HBase RegionLoad获取Name乱码问题的源码分析与解决方式
2016-12-25 22:34
656 查看
版权声明:本文为博主原创文章,转载自http://blog.csdn.net/t894690230/article/details/53037708
目录(?)[+]
由于每次抓取的Region数量在一两万左右,所以在开始获取RegionLoad中的数据时,并没有太关注regionName是否乱码(只有少部分regionName乱码,其中大多是由phoenix引起的,并且在数据库中乱码的数据有可能会被截断),后来需要获取HRegionInfo中的数据时,尝试使用regionName进行一一对应匹配,却很多都无法匹配上。
2
3
1
2
3
HRegionInfo.getRegionNameAsString()源码如下:
2
3
4
5
6
7
8
9
10
11
1
2
3
4
5
6
7
8
9
10
11
regionName在RegionLoad与HRegionInfo对象中都是以byte[]方式存储的,在调用**NameAsString()方法时,通过org.apache.Hadoop.Hbase.util.Bytes类中的方法进行转换,但是RegionLoad.getNameAsString()是通过Bytes.toString(…),而HRegionInfo.getRegionNameAsString()是通过Bytes.toStringBinary(…),两个方法的源码如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
其中,Bytes.toString(…)只是单纯的将字节数组按照UTF-8编码的方式进行转换,这就导致很多一些不存在于UTF-8编码中的特殊字符是无法显示的,或显示成了莫名其妙的符号,而这些无法显示的或莫名奇妙的符号在数据库中却很可能是无法保存的(SQL SERVER中,‘\x00’代表的字符会被认为是截断,其后的数据都无法保存,粘贴在SQL窗口都不行),而Bytes.toStringBinary(…)中,则将那些无法乱七八糟的字符以\x%02X(%02X会被替换成2位字符组成的字符串,类似但会超出16进制的表示范围)显示,所以我们能看到像下面的这种名称:
1
像’$’这种能正常显示的也就显示了,而‘\x00’则代表了一种特殊的可能无法显示的字符(这里是NULL),具体的对应关系可参见下表:
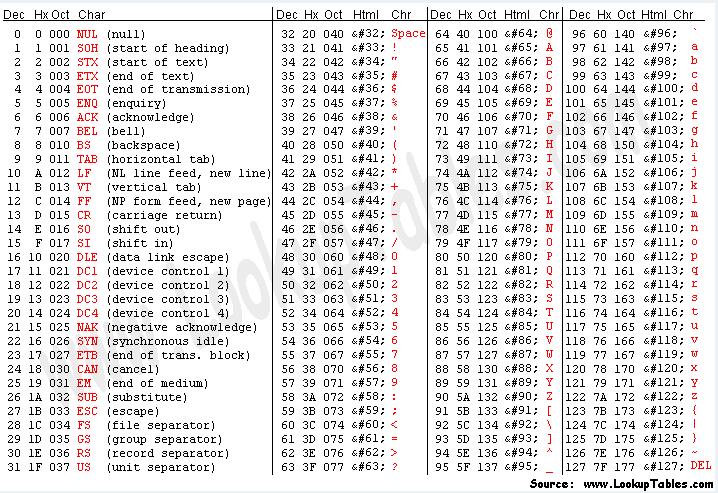
(图片来源:http://www.asciitable.com/)
其中,\x%02X中的%02X对应Hx列。
1
此时,再对比通过RegionLoad与HRegionInfo对象获取的regionName时,便能一一对应了,并且不会乱码了。
以上。
目录(?)[+]
一、问题的产生
通过RegionLoad可以获得一系列有关Region负载的详细信息,但是因为需要通过regionName与HRegionInfo中的regionName匹配,从而合并相关信息(保存的时候没有保存字节数组的regionName,太长了并且不直观,同时还需要clusterName信息,以保证其唯一性),所以也正因为如此,才带来了标题中的问题。由于每次抓取的Region数量在一两万左右,所以在开始获取RegionLoad中的数据时,并没有太关注regionName是否乱码(只有少部分regionName乱码,其中大多是由phoenix引起的,并且在数据库中乱码的数据有可能会被截断),后来需要获取HRegionInfo中的数据时,尝试使用regionName进行一一对应匹配,却很多都无法匹配上。
二、原因分析
RegionLoad提供了getNameAsString()方法获取regionName,同时HRegionInfo也提供了getRegionNameAsString()方法获取regionName,从方法名上看两个方法似乎没有差异,但是查看源码就会发现两个方法其实是不一样的,RegionLoad.getNameAsString()源码如下:public String getNameAsString() {
return Bytes.toString(getName());
}12
3
1
2
3
HRegionInfo.getRegionNameAsString()源码如下:
public String getRegionNameAsString() {
if (hasEncodedName(this.regionName)) {
// new format region names already have their encoded name.
return Bytes.toStringBinary(this.regionName);
}
// old format. regionNameStr doesn't have the region name.
