Keepalived+Lvs_DR模式实现Web服务的HA高可用集群
2016-12-23 09:56
876 查看
Keepalived基于VRRP协议实现LVS服务的高可用集群,可以利用其来避免单点故障。一个LVS服务会有2台服务器运行Keepalived,一台为主服务器(MASTER),一台为备份服务器(BACKUP),但是对外表现为一个虚拟IP,主服务器会发送特定的消息给备份服务器,当备份服务器收不到这个消息的时候,即主服务器宕机的时候, 备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性。Keepalived是VRRP的完美实现,因此在介绍keepalived之前,先介绍一下VRRP的原理。在现实的网络环境中,两台需要通信的主机大多数情况下并没有直接的物理连接。对于这样的情况,它们之间路由怎样选择?主机如何选定到达目的主机的下一跳路由,这个问题通常的解决方法有二种:在主机上使用动态路由协议(RIP、OSPF等)在主机上配置静态路由很明显,在主机上配置动态路由是非常不切实际的,因为管理、维护成本以及是否支持等诸多问题。配置静态路由就变得十分流行,但路由器(或者说默认网关default gateway)却经常成为单点故障。VRRP的目的就是为了解决静态路由单点故障问题,VRRP通过一竞选(election)协议来动态的将路由任务交给LAN中虚拟路由器中的某台VRRP路由器。VRRP(Virtual Router Redundancy Protocol,虚拟路由冗余协议)是一种容错协议在一个VRRP虚拟路由器中,包含多台物理路由器,但是这多台的物理的器并不能同时工作,而是由一台称为MASTER的负责路由工作,其它的都是BACKUP,MASTER并非一成不变,VRRP让每个VRRP路由器参与竞选,最终获胜的就是MASTER。MASTER拥有一些特权,比如,拥有虚拟路由器的IP地址,我们的主机就是用这个IP地址作为静态路由的。拥有特权的MASTER要负责转发发送给网关地址的包和响应ARP请求。VRRP通过竞选协议来实现虚拟路由器的功能,所有的协议报文都是通过IP多播(multicast)包(多播地址224.0.0.18)形式发送的。虚拟路由器由VRID(范围0-255)和一组IP地址组成,对外表现为一个相同的MAC地址。所以,在一个虚拟路由 器中,不管谁是MASTER,对外都是相同的MAC(会进行arp欺骗)和IP(称之为VIP)。客户端主机并不需要因为MASTER的改变而修改自己的路由配置,对客户端来说,这种主从的切换是隐藏的。在一个虚拟路由器中,只有作为MASTER的VRRP路由器会一直发送VRRP通告信息(VRRPAdvertisement message),BACKUP不会抢占MASTER,除非它的优先级(priority)更高。当MASTER不可用时(BACKUP收不到通告信息), 多台BACKUP中优先级最高的这台会被抢占为MASTER。这种抢占是非常快速的(<1s),以保证服务的连续性。由于安全性考虑,VRRP包使用了加密协议进行加密。下面将开始用Keepalived+lvS构建一个Web高可用集群node1:192.168.139.2 主DR_Servernode2:192.168.139.4 备DR_servernode4:192.168.139.8 RS1_Servernode5:192.168.139.9 RS2_Servernode1,node2装keepalived,ipvsadmnode4,node5装httpd因为每个节点都有VIP,但进行ARP响应时必须只能有Director上的VIP响应(要是VIP所在网卡都响应ARP广播就乱了,因为每个节点都有VIP),所以RS上的VIP必须隐藏起来让其不进行ARP响应。为了让RS上的VIP隐藏起来,必须对RS进行如下设置 echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore cho 1 > /proc/sys/net/ipv4/conf/all/arp_ignore直接用下面的脚本设置RS_Server的环境,更详细的LVS_DR模式介绍请看:http://11107124.blog.51cto.com/11097124/1867364 [root@node4 sh]# vim rs.sh#!/bin/bash#VIP=192.168.139.100STATUS() { if [ -e /var/lock/subsys/ipvs_lock ] ;then echo -e "\033[40;31m initial OK \033[0m " else echo -e "\033[40;31m initial not ok \033[0m " fi }case $1 instart) /sbin/ifconfig lo down /sbin/ifconfig lo up echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce /sbin/ifconfig lo:0 $VIP broadcast $VIP netmask 255.255.255.255 up /sbin/route add -host $VIP dev lo:0 /bin/touch /var/lock/subsys/ipvs_lock ;;stop) /sbin/ifconfig lo:0 down /sbin/route del $VIP &> /dev/null echo 0 > /proc/sys/net/ipv4/conf/lo/arp_ignore echo 0 > /proc/sys/net/ipv4/conf/all/arp_ignore echo 0 > /proc/sys/net/ipv4/conf/lo/arp_announce echo 0 > /proc/sys/net/ipv4/conf/all/arp_announce /bin/rm -f /var/lock/subsys/ipvs_lockstatus) STATUS;;*) echo "Usage: `basename $0` START|STOP" exit 7esacnode4,node5执行此脚本,设置LVS_DR模式的准备环境[root@node1 keepalived]# chmod +x notify.sh[root@node4 sh]# bash rs.sh start[root@node4 sh]# bash rs.sh start[root@node4 sh]# ifconfig eth0 inet addr:192.168.139.8 Bcast:192.168.139.255 Mask:255.255.255.0lo inet addr:127.0.01 Mask:255.0.0.0lo:0 inet addr:192.168.139.6 