Java进阶之HashMap工作原理(旧)
2016-12-27 16:37
453 查看
1 参考链接
HashMap的工作原理HashMap对HashCode碰撞的处理
并发读写缓存实现机制(一):为什么ConcurrentHashMap可以这么快?
2 HashMap简介
2.1 HashMap是什么
HashMap基于哈希表的Map接口的实现,此实现提供所有可选的Map操作,并允许使用 null 值和 null 键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。HashMap的实例有两个参数影响其性能:初始容量和加载因子。容量是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行rehash操作(重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常默认加载因子(.75)在时间和空间成本上寻求一种折衷。加载因子过高虽然减小了空间开销,但是同时也增加了查询成本。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少rehash操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生rehash操作。
如果很多映射关系要存储到HashMap实例中,则相对于按需执行自动的rehash操作以增大表的容量来说,使用足够大的初始化容量创建它将使得映射关系能够更有效的存储。
注意,此实现不是同步。如果多个线程同时访问同一个HashMap,而其中至少一个线程从结构上修改了该映射(增删映射关系),则它必须保持外部同步。这一般通过对自然封装该映射的对象进行同步操作来完成。如果不存在这样的对象,则应该使用Collections.synchronizedMap方法来“包装”该映射。最好在创建时完成这一操作,防止对映射进行意外的非同步访问。
2.2 HashMap的存储结构
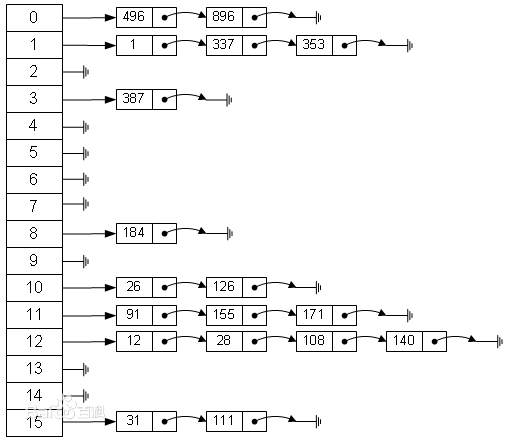
由下图可以看出哈希表是一个数组+链表的存储结构。HashMap存储结构文字解释:元素0 →[hashCode=1,Entry<K,V>] 元素1 →[hashCode=2,Entry<K,V>]
2.3 HashTable是什么
哈希表(Hashtable)又称为“散置”,Hashtable是会根据索引键的哈希程序代码组织成的索引键(Key)和值(Value)配对的集合Hashtable对象是由包含集合中元素的哈希桶(Bucket)所组成的。而Bucket是Hashtable内元素的虚拟子群组,可以让大部分集合中的搜寻和获取工作更容易、更快速。2.4 HashMap和HashTable的区别
2.4.1 主要区别
(1)HashMap是非线程同步的,HashTable是线程同步的。(2)HashMap允许null作为键或者值,HashTable不允许
(3)HashMap去掉了contains方法,HashTable中有此方法,
(4)效率上来讲,HashMap因为是非线程安全的,因此效率比HashTable高
2.4.2 源码对比
// 从定义上看,hashTable继承Dictionary,而HashMap继承Abstract public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable
// hashMap的put、get方法源码:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
}
// hashTable的put()、get()方法源码:
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
}从源码中可以看出hashTable实现了synchronized,并不允许null作为键值。
3 HashMap对HashCode碰撞的处理
3.1 拉链法解决冲突
拉链法解决冲突的做法:HashCode是使用Key通过Hash函数计算出来的,由于不同的Key,通过此Hash函数可能会算的同样的HashCode,所以此时用了拉链法解决冲突,把HashCode相同的Value连成链表. 但是get的时候根据Key又去桶里找,如果是链表说明是冲突的,此时还需要检测Key是否相同。3.2 详细解析
详细解释下,Java中HashMap是利用“拉链法”处理HashCode的碰撞问题。在调用HashMap的put方法或get方法时,都会首先调用hashcode方法,去查找相关的key,当有冲突时,再调用equals方法。hashMap基于hasing原理,我们通过put和get方法存取对象。当我们将键值对传递给put方法时,他调用键对象的hashCode()方法来计算hashCode,然后找到bucket(哈希桶)位置来存储对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当碰撞发生了,对象将会存储在链表的下一个节点中。hashMap在每个链表节点存储键值对对象。当两个不同的键却有相同的hashCode时,他们会存储在同一个bucket位置的链表中。键对象的equals()来找到键值对。HashMap的put和get方法源码如下:/**
* Returns the value to which the specified key is mapped,
* or if this map contains no mapping for the key.
