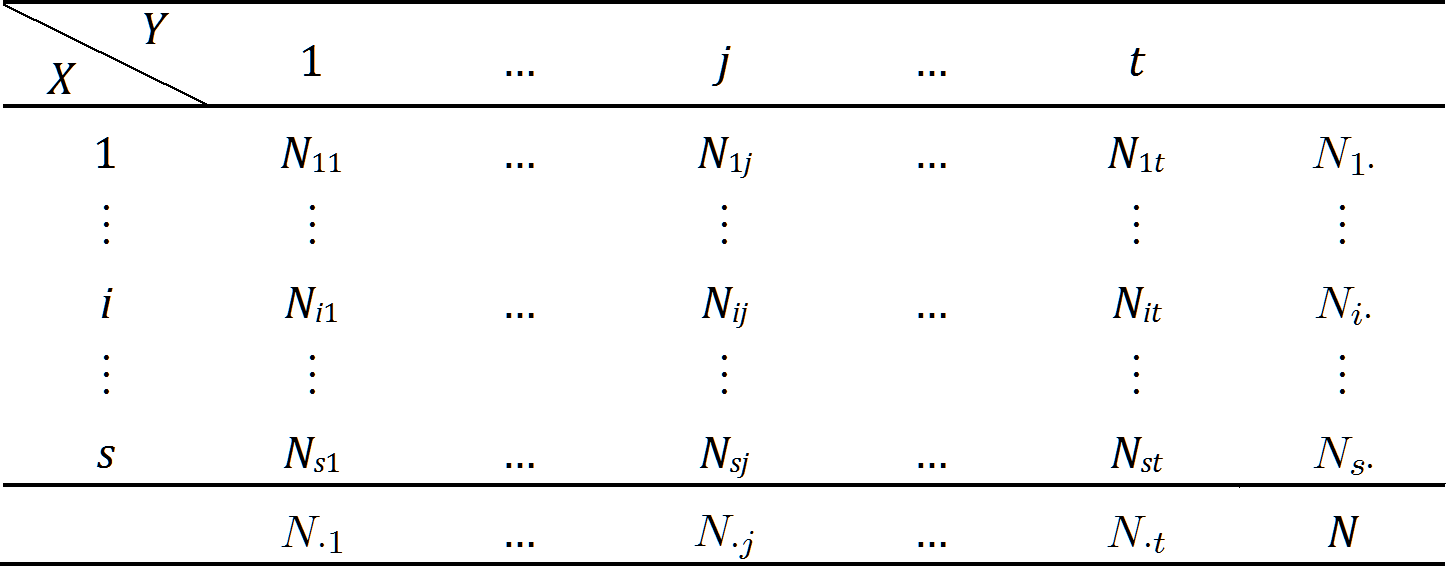
如果把$X$和$Y $看作是随机变量,则有概率分布,记为$p_{Xi} \; (i=1,...,s) $和$p_{Xj} \; (j=1,...,t) $,且有二维随机变量$(X,Y) $的概率分布:$p_{ij} \; (i=1,...,s; \; j= 1,...,t) $.易知,$\forall i=1,...,s; \; j=1,...,t $有$p_{ij} = p_{Xi} \cdot p_{Yj} $时,$X$与$Y $独立。因此有假设$$ \begin{equation} H: \; p_{ij} = p_{Xi} \cdot p_{Yj} \quad (i=1,...,s; \; j=1,...,t) \end{equation} $$观察值接受此假设的程度即为p值。
首先估计(1)式中的参数得$$ \begin{equation} \begin{split} \hat p_{Xi} = N_{i\cdot}/N \; (i=1,...,s) \\ \hat p_{Yj} = N_{\cdot j}/N \; (j=1,...,t) \end{split} \end{equation}$$进一步计算如下统计量:$$ \begin{equation} \begin{split} K & = \sum_{i=1}^s \sum_{j=1}^t \frac{(N_{ij} - N\hat p_{Xi} \hat p_{Yj})^2}{N\hat p_{Xi} \hat p_{Yj}} \\ & = N \left ( \sum_{i=1}^s \sum_{j=1}^t \frac{N_{ij}^2}{N_{i \cdot}N_{\cdot j}} - 1 \right) \end{split} \end{equation} $$经证明统计量$K $的分布收敛于自由度为$ d = (s-1)(t-1) $的$\chi^2 $分布,因此p值近似为:$$ \begin{equation} p_{value} = P(\chi^2_d > K) \end{equation} $$因为$\chi^2_d $的概率密度函数是已知的,所有不难通过(4)式计算出p值。