Mask:255.255.255.255 [root@node4 sh]# route -nDestination Gateway Genmask Flags Metric Ref Use Iface192.168.139.6 0.0.0.0 255.255.255.255 UH 0 0 0 lo[root@node4 ~]# service httpd start[root@node5 ~]# service httpd start[root@node4 sh]# netstat -tnlp |grep 80tcp 0 0 :::80 :::* LISTEN 3047/httpd至此RS1,RS2已经准备好,node1和node2装软件[root@node1 ~]# yum install keepalived ipvsadm -y[root@node2 mail]# yum install keepalived ipvsadm -y[root@node1 ~]# cd /etc/keepalived/编辑之前最好先备份[root@node1 keepalived]# cp keepalived.conf keepalived.conf.bak[root@node1 keepalived]# vim keepalived.conf! Configuration File for keepalivedglobal_defs { 此段定义全局默认配置 notification_email { root@localhost #写入你的邮件地址,出现故障给你发邮件 } notification_email_from keeepalived@localhost#邮件由本地谁发出 smtp_server 127.0.0.1 #本地smtp-server smtp_connect_timeout 30 #smtp连接超时时间 router_id LVS_DEVEL }vrrp_instance VI_1 { state MASTER #当前节点为主节点 interface eth0 #通告信息及虚拟路由工作的网卡接口 virtual_router_id 51 #要与备份节点上ID一样 priority 101 #优先级为101,要比备份节点的大 advert_int 1 #每隔一秒发一次通告信息 authentication { auth_type PASS #pass为简单字符认证,发送的通告信息要认证通过才接受通过信息 auth_pass keepalived #随便给个字符串 } virtual_ipaddress { 192.168.139.100/24 dev eth0 label eth0:0 #VIP/掩码 设备 标签 }}virtual_server 192.168.139.100 80 { 此段定义DR_Server delay_loop 6 lb_algo wrr #DR算法为wrr lb_kind DR #lvs类型为DR nat_mask 255.255.255.0 #网络掩码 # persistence_timeout 50 #持久连接时间,本实验不用 protocol TCP #协议为TCPreal_server 192.168.139.8 80 { 本段定义RS_Server weight 2 #192.168.139.8节点权重为2 HTTP_GET { #对http协议做健康状态检查 url { path / status_code 200 #如果正常,状态码返回200 } connect_timeout 2 #连接超时2S nb_get_retry 3 #重试此时为3 delay_before_retry 1 #每次重试隔1S } } real_server 192.168.139.9 80 { weight 1 HTTP_GET { url { path / status_code 200 } connect_timeout 2 nb_get_retry 3 delay_before_retry 1 } }}更多详细参数,请man [root@node1 keepalived]# man keepalived.conf复制到node2 [root@node1 keepalived]#scp keepalived.conf node2:/etc/keepalived/ [root@node2 keepalived]# vim keepalived.conf 改 MASTER->BACKUP priority 101->100 weight 1->2 (如果是rr算法,权重就没用)[root@node1 keepalived]# service keepalived start[root@node2 keepalived]# service keepalived start[root@node1 keepalived]# ifconfig eth0 Link encap:Ethernet HWaddr 00:0C:29:1C:13:12 inet addr:192.168.139.2 Bcast:192.168.139.255 Mask:255.255.255.0 eth0:0 Link encap:Ethernet HWaddr 00:0C:29:1C:13:12 inet addr:192.168.139.100 Bcast:0.0.0.0 Mask:255.255.255.0 lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 [root@node1 keepalived]# ipvsadm -l -nIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 192.168.139.100:80 wrr -> 192.168.139.8:80 Route 1 0 0 -> 192.168.139.9:80 Route 1 0 0 浏览器测试: 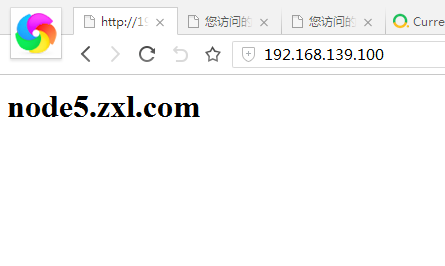 刷新
