基于SVM和KNN的手写数字的识别(分类)——小试牛刀篇
2016-12-23 20:03
901 查看
数据下载地址:http://download.csdn.net/detail/zhulf0804/9719836
下面分别采用的是k近邻算法(KNN)和SVM实现的手写数字识别。
python实现代码:
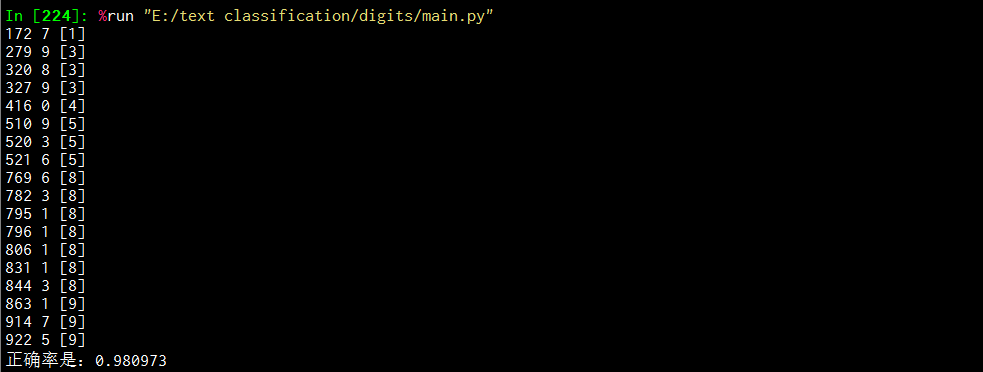
运行结果如下图:
输出的每一行表示分类错误的数据,每一行的第1列是测试集的id,第2列是KNN算法分类的结果,第三列是正确的分类结果。
svm实现手写字体分类,代码如下:
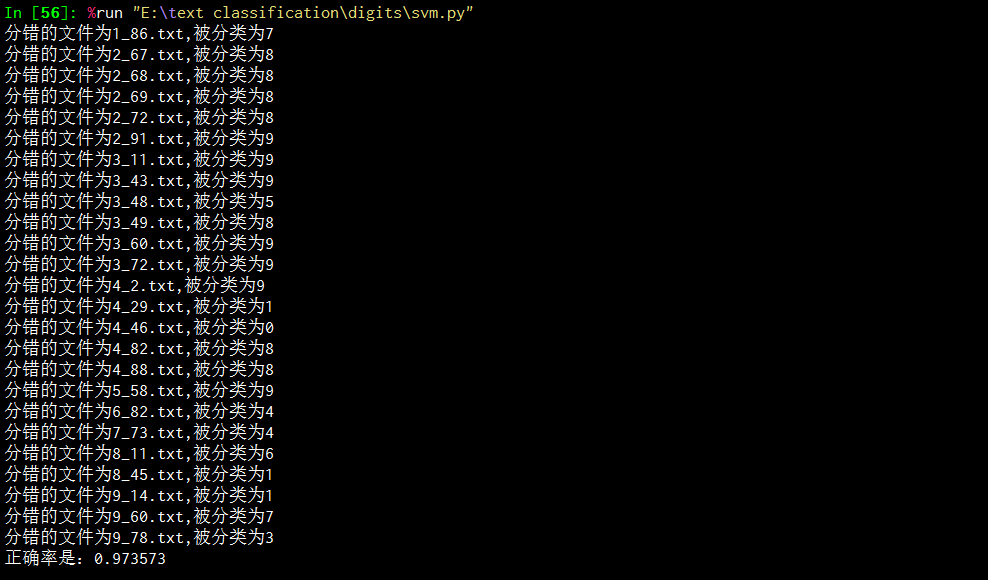
运行结果:
参考资料:
1、机器学习实战
2、http://scikit-learn.org/stable/modules/svm.html#svm
下面分别采用的是k近邻算法(KNN)和SVM实现的手写数字识别。
python实现代码:
# -*- coding: utf-8 -*-
import os
import numpy as np
def img2vector(filename, label): #图像数据转为向量
f = open(filename,'r')
row_data = f.read()
row_data = row_data.replace('\n','') #换行符转为空格
row_data = row_data + label
row_data = np.array(map(int, list(row_data))) #将string转为np.array
return row_data
#k紧邻(KNN)分类算法
def classify0(rowX, dataSet, k):
'''
rowX是待分类的向量, dataSet是标记好的训练集, k表示选择最近邻居的数目
'''
#距离计算:绝对值距离
dataSetSize = dataSet.shape[0]
#print dataSetSize
rowMat = np.zeros((dataSetSize, 1025), np.int)
for i in range(dataSetSize):
rowMat[i] = rowX
diffMat = rowMat - dataSet
label0 = dataSet[:,1024] #取出训练集label
diffMat2 = diffMat[:,0:1024] #差分矩阵去除label列
diffMat3 = diffMat2**2 #差分矩阵的平方,即是绝对值
dis = diffMat3.sum(axis = 1) #沿行求和,即是该待分类向量与训练集中每条数据的距离
#选择距离最小的k个点
sortedIndice = dis.argsort()
#print sortedIndice
vote_label = np.zeros((1,10), np.int)
for i in range(k):
label= label0[sortedIndice[i]] #获取第i小距离的label
vote_label[0,label] = vote_label[0,label] + 1
sorted_vote = vote_label.argsort()
#print sorted_vote
return sorted_vote[0,9]
#将训练集数据存储到np数组train_data中
train_dir = 'trainingDigits\\'
train_filename = os.listdir(train_dir) #获取trainingDigits目录下的文件名
m = len(train_filename)
train_data = np.zeros((m,1025), np.int)
for i in range(0, m):
label = train_filename[i].split('_')[0]
row = img2vector(train_dir + train_filename[i], label)
train_data[i] = row
#将测试集数据存储到np数组test_data中
test_dir = 'testDigits\\'
test_filename = os.listdir(test_dir) #获取trainingDigits目录下的文件名
m = len(test_filename)
test_data = np.zeros((m,1025), np.int)
test_result = np.zeros((m,1),np.int)
for i in range(0, m):
label = test_filename[i].split('_')[0]