由(3)式可知,当$K $越小时,$|N_{ij}/N - \hat p_{Xi} \hat p_{Yj}| \rightarrow 0 $,因此拒绝(1)式假设的概率越小,即$X$与$Y $独立的可能性越大,由(4)式计算出的p值越大;相反地,p值越小,$X$与$Y $独立的可能性越小,相关联的可能性越大。因此p值越小,属性$X$越重要。
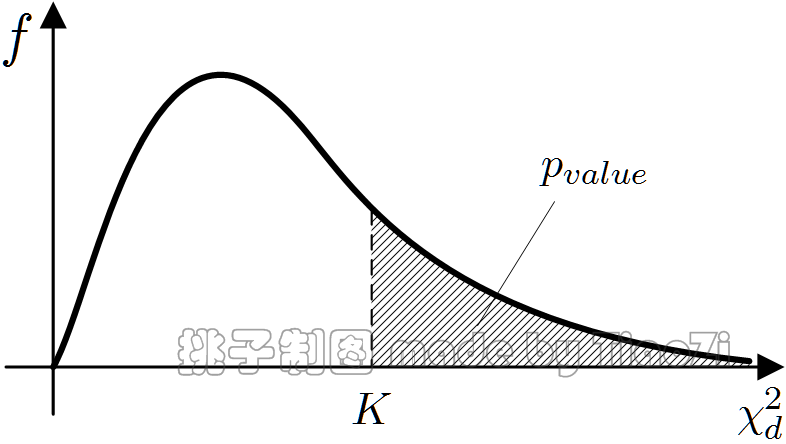
图 1:Pearson $\chi^2 $检验的p值
设第$i $个试验组的期望为$\mu_i $,可提出假设:$$ \begin{equation} H: \mu_1 = \mu_2 = ... = \mu_I \end{equation} $$文献[1]中证明,当上述假设成立,有$$ \begin{equation} \frac{E[SS_B]}{I-1} = \frac{E[SS_W]}{J-I} \end{equation} $$式中$E[\cdot] $表示期望,$J=\sum_{i=1}^I J_i $.然而当(6)式中假设不成立时,有$$ \begin{equation} \frac{E[SS_B]}{I-1} > \frac{E[SS_W]}{J-I} \end{equation} $$
又有证明,统计量$$ \begin{equation} K = \frac{SS_B/(I-1)}{SS_W/(J-I)} \end{equation} $$在(6)式假设下服从自由度为$I-1 $和$J-I $的$F $分布,即$K \sim F_{I-1, J-I} $.根据(7)式和(8)式的分析,当(6)式假设为真时,$K $的值接近于1,否则$K $的值应该较大。因此可以根据$P(F_{I-1,J-I} > K) $接受或拒绝假设$H $.