刷新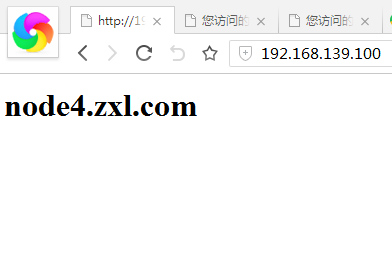 集群工作正常[root@node4 sh]# service httpd stop停掉一个节点服务,则会立马有邮件通知给管理员node4节点DOWN了[root@node1 keepalived]# mail>N 17 keeepalived@localhos Thu Dec 22 17:54 17/625 "[LVS_DEVEL] Realserver [192.168.139.8]:80 - DOWN"& Message 17:From keeepalived@localhost.zxl.com Thu Dec 22 17:54:32 2016Return-Path: <keeepalived@localhost.zxl.com>X-Original-To: root@localhostDelivered-To: root@localhost.zxl.comDate: Thu, 22 Dec 2016 09:54:32 +0000From: keeepalived@localhost.zxl.comSubject: [LVS_DEVEL] Realserver [192.168.139.8]:80 - DOWNX-Mailer: KeepalivedTo: root@localhost.zxl.comStatus: R=> CHECK failed on service : connection error <=node5节点被移除了[root@node1 keepalived]# ipvsadm -l -nIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 192.168.139.100:80 wrr -> 192.168.139.9:80 Route 1 0 0 [root@node4 sh]# service httpd startnode5节点又被加入了集群[root@node1 keepalived]# ipvsadm -l -nIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 192.168.139.100:80 wrr -> 192.168.139.8:80 Route 1 0 0 -> 192.168.139.9:80 Route 1 0 0 但是万一两个RS都挂掉怎么办?在node1和node2上装httpd(因为VIP可能会在两个节点转移,所两个节点都要装),将其做成fall_back_server,一旦两个RS挂掉,则提供一个临时页面,通知用户node1 node2都进行如下操作[root@node1 keepalived]# yum install httpd -y[root@node1 ~]# vim /var/www/html/index.html<h1>服务器维护中</h1>[root@node1 ~]# service httpd start[root@node1 keepalived]# vim keepalived.conf在virtual_server中加入 sorry_server 127.0.0.1 80[root@node1 keepalived]# service keepalived restart[root@node2 keepalived]# service keepalived restart [root@node4 sh]# service httpd stop[root@node5 ~]# service httpd stop可以看到Local 127.0.0.1上线[root@node1 keepalived]# ipvsadm -l -nIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 192.168.139.100:80 wrr -> 127.0.0.1:80 Local 1 0 0浏览器测试,node4 node5都挂了后由运行有VIP的DR提供维护页面[root@node4 sh]# service httpd start只要有一个RS在线,Local server就会下线 [root@node1 keepalived]# ipvsadm -l -nIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 192.168.139.100:80 wrr -> 192.168.139.8:80 Route 1 1 0 [root@node5 ~]# service httpd start写一个检测脚本,完成DR的切换,直接编辑文件[root@node1 ~]# vim /etc/keepalived/keepalived.confvrrp_script chk_down { 定义一个叫chk_down的脚本检查DR_Serverscript "[ -e /etc/keepalived/down ] && exit 1 || exit 0 " \\当/etc/keepalived/down \\ 文件存在时则检查失败,否则成功(只有返回值为0,才表示成 \\功),次数还可以通过文件设置复杂检测脚本,而不止一个命令 interval 2 \\每隔2秒监测一次 weight -2 \\如果监测为失败则此节点priority减去2(如node1由101变成99小于node2 \\的100则变为备节点) fall 2 \\只有连续监测两次都失败才证明此DR真的挂了 rise 1 \\只要有一次监测成功则此DR没有挂 }vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 101 advert_int 1 authentication { auth_type PASS auth_pass keepalived } virtual_ipaddress { 192.168.139.100/24 dev eth0 label eth0:0 } track_script { chk_down \\这里定义执行上面写的chk_down脚本}}编辑node2,重启服务[root@node2 ~]# vim /etc/keepalived/keepalived.conf[root@node1 ~]# service keepalived restart[root@node2 ~]# service keepalived restart[root@node1 ~]# cd /etc/keepalived/创建down文件从node1转移到node2,node1变成备节点[root@node1 keepalived]# touch down[root@node1 keepalived]# ifconfig eth0 Link encap:Ethernet HWaddr 00:0C:29:1C:13:12 inet addr:192.168.139.2 Bcast:192.168.139.