test_result[i] = int(label) #存储测试集正确的分类
row = img2vector(test_dir + test_filename[i], '0') #测试集初始分类设置为0
test_data[i] = row
cc = 0
for i in range(m):
ll = classify0(test_data[i], train_data, 5)
#print ll,test_result[i]
if ll == test_result[i]:
cc = cc + 1
else:
print i,ll,test_result[i]
print '正确率是:%f' %(float(cc)/float(m))运行结果如下图:
输出的每一行表示分类错误的数据,每一行的第1列是测试集的id,第2列是KNN算法分类的结果,第三列是正确的分类结果。
svm实现手写字体分类,代码如下:
# -*- coding: utf-8 -*-
import os
from sklearn import svm
def img2vector(filename): #图像数据转为list
f = open(filename,'r')
row_data = f.read()
row_data = row_data.replace('\n','') #换行符转为空格
row_data = list(row_data)
for i in range(len(row_data)):
row_data[i] = int(row_data[i])
return row_data
train_dir = 'trainingDigits\\'
train_filename = os.listdir(train_dir) #获取trainingDigits目录下的文件名
m = len(train_filename)
X = []
Y = []
for i in range(0, m):
label = train_filename[i].split('_')[0]
Y.append(int(label))
row = img2vector(train_dir + train_filename[i])
X.append( row )
clf = svm.SVC(decision_function_shape='ovo')
clf.fit(X, Y)
test_dir = 'testDigits\\'
test_filename = os.listdir(test_dir) #获取trainingDigits目录下的文件名
m = len(test_filename)
X_test = []
Y_test = []
for i in range(0, m):
label = test_filename[i].split('_')[0]
Y_test.append(int(label)) #存储测试集正确的分类
row = img2vector(test_dir + test_filename[i])
X_test.append(row)
ans = clf.predict(X_test)
cc = 0
ll = len(ans)
for i in range(ll):
if Y_test[i] == ans[i]:
cc +=1
else:
print "分错的文件为%s,被分类为%d" %(test_filename[i],ans[i])
print '正确率是:%f' % (1.0*cc/ll)运行结果:
参考资料:
1、机器学习实战
2、http://scikit-learn.org/stable/modules/svm.html#svm

相关文章推荐
- opencv 基于KNN的手写数字字符识别
- SVM和Knn实现手写数字识别
- 基于k近邻(KNN)的手写数字识别
- 基于opencv的手写数字识别(MFC,HOG,SVM)
- 基于KNN的手写数字识别
- 基于qt和opencv3实现机器学习之:利用最近邻算法(knn)实现手写数字分类
- 基于SVM手写数字识别
- python实现基于SVM手写数字识别功能
- [机器学习案例1]基于KNN手写数字识别
- [机器学习案例1]基于KNN手写数字识别
- 编程实践--KNN分类算法--手写数字识别任务
- KNN分类算法实现手写数字识别
- 基于opencv的手写数字识别(MFC,HOG,SVM)
- SVM对手写数字的识别
- 【好玩的计算机视觉】KNN算法手写数字识别
- 基于Opencv库中SVM模块的MNIST手写字识别数据库识别
- 基于神经网络和遗传算法的【手写数字识别】机器人的实现
- 基于tensorflow的MNIST手写数字识别(二)--入门篇
- opencv实现KNN手写数字的识别
- knn-2 利用knn算法实现手写数字识别