表 2:数据表
其中$N = J_1 + ... + J_I $表示数据对象的总个数。也就是说数据对象可以像2.1小节那样根据$X$的取值划分为$I $组。
按照概率论的知识,变量$X$与$Y $相互独立,则有$$ \begin{equation} P(Y<y,X=x) = P(Y<y)P(X=x) \end{equation} $$然而如果变量$X$与$Y$不独立,有$$ \begin{equation} P(Y<y,X=x) = P(Y<y|X=x)P(X=x) \end{equation} $$即当变量$X$与$Y $相互独立时$P(Y<y|X=x) = P(Y<y) $,因此在上述的各组中,变量$Y $具有相同的分布函数:$$ \begin{equation} P(Y<y|X=x_1) = ... = P(Y<y|X=x_I) = P(Y<y) \end{equation} $$假设$X$取值$x_i $的数据组下$Y \sim N(\mu_i, \sigma^2) $,变量$X$与$Y $相互独立时必然有$\mu_1 = ... = \mu_I $,这与(6)式中的假设$H $完全相同,所以离散变量$X$与连续变量$Y $之间的关联性可以通过单因子方差分析度量。
首先按照(5)式中的定义计算$SS_B $和$SS_W $,而后根据(9)式计算出$K $值:$$ \begin{equation} K = \frac{\sum_{i=1}^I J_i(\bar y_i - \bar y)^2 / (I-1)}{\sum_{i=1}^I (J_i - 1) s^2_j / (N-I)} \end{equation} $$其中$\bar y_i = \sum_{j=1}^{J_i} y_{ij} / J_i $,$\bar y = \sum_{i=1}^I J_i \bar y_i / N $,$s^2_j = \sum_{j=1}^{J_i} (y_{ij} - \bar y_i)^2 / (J_i - 1) $,进而计算p值:$$ \begin{equation} p_{value} = P(F_{I-1,J-I} > K) \end{equation} $$
根据上文的分析,当$X$与$Y $关联性越小,$K $越小,此时p值越大;相反地,当$X $与$Y $关联性越大,$K $越大,p值越小。
为了对$H $做假设检验,首先对$r $作变换:$$ \begin{equation} K = \frac{r\sqrt{N-2}}{\sqrt{1-r^2}} \end{equation} $$可以证明$K $服从自由度为$N-2 $的t分布[2],即$K \sim t_{N-2} $.证明过程很复杂,本文仅叙述证明思路,如果深究,请参考文献[2]:假定随机变量$X$与$Y $是正态无相关的,计算相关系数统计量$r $的概率密度函数$f(r) $,根据(17)式的关系计算出$K $的概率密度函数,发现$K $的概率密度函数与自由度为$N-2 $的t分布的概率密度函数完全一致,因此$K \sim t_{N-2} $.
基于$t_{N-2} $分布对$H $做假设检验,可计算p值:$$ \begin{equation} p_{value} = \begin{cases} 0, & r^2 = 1 \\ 2 \cdot P(t_{N-2} > |K|), & \text{otherwise} \end{cases} \end{equation} $$
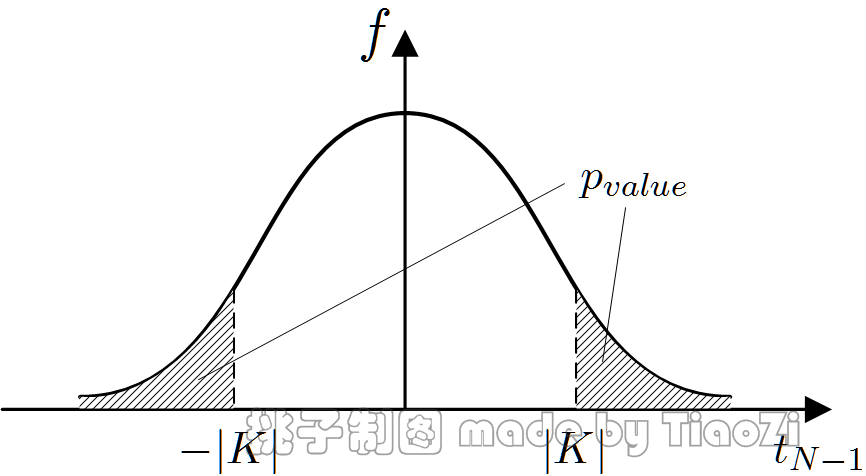
图 2:Pearson相关系数显著性检验的p值
然而Pearson相关系数有一个不足:如果随机变量$X$和$Y $之间存在线性关系,即$Y = aX+b $,则Pearson相关系数适用,但是如果$X$和$Y $之间的关系是非线性的,则Pearson相关系数不适用。举个例子:
例 1:设$X $与$Y $有如下的函数关系:$$ \begin{equation} y = \begin{cases} x, & 0 \le x < 1 \\ 3-x, & 1 \le x \le 2 \end{cases} \end{equation} $$其中$X $服从区间$[0,2] $的均匀分布,可算得$X $与$Y $相关系数为:$$ \begin{equation} \rho_{XY} = \frac{E[(X-E(X))(Y-E(Y))]}{\sqrt{E[(X-E(X))^2]E[(Y-E(Y))^2]}} = \frac34 \end{equation} $$然而如果有随机变量$Y' = X $,易得$\rho_{XY'} = 1 $,有$\rho_{XY} \ne \rho_{XY'} $.