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe1c:1312/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:18158 errors:0 dropped:0 overruns:0 frame:0 TX packets:18798 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:3011063 (2.8 MiB) TX bytes:3830969 (3.6 MiB)lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:155 errors:0 dropped:0 overruns:0 frame:0 TX packets:155 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:11194 (10.9 KiB) TX bytes:11194 (10.9 KiB)可以看到eth0:0(VIP)从本机转移了,查看一下日志描述[root@node1 keepalived]# tail /var/log/messagesDec 22 18:31:43 node1 Keepalived_vrrp[2107]: VRRP_Script(chk_down) failed检测失败Dec 22 18:31:44 node1 Keepalived_vrrp[2107]: VRRP_Instance(VI_1) Received higher prio advert收到更高的优先级(node1优先级由101-2=99小于node2的100)Dec 22 18:31:44 node1 Keepalived_vrrp[2107]: VRRP_Instance(VI_1) Entering BACKUP STATEnode1转换为备节点Dec 22 18:31:44 node1 Keepalived_vrrp[2107]: VRRP_Instance(VI_1) removing protocol VIPs.移除VIPDec 22 18:31:44 node1 Keepalived_healthcheckers[2106]: Netlink reflector reports IP 192.168.139.100 removedVIP在node2已经设置[root@node2 ~]# ifconfig eth0 Link encap:Ethernet HWaddr 00:0C:29:5F:68:2F inet addr:192.168.139.4 Bcast:192.168.139.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe5f:682f/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:21023 errors:0 dropped:0 overruns:0 frame:0 TX packets:20015 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:3081886 (2.9 MiB) TX bytes:2313640 (2.2 MiB)eth0:0 Link encap:Ethernet HWaddr 00:0C:29:5F:68:2F inet addr:192.168.139.100 Bcast:0.0.0.0 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:226 errors:0 dropped:0 overruns:0 frame:0 TX packets:226 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:21401 (20.8 KiB) TX bytes:21401 (20.8 KiB)[root@node2 ~]# tail /var/log/messagesDec 22 18:30:42 node2 Keepalived_vrrp[5295]: VRRP_Script(chk_down) succeeded检测成功Dec 22 18:31:47 node2 Keepalived_vrrp[5295]: VRRP_Instance(VI_1) Transition to MASTER STATE转换为主节点Dec 22 18:31:48 node2 Keepalived_vrrp[5295]: VRRP_Instance(VI_1) setting protocol VIPs.设置VIPDec 22 18:31:48 node2 Keepalived_healthcheckers[5294]: Netlink reflector reports IP 192.168.139.100 addedVIP添加成功Dec 22 18:31:48 node2 Keepalived_vrrp[5295]: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth0 for 192.168.139.100node2节点进行ARP欺骗(因为前端交换机与DR_Server通信是建立在MAC地址上的,而DR现在由node1变成了node2,所以交互机上原来的MAC表失效,交换机不能通过MAC表连接到VIP,所以node2就进行了一个ARP欺骗,自问自答,伪造了node1的MAC,从而实现了前端交换机照样可以根据原来的MAC表VIP(node2))这样就能实现DR_Server 的转移当Vrrp事物变化时,如何发送警告邮件给指定的管理员?写脚本控制邮件的发送脚本内容如下[root@node1 keepalived]# vim notify.sh#!/bin/bash#contact='root@localhost'Usage() { \\定义的一个Usage函数 echo "Usage:`basename $0` {master|backup|fault} VIP"}Notify() { subject="`hostname`'s state changed to $1" \\邮件主题 mailbody="`date "+%F %T"`: `hostname`'s state change to $1,$VIP floating." \\邮件内容 echo $mailbody |mail -s "$subject" $contact \\发送邮件}[ $# -lt 2 ] && Usage && exit \\参数小于2时执行Usage函数并退出VIP=$2 \\VIP为第二个参数case $1 in master) Notify master \\第一个参数是master时,调用Notify函数 ;; backup) Notify backup ;; fault) Notify fault ;; *) Usage exit 1 ;;esac[root@node1 keepalived]# chmod +x notify.sh两个节点重启sendmail和keepalived[root@node1 keepalived]# service keepalived restart[root@node1 keepalived]# service sendmail