*
* 获取key对应的value
*/
public V get(Object key) {
if (key == null)
return getForNullKey();
//获取key的hash值
int hash = hash(key.hashCode());
// 在“该hash值对应的链表”上查找“键值等于key”的元素
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
/**
* Offloaded version of get() to look up null keys. Null keys map
* to index 0.
* 获取key为null的键值对,HashMap将此键值对存储到table[0]的位置
*/
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
/**
* Returns <tt>true</tt> if this map contains a mapping for the
* specified key.
*
* HashMap是否包含key
*/
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
/**
* Returns the entry associated with the specified key in the
* HashMap.
* 返回键为key的键值对
*/
final Entry<K,V> getEntry(Object key) {
//先获取哈希值。如果key为null,hash = 0;这是因为key为null的键值对存储在table[0]的位置。
int hash = (key == null) ? 0 : hash(key.hashCode());
//在该哈希值对应的链表上查找键值与key相等的元素。
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* 将“key-value”添加到HashMap中,如果hashMap中包含了key,那么原来的值将会被新值取代
*/
public V put(K key, V value) {
//如果key是null,那么调用putForNullKey(),将该键值对添加到table[0]中
if (key == null)
return putForNullKey(value);
//如果key不为null,则计算key的哈希值,然后将其添加到哈希值对应的链表中
//hash值可以说hashcode()返回的是分配存储区域的地址,hash运算也是为了散列表分布更加均匀。
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果这个key对应的键值对已经存在,就用新的value代替老的value。
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}4 关于hashMap的其他问题
(1)为什么String, Interger这样的wrapper类适合作为键?HashMap的键尽量使用String、Integer这样的包装类。因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的包装类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。如果你可以仅仅通过将某个field声明成final就能保证hashCode是不变的,那么请这么做吧。因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
(2)我们可以使用自定义的对象作为键吗?
我们可以利用自己的对象作为键,只要它遵守了equals()和hashCode()方法的定义规则。
(3)我们可以使用CocurrentHashMap来代替Hashtable吗?
我们知道Hashtable是synchronized的,但是ConcurrentHashMap同步性能更好,因为它仅仅根据同步级别对map的一部分进行上锁。ConcurrentHashMap当然可以代替HashTable,但是HashTable提供更强的线程安全性。
(4)多线程条件下,重调整hashMap大小会出现什么问题?
当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。
5 总结
HashMap的工作原理:HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表(拉链法)来解决hashCode碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。如果两个不同的键对象的hashCode相同,那么它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。由于HashMap的种种好处,我们经常可以利用hashMap作为缓存。

相关文章推荐
- Java HashMap的工作原理
- java HashMap的工作原理
- Java HashMap工作原理深入探讨
- 从头认识java-15.7 Map(2)-介绍HashMap的工作原理-put方法
- 【转】Java HashMap工作原理(好文章)
- java进阶(4)集合类:ArrayList和 LinkedList,Vector 和stack,HashMap的基本用法
- 从头认识java-15.7 Map(6)-介绍HashMap的工作原理-装载因子与性能
- [翻译]Java HashMap工作原理
- Java面试题-->HashMap的工作原理
- 从头认识java-15.7 Map(4)-介绍HashMap的工作原理-hash碰撞(经常作为面试题)
- Java HashMap的工作原理
- Java集合学习:HashMap的实现原理和工作原理
- Java HashMap的工作原理
- Java HashMap工作原理深入探讨
- Java HashMap的工作原理
- Java HashMap的工作原理
- java HashMap的工作原理
- Java HashMap的工作原理
- Java HashMap工作原理
- 从头认识java-15.7 Map(5)-介绍HashMap的工作原理-Key变了,能不能get出原来的value?(偶尔作为面试题)