尝试分别对二维变量$(X,Y) $和$(X,Y') $作如图所示的离散化:$X$、$Y $、$Y’ $等宽的划分成4个小区间,依次以1、2、3、4记名。
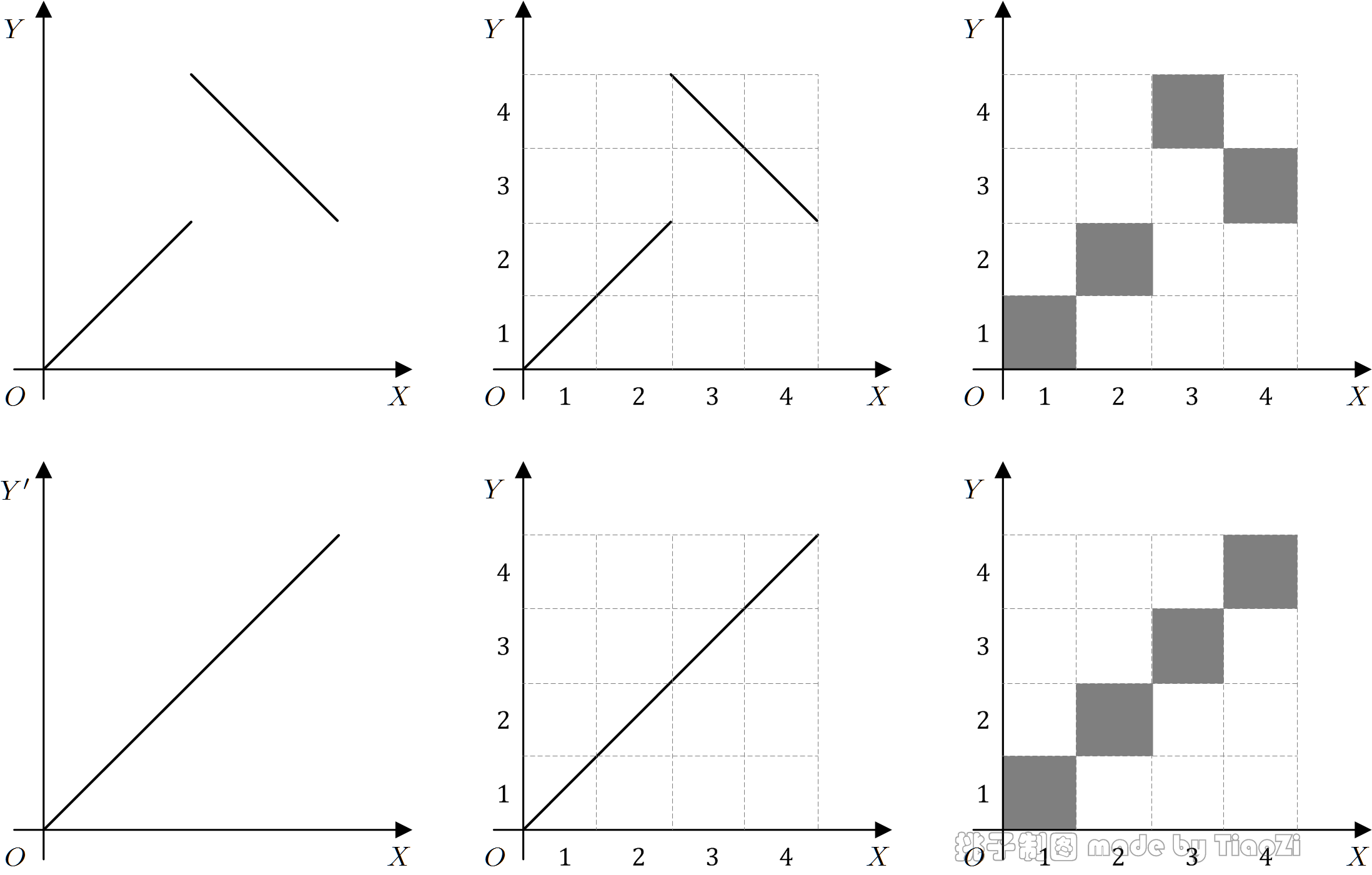
图 3:离散化
离散化后,图中白色方格代表概率为零,灰色方格代表概率为$1/4 $,如$P(X=1,Y=1)=1/4 $.根据$\chi^2 $检验的原理,易知离散化后,$(X,Y) $与$(X,Y') $有相同的关联性,与上述Pearson相关系数的结果并不吻合。
类似例 1的例子还有很多,这些都是由于Pearson不支持非线性相关性引起的,在使用上述方法做特征选择时,需要注意这点。
[2] Fisz M. 概率论及数理统计[M]. 上海科学技术出版社, 1962.