//
//
return Bytes.toStringBinary(this.regionName) + "." + this.getEncodedName();
}12
3
4
5
6
7
8
9
10
11
1
2
3
4
5
6
7
8
9
10
11
regionName在RegionLoad与HRegionInfo对象中都是以byte[]方式存储的,在调用**NameAsString()方法时,通过org.apache.Hadoop.Hbase.util.Bytes类中的方法进行转换,但是RegionLoad.getNameAsString()是通过Bytes.toString(…),而HRegionInfo.getRegionNameAsString()是通过Bytes.toStringBinary(…),两个方法的源码如下:
public static String toString(final byte [] b) {
if (b == null) {
return null;
}
return toString(b, 0, b.length);
}
public static String toString(final byte [] b, int off, int len) {
if (b == null) {
return null;
}
if (len == 0) {
return "";
}
return new String(b, off, len, UTF8_CHARSET); // UTF8_CHARSET = "UTF-8"
}12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public static String toStringBinary(final byte [] b) {
if (b == null)
return "null";
return toStringBinary(b, 0, b.length);
}
public static String toStringBinary(final byte [] b, int off, int len) {
StringBuilder result = new StringBuilder();
// Just in case we are passed a 'len' that is > buffer length...
if (off >= b.length) return result.toString();
if (off + len > b.length) len = b.length - off;
for (int i = off; i < off + len ; ++i ) {
int ch = b[i] & 0xFF;
if ( (ch >= '0' && ch <= '9')
|| (ch >= 'A' && ch <= 'Z')
|| (ch >= 'a' && ch <= 'z')
|| " `~!@#$%^&*()-_=+[]{}|;:'\",.<>/?".indexOf(ch) >= 0 ) {
result.append((char)ch);
} else {
result.append(String.format("\\x%02X", ch));
}
}
return result.toString();
}12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
其中,Bytes.toString(…)只是单纯的将字节数组按照UTF-8编码的方式进行转换,这就导致很多一些不存在于UTF-8编码中的特殊字符是无法显示的,或显示成了莫名其妙的符号,而这些无法显示的或莫名奇妙的符号在数据库中却很可能是无法保存的(SQL SERVER中,‘\x00’代表的字符会被认为是截断,其后的数据都无法保存,粘贴在SQL窗口都不行),而Bytes.toStringBinary(…)中,则将那些无法乱七八糟的字符以\x%02X(%02X会被替换成2位字符组成的字符串,类似但会超出16进制的表示范围)显示,所以我们能看到像下面的这种名称:
SYSTEM.SEQUENCE,$\x00\x00\x00,1462415795146.fdbe7e16cba9380494f07a61ac465879.1
1
像’$’这种能正常显示的也就显示了,而‘\x00’则代表了一种特殊的可能无法显示的字符(这里是NULL),具体的对应关系可参见下表:
(图片来源:http://www.asciitable.com/)
其中,\x%02X中的%02X对应Hx列。
三、解决方案
那么至此,问题也就好解决了,只要在使用RegionLoad获取regionName时使用如下方法:String regionName = Bytes.toStringBinary(regionLoad.getName());1
1
此时,再对比通过RegionLoad与HRegionInfo对象获取的regionName时,便能一一对应了,并且不会乱码了。
以上。

相关文章推荐
- HBase RegionLoad获取Name乱码问题的源码分析与解决方式
- 获取Android源码时如何解决【fatal: Unable to look up android.git.kernel.org (port 9418) (Name or service not known)】的问题
- hbase无法启动Regionserver:ClassNotFoundException: org.apache.hadoop.util.PlatformName问题解决
- 三种方式--JS/JSP/EL 解决在JSP中获取cookie中文乱码的问题
- <util:properties/>加载的配置文件中有中文导致乱码,如何通过分析源码解决问题?
- 关于UTF-8的客户端用AJAX方式获取GB2312的服务器端乱码问题的解决办法
- 解决以GET方式获取中文时乱码问题
- 日常问题记录--JSP页面中通过<s:property value="#parameters.userName[0]>获取URL参数中文时为乱码的解决办法
- 关于UTF-8的客户端用AJAX方式获取GB2312的服务器端乱码问题的解决办法
- 解决以GET方式获取中文时乱码问题
- 关于UTF-8的客户端用AJAX方式获取GB2312的服务器端乱码问题的解决办法
- http协议4---GET方式和POST方式获取表单数据举例3(统一方式获取,解决中文乱码问题)
- VC6中cpp文件源码中出现中文乱码问题的解决办法
- CString与char[] 的相互转换方法以及结尾乱码问题的分析解决
- Linux下mp3标签乱码问题的分析和解决
- jspsmartupload乱码问题(修改源码的解决办法)
- 解决表单get方式提交时的中文乱码问题
- 解决乱码问题的最佳解决方式(struts struts2 jsp servlet action等)
- CString与char[] 的相互转换方法以及结尾乱码问题的分析解决
- C#访问数据库时中文乱码问题分析及解决