restart[root@node2 keepalived]# service keepalived restart[root@node2 keepalived]# service sendmail restart删除创建的down文件,进行DR切换[root@node1 keepalived]# rm -rf down[root@node1 keepalived]# mail 25 root Thu Dec 22 19:30 23/896 "node1.zxl.com's state changed to backup"& 25Message 25:From root@node1.zxl.com Thu Dec 22 19:30:36 2016Return-Path: <root@node1.zxl.com>X-Original-To: root@node1.zxl.comDelivered-To: root@node1.zxl.comFrom: root <root@node1.zxl.com>Date: Thu, 22 Dec 2016 19:30:36 +0800To: root@node1.zxl.comSubject: node1.zxl.com's state changed to backupUser-Agent: Heirloom mailx 12.4 7/29/08Content-Type: text/plain; charset=us-asciiStatus: RO2016-12-22 19:30:36: node1.zxl.com's state change to backup,192.168.139.100 floating.VIP转移发送的邮件已经收到本次实验完毕!
集群工作正常[root@node4 sh]# service httpd stop停掉一个节点服务,则会立马有邮件通知给管理员node4节点DOWN了[root@node1 keepalived]# mail>N 17 keeepalived@localhos Thu Dec 22 17:54 17/625 "[LVS_DEVEL] Realserver [192.168.139.8]:80 - DOWN"& Message 17:From keeepalived@localhost.zxl.com Thu Dec 22 17:54:32 2016Return-Path: <keeepalived@localhost.zxl.com>X-Original-To: root@localhostDelivered-To: root@localhost.zxl.comDate: Thu, 22 Dec 2016 09:54:32 +0000From: keeepalived@localhost.zxl.comSubject: [LVS_DEVEL] Realserver [192.168.139.8]:80 - DOWNX-Mailer: KeepalivedTo: root@localhost.zxl.comStatus: R=> CHECK failed on service : connection error <=node5节点被移除了[root@node1 keepalived]# ipvsadm -l -nIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 192.168.139.100:80 wrr -> 192.168.139.9:80 Route 1 0 0 [root@node4 sh]# service httpd startnode5节点又被加入了集群[root@node1 keepalived]# ipvsadm -l -nIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 192.168.139.100:80 wrr -> 192.168.139.8:80 Route 1 0 0 -> 192.168.139.9:80 Route 1 0 0 但是万一两个RS都挂掉怎么办?在node1和node2上装httpd(因为VIP可能会在两个节点转移,所两个节点都要装),将其做成fall_back_server,一旦两个RS挂掉,则提供一个临时页面,通知用户node1 node2都进行如下操作[root@node1 keepalived]# yum install httpd -y[root@node1 ~]# vim /var/www/html/index.html<h1>服务器维护中</h1>[root@node1 ~]# service httpd start[root@node1 keepalived]# vim keepalived.conf在virtual_server中加入 sorry_server 127.0.0.1 80[root@node1 keepalived]# service keepalived restart[root@node2 keepalived]# service keepalived restart [root@node4 sh]# service httpd stop[root@node5 ~]# service httpd stop可以看到Local 127.0.0.1上线[root@node1 keepalived]# ipvsadm -l -nIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 192.168.139.100:80 wrr -> 127.0.0.1:80 Local 1 0 0浏览器测试,node4 node5都挂了后由运行有VIP的DR提供维护页面[root@node4 sh]# service httpd start只要有一个RS在线,Local server就会下线 [root@node1 keepalived]# ipvsadm -l -nIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 192.168.139.100:80 wrr -> 192.168.139.8:80 Route 1 1 0 [root@node5 ~]# service httpd start写一个检测脚本,完成DR的切换,直接编辑文件[root@node1 ~]# vim /etc/keepalived/keepalived.confvrrp_script chk_down { 定义一个叫chk_down的脚本检查DR_Serverscript "[ -e /etc/keepalived/down ] && exit 1 || exit 0 " \\当/etc/keepalived/down \\ 文件存在时则检查失败,否则成功(只有返回值为0,才表示成 \\功),次数还可以通过文件设置复杂检测脚本,而不止一个命令 interval 2 \\每隔2秒监测一次 weight -2 \\如果监测为失败则此节点priority减去2(如node1由101变成99小于node2 \\的100则变为备节点) fall 2 \\只有连续监测两次都失败才证明此DR真的挂了 rise 1 \\只要有一次监测成功则此DR没有挂 }vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 101 advert_int 1 authentication { auth_type PASS auth_pass keepalived } virtual_ipaddress { 192.168.139.100/24 dev eth0 label eth0:0 } track_script { chk_down \\这里定义执行上面写的chk_down脚本}}编辑node2,重启服务[root@node2 ~]# vim /etc/keepalived/keepalived.conf[root@node1 ~]# service keepalived restart[root@node2 ~]# service keepalived restart[root@node1 ~]# cd /etc/keepalived/创建down文件从node1转移到node2,node1变成备节点[root@node1 keepalived]# touch down[root@node1 keepalived]# ifconfig eth0 Link encap:Ethernet HWaddr 00:0C:29:1C:13:12 inet addr:192.168.139.2 Bcast:192.168.139.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe1c:1312/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:18158 errors:0 dropped:0 overruns:0 frame:0 TX packets:18798 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:3011063 (2.8 MiB) TX bytes:3830969 (3.6 MiB)lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:155 errors:0 dropped:0 overruns:0 frame:0 TX packets:155 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:11194 (10.9 KiB) TX bytes:11194 (10.9 KiB)可以看到eth0:0(VIP)从本机转移了,查看一下日志描述[root@node1 keepalived]# tail /var/log/messagesDec 22 18:31:43 node1 Keepalived_vrrp[2107]: VRRP_Script(chk_down) failed检测失败Dec 22 18:31:44 node1 Keepalived_vrrp[2107]: VRRP_Instance(VI_1) Received higher prio advert收到更高的优先级(node1优先级由101-2=99小于node2的100)Dec 22 18:31:44 node1 Keepalived_vrrp[2107]: VRRP_Instance(VI_1) Entering BACKUP STATEnode1转换为备节点Dec 22 18:31:44 node1 Keepalived_vrrp[2107]: VRRP_Instance(VI_1) removing protocol VIPs.移除VIPDec 22 18:31:44 node1 Keepalived_healthcheckers[2106]: Netlink reflector reports IP 192.168.139.100 removedVIP在node2已经设置[root@node2 ~]# ifconfig eth0 Link encap:Ethernet HWaddr 00:0C:29:5F:68:2F inet addr:192.168.139.4 Bcast:192.168.139.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe5f:682f/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:21023 errors:0 dropped:0 overruns:0 frame:0 TX packets:20015 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:3081886 (2.9 MiB) TX bytes:2313640 (2.2 MiB)eth0:0 Link encap:Ethernet HWaddr 00:0C:29:5F:68:2F inet addr:192.168.139.100 Bcast:0.0.0.0 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:226 errors:0 dropped:0 overruns:0 frame:0 TX packets:226 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:21401 (20.8 KiB) TX bytes:21401 (20.8 KiB)[root@node2 ~]# tail /var/log/messagesDec 22 18:30:42 node2 Keepalived_vrrp[5295]: VRRP_Script(chk_down) succeeded检测成功Dec 22 18:31:47 node2 Keepalived_vrrp[5295]: VRRP_Instance(VI_1) Transition to MASTER STATE转换为主节点Dec 22 18:31:48 node2 Keepalived_vrrp[5295]: VRRP_Instance(VI_1) setting protocol VIPs.