http://www.cnblogs.com/tiaozistudy/p/hypothesis_testing_based_feature_selection.html
Filter特征选择方法是一种启发式方法,其基本思想是:制定一个准则,用来衡量每个特征/属性,对目标属性的重要性程度,以此来对所有特征/属性进行排序,或者进行优选操作。常用的衡量准则有假设检验的p值、相关系数、互信息、信息增益等。本文基于候选属性和目标属性间关联性的假设检验,依据p值的大小量化各候选属性的重要性程度。
设有$D $维数据集$\mathfrak D = \{\vec x_n \}_{n=1,...,N} $,其中$\vec x_n = (x_{n1},...,x_{n,D-1},y_n) $,数据集$\mathfrak D $由$D-1 $个候选属性$X_1,...,X_{D-1} $和1个目标属性$Y $刻画。属性在本文中分为两种类型:连续型属性和离散型属性,各属性均有可能是连续型的或者离散型的。本文的工作是通过对候选属性$X \; (\in \{X_1,...,X_{D-1} \})$和目标属性$Y $之间的关联性进行假设检验,量化各候选属性单独预测目标属性的能力,根据属性类型的不同,可以区分为4种情况:
1)$X$和$Y $都是离散型属性;
2)$X$是连续型属性,$Y $是离散型属性;
3)$X$是离散型属性,$Y $是连续型属性;
4)$X$和$Y $都是连续型属性。
对属性$X$和$Y $的关联性作假设检验的思想是:将$X$和$Y $看作是两个随机变量,将数据集$\mathfrak D $中相关属性下的数值看作是随机变量的观测值,即有观测值$x_1,...,x_N $和$y_1,...,y_N $,根据这些观测值构造出与$X$和$Y $独立性/关联性相关,且服从已知分布(主要是$\chi^2 $、$t $和$F $分布)的统计量,最后根据已知分布的概率函数确定独立性检验的p值,用于属性$X$和$Y $关联程度的度量。
1、基于Pearson $\chi^2 $检验的离散变量关联性度量
针对属性$X$和$Y $都是离散型的,可以通过Pearson $\chi^2 $检验方法检验$X$和$Y $的独立性。设$X$有$s $种可能取值,$Y $有$t $种可能取值,记$N_{ij} $为$X$取第$i $个值$Y$取第$j $个值的数据对象个数,且有$N_{i\cdot} = \sum_{j=1}^t N_{ij} $,$N_{\cdot j} = \sum_{i=1}^s N_{ij} $,可作如下列联表:[b]表 1:列联表[/b]
如果把$X$和$Y $看作是随机变量,则有概率分布,记为$p_{Xi} \; (i=1,...,s) $和$p_{Xj} \; (j=1,...,t) $,且有二维随机变量$(X,Y) $的概率分布:$p_{ij} \; (i=1,...,s; \; j= 1,...,t) $.易知,$\forall i=1,...,s; \; j=1,...,t $有$p_{ij} = p_{Xi} \cdot p_{Yj} $时,$X$与$Y $独立。因此有假设$$ \begin{equation} H: \; p_{ij} = p_{Xi} \cdot p_{Yj} \quad (i=1,...,s; \; j=1,...,t) \end{equation} $$观察值接受此假设的程度即为p值。
首先估计(1)式中的参数得$$ \begin{equation} \begin{split} \hat p_{Xi} = N_{i\cdot}/N \; (i=1,...,s) \\ \hat p_{Yj} = N_{\cdot j}/N \; (j=1,...,t) \end{split} \end{equation}$$进一步计算如下统计量:$$ \begin{equation} \begin{split} K & = \sum_{i=1}^s \sum_{j=1}^t \frac{(N_{ij} - N\hat p_{Xi} \hat p_{Yj})^2}{N\hat p_{Xi} \hat p_{Yj}} \\ & = N \left ( \sum_{i=1}^s \sum_{j=1}^t \frac{N_{ij}^2}{N_{i \cdot}N_{\cdot j}} - 1 \right) \end{split} \end{equation} $$经证明统计量$K $的分布收敛于自由度为$ d = (s-1)(t-1) $的$\chi^2 $分布,因此p值近似为:$$ \begin{equation} p_{value} = P(\chi^2_d > K) \end{equation} $$因为$\chi^2_d $的概率密度函数是已知的,所有不难通过(4)式计算出p值。
由(3)式可知,当$K $越小时,$|N_{ij}/N - \hat p_{Xi} \hat p_{Yj}| \rightarrow 0 $,因此拒绝(1)式假设的概率越小,即$X$与$Y $独立的可能性越大,由(4)式计算出的p值越大;相反地,p值越小,$X$与$Y $独立的可能性越小,相关联的可能性越大。因此p值越小,属性$X$越重要。
图 1:Pearson $\chi^2 $检验的p值
2、基于单因子方差分析的连续变量与离散变量间关联性度量
先来看看什么是单因子方差分析[1]。2.1 单因子方差分析(one-way ANOVA)
假设有$I $组试验,每组包含$J_i \; (i=1,...,I) $个样本,设$Y_{ij} $表示第$i $个试验组的第$j $个样本,$\bar Y_i $表示第$i $组试验的样本均值,$\bar Y $表示总体均值,有下式:$$ \begin{equation} \begin{split} \sum_{i=1}^I \sum_{j=1}^{J_i} (Y_{ij} - \bar Y)^2 = & \sum_{i=1}^I \sum_{j=1}^{J_i} [(Y_{ij} - \bar Y_i) + (\bar Y_i - \bar Y)]^2 \\ = & \sum_{i=1}^I \sum_{j=1}^{J_i} (Y_{ij} - \bar Y_i)^2 + \sum_{i=1}^I \sum_{j=1}^{J_i} (\bar Y_i - \bar Y)^2 \\ & + 2\sum_{i=1}^I \sum_{j=1}^{J_i}(Y_{ij} - \bar Y_i)(\bar Y_i - \bar Y) \\ = & \sum_{i=1}^I \sum_{j=1}^{J_i} (Y_{ij} - \bar Y_i)^2 + \sum_{i=1}^I \sum_{j=1}^{J_i} (\bar Y_i - \bar Y)^2 \end{split} \end{equation} $$上式简记为$SS_{TOT} = SS_W + SS_B $,即总的平方和等于组内平方和加上组间平方和,$SS_W $表示试验组内部数据散布的度量,$SS_B $表示试验组之间散布的度量。设第$i $个试验组的期望为$\mu_i $,可提出假设:$$ \begin{equation} H: \mu_1 = \mu_2 = ... = \mu_I \end{equation} $$文献[1]中证明,当上述假设成立,有$$ \begin{equation} \frac{E[SS_B]}{I-1} = \frac{E[SS_W]}{J-I} \end{equation} $$式中$E[\cdot] $表示期望,$J=\sum_{i=1}^I J_i $.然而当(6)式中假设不成立时,有$$ \begin{equation} \frac{E[SS_B]}{I-1} > \frac{E[SS_W]}{J-I} \end{equation} $$
又有证明,统计量$$ \begin{equation} K = \frac{SS_B/(I-1)}{SS_W/(J-I)} \end{equation} $$在(6)式假设下服从自由度为$I-1 $和$J-I $的$F $分布,即$K \sim F_{I-1, J-I} $.根据(7)式和(8)式的分析,当(6)式假设为真时,$K $的值接近于1,否则$K $的值应该较大。因此可以根据$P(F_{I-1,J-I} > K) $接受或拒绝假设$H $.
2.2 关联性度量
再来看看如何利用单因子方差分析度量离散变量和连续变量间的关联性。以$X$是离散变量,$Y $是连续变量为例($X$是连续变量,$Y $是离散变量的情况可以类推)。设$X$有$I $种可能取值,记为$x_1, ..., x_I $,经过数据对象的顺序变换之后,总是可以得到如下表的数据形式:表 2:数据表
| $\cdots $ | $X$ | $\cdots $ | $Y $ | |
| $\vec x_1 $ | $\cdots $ | $x_1 $ | $\cdots $ | $y_{11} $ |
| $\vdots $ | $\vdots $ | $\vdots $ | $\vdots $ | $\vdots $ |
| $\vec x_{J_1} $ | $\cdots $ | $x_1 $ | $\cdots $ | $y_{1J_1} $ |
| $\vdots $ | $\vdots $ | $\vdots $ | $\vdots $ | $\vdots $ |
| $\vec x_{J_1 + ... + J_{i-1} + 1} $ | $\cdots $ | $x_i $ | $\cdots $ | $y_{i1} $ |
| $\vdots $ | $\vdots $ | $\vdots $ | $\vdots $ | $\vdots $ |
| $\vec x_{J_1 + ... + J_{i-1} + J_i} $ | $\cdots $ | $x_i $ | $\cdots $ | $y_{iJ_i} $ |
| $\vdots $ | $\vdots $ | $\vdots $ | $\vdots $ | $\vdots $ |
| $\vec x_{J_1 + ... + J_{I-1} + 1} $ | $\cdots $ | $x_I $ | $\cdots $ | $y_{I1} $ |
| $\vdots $ | $\vdots $ | $\vdots $ | $\vdots $ | $\vdots $ |
| $\vec x_{J_1 + ... + J_{I-1} + J_I} $ | $\cdots $ | $x_I $ | $\cdots $ | $y_{IJ_I} $ |
按照概率论的知识,变量$X$与$Y $相互独立,则有$$ \begin{equation} P(Y<y,X=x) = P(Y<y)P(X=x) \end{equation} $$然而如果变量$X$与$Y$不独立,有$$ \begin{equation} P(Y<y,X=x) = P(Y<y|X=x)P(X=x) \end{equation} $$即当变量$X$与$Y $相互独立时$P(Y<y|X=x) = P(Y<y) $,因此在上述的各组中,变量$Y $具有相同的分布函数:$$ \begin{equation} P(Y<y|X=x_1) = ... = P(Y<y|X=x_I) = P(Y<y) \end{equation} $$假设$X$取值$x_i $的数据组下$Y \sim N(\mu_i, \sigma^2) $,变量$X$与$Y $相互独立时必然有$\mu_1 = ... = \mu_I $,这与(6)式中的假设$H $完全相同,所以离散变量$X$与连续变量$Y $之间的关联性可以通过单因子方差分析度量。
首先按照(5)式中的定义计算$SS_B $和$SS_W $,而后根据(9)式计算出$K $值:$$ \begin{equation} K = \frac{\sum_{i=1}^I J_i(\bar y_i - \bar y)^2 / (I-1)}{\sum_{i=1}^I (J_i - 1) s^2_j / (N-I)} \end{equation} $$其中$\bar y_i = \sum_{j=1}^{J_i} y_{ij} / J_i $,$\bar y = \sum_{i=1}^I J_i \bar y_i / N $,$s^2_j = \sum_{j=1}^{J_i} (y_{ij} - \bar y_i)^2 / (J_i - 1) $,进而计算p值:$$ \begin{equation} p_{value} = P(F_{I-1,J-I} > K) \end{equation} $$
根据上文的分析,当$X$与$Y $关联性越小,$K $越小,此时p值越大;相反地,当$X $与$Y $关联性越大,$K $越大,p值越小。
3、基于Pearson相关系数显著性检验的连续变量关联性度量
针对均为连续变量的$X$和$Y $,根据数据集$\mathfrak D $的取值,有数据对$(x_n, y_n) \; (n=1,...,N) $,设均值和方差的统计量如下:$$ \bar x = \frac 1N \sum_{n=1}^N x_n $$$$\bar y = \frac 1N \sum_{n=1}^N y_n$$$$ s^2_x = \frac 1{N-1} \sum_{n=1}^N (x_n - \bar x)^2 $$$$s^2_y = \frac 1{N-1} \sum_{n=1}^N (y_n - \bar y)^2$$容易得到二维随机变量$(X,Y) $的Pearson相关系数的统计量:$$ \begin{equation} r = \frac{\sum_{n=1}^N (x_n - \bar x)(y_n - \bar y)}{(N-1)\sqrt{s^2_x s^2_y}} \end{equation}$$注意(15)式中$r $仅是通过样本得到的相关系数的统计量,如设变量$X$与$Y $的相关系数为$\rho $,则$r $只是$\rho $的估计。$X$是否与$Y $相互独立,$r=0 $说的不算,只有$\rho =0 $才行,因此构造如下假设:$$ \begin{equation} H:\rho = 0 \end{equation} $$需要通过样本计算得到的$r $的值,对(16)式的$H $做检验,如果接受$H $表示$X$与$Y $相互独立。为了对$H $做假设检验,首先对$r $作变换:$$ \begin{equation} K = \frac{r\sqrt{N-2}}{\sqrt{1-r^2}} \end{equation} $$可以证明$K $服从自由度为$N-2 $的t分布[2],即$K \sim t_{N-2} $.证明过程很复杂,本文仅叙述证明思路,如果深究,请参考文献[2]:假定随机变量$X$与$Y $是正态无相关的,计算相关系数统计量$r $的概率密度函数$f(r) $,根据(17)式的关系计算出$K $的概率密度函数,发现$K $的概率密度函数与自由度为$N-2 $的t分布的概率密度函数完全一致,因此$K \sim t_{N-2} $.