设置VIPDec 22 18:31:48 node2 Keepalived_healthcheckers[5294]: Netlink reflector reports IP 192.168.139.100 addedVIP添加成功Dec 22 18:31:48 node2 Keepalived_vrrp[5295]: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth0 for 192.168.139.100node2节点进行ARP欺骗(因为前端交换机与DR_Server通信是建立在MAC地址上的,而DR现在由node1变成了node2,所以交互机上原来的MAC表失效,交换机不能通过MAC表连接到VIP,所以node2就进行了一个ARP欺骗,自问自答,伪造了node1的MAC,从而实现了前端交换机照样可以根据原来的MAC表VIP(node2))这样就能实现DR_Server 的转移当Vrrp事物变化时,如何发送警告邮件给指定的管理员?写脚本控制邮件的发送脚本内容如下[root@node1 keepalived]# vim notify.sh#!/bin/bash#contact='root@localhost'Usage() { \\定义的一个Usage函数 echo "Usage:`basename $0` {master|backup|fault} VIP"}Notify() { subject="`hostname`'s state changed to $1" \\邮件主题 mailbody="`date "+%F %T"`: `hostname`'s state change to $1,$VIP floating." \\邮件内容 echo $mailbody |mail -s "$subject" $contact \\发送邮件}[ $# -lt 2 ] && Usage && exit \\参数小于2时执行Usage函数并退出VIP=$2 \\VIP为第二个参数case $1 in master) Notify master \\第一个参数是master时,调用Notify函数 ;; backup) Notify backup ;; fault) Notify fault ;; *) Usage exit 1 ;;esac[root@node1 keepalived]# chmod +x notify.sh两个节点重启sendmail和keepalived[root@node1 keepalived]# service keepalived restart[root@node1 keepalived]# service sendmail restart[root@node2 keepalived]# service keepalived restart[root@node2 keepalived]# service sendmail restart删除创建的down文件,进行DR切换[root@node1 keepalived]# rm -rf down[root@node1 keepalived]# mail 25 root Thu Dec 22 19:30 23/896 "node1.zxl.com's state changed to backup"& 25Message 25:From root@node1.zxl.com Thu Dec 22 19:30:36 2016Return-Path: <root@node1.zxl.com>X-Original-To: root@node1.zxl.comDelivered-To: root@node1.zxl.comFrom: root <root@node1.zxl.com>Date: Thu, 22 Dec 2016 19:30:36 +0800To: root@node1.zxl.comSubject: node1.zxl.com's state changed to backupUser-Agent: Heirloom mailx 12.4 7/29/08Content-Type: text/plain; charset=us-asciiStatus: RO2016-12-22 19:30:36: node1.zxl.com's state change to backup,192.168.139.100 floating.VIP转移发送的邮件已经收到本次实验完毕!
刷新集群工作正常[root@node4 sh]# service httpd stop停掉一个节点服务,则会立马有邮件通知给管理员node4节点DOWN了[root@node1 keepalived]# mail>N 17 keeepalived@localhos Thu Dec 22 17:54 17/625 "[LVS_DEVEL] Realserver [192.168.139.8]:80 - DOWN"& Message 17:From keeepalived@localhost.zxl.com Thu Dec 22 17:54:32 2016Return-Path: <keeepalived@localhost.zxl.com>X-Original-To: root@localhostDelivered-To: root@localhost.zxl.comDate: Thu, 22 Dec 2016 09:54:32 +0000From: keeepalived@localhost.zxl.comSubject: [LVS_DEVEL] Realserver [192.168.139.8]:80 - DOWNX-Mailer: KeepalivedTo: root@localhost.zxl.comStatus: R=> CHECK failed on service : connection error <=node5节点被移除了[root@node1 keepalived]# ipvsadm -l -nIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 192.168.139.100:80 wrr -> 192.168.139.9:80 Route 1 0 0 [root@node4 sh]# service httpd startnode5节点又被加入了集群[root@node1 keepalived]# ipvsadm -l -nIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 192.168.139.100:80 wrr -> 192.168.139.8:80 Route 1 0 0 -> 192.168.139.9:80 Route 1 0 0 但是万一两个RS都挂掉怎么办?在node1和node2上装httpd(因为VIP可能会在两个节点转移,所两个节点都要装),将其做成fall_back_server,一旦两个RS挂掉,则提供一个临时页面,通知用户node1 node2都进行如下操作[root@node1 keepalived]# yum install