基于$t_{N-2} $分布对$H $做假设检验,可计算p值:$$ \begin{equation} p_{value} = \begin{cases} 0, & r^2 = 1 \\ 2 \cdot P(t_{N-2} > |K|), & \text{otherwise} \end{cases} \end{equation} $$
图 2:Pearson相关系数显著性检验的p值
然而Pearson相关系数有一个不足:如果随机变量$X$和$Y $之间存在线性关系,即$Y = aX+b $,则Pearson相关系数适用,但是如果$X$和$Y $之间的关系是非线性的,则Pearson相关系数不适用。举个例子:
例 1:设$X $与$Y $有如下的函数关系:$$ \begin{equation} y = \begin{cases} x, & 0 \le x < 1 \\ 3-x, & 1 \le x \le 2 \end{cases} \end{equation} $$其中$X $服从区间$[0,2] $的均匀分布,可算得$X $与$Y $相关系数为:$$ \begin{equation} \rho_{XY} = \frac{E[(X-E(X))(Y-E(Y))]}{\sqrt{E[(X-E(X))^2]E[(Y-E(Y))^2]}} = \frac34 \end{equation} $$然而如果有随机变量$Y' = X $,易得$\rho_{XY'} = 1 $,有$\rho_{XY} \ne \rho_{XY'} $.
尝试分别对二维变量$(X,Y) $和$(X,Y') $作如图所示的离散化:$X$、$Y $、$Y’ $等宽的划分成4个小区间,依次以1、2、3、4记名。
图 3:离散化
离散化后,图中白色方格代表概率为零,灰色方格代表概率为$1/4 $,如$P(X=1,Y=1)=1/4 $.根据$\chi^2 $检验的原理,易知离散化后,$(X,Y) $与$(X,Y') $有相同的关联性,与上述Pearson相关系数的结果并不吻合。
类似例 1的例子还有很多,这些都是由于Pearson不支持非线性相关性引起的,在使用上述方法做特征选择时,需要注意这点。
参考文献
[1] Rice, J.A.著, 田金方译. 数理统计与数据分析(原书第3版)[M]. 机械工业出版社, 2011, pp. 328-333.[2] Fisz M. 概率论及数理统计[M]. 上海科学技术出版社, 1962.

相关文章推荐
- 机器学习:特征选择之 Filter :Relief方法
- 基于sklearn的特征选择方法
- 科学论文1-软件缺陷预测中基于聚类分析的特征选择方法
- 基于L2,1范数的特征选择方法
- 基于伪label的一类无监督特征选择方法
- 文本分类入门(十一)特征选择方法之信息增益
- 特征选择方法之信息增益
- 基于运动特征的视频质量评价方法(基于H.264)
- 关于冰壶的识别检测方法基于Haar的特征检测
- 结合Scikit-learn介绍几种常用的特征选择方法
- 机器学习中的特征——特征选择的方法以及注意点
- 推荐系统那点事 —— 基于Spark MLlib的特征选择
- 基于运动特征的视频质量评价方法(基于H.264)
- 特征选择方法之信息增益
- 文本分类入门-特征选择方法之信息增益
- 1 - 基于卡方检验的特征选择
- 特征选择方法之信息增益
- 【机器学习】在工程上机器学习特征选择的方法
- 一些常见的特征选择方法
- 文本分类入门(十一)特征选择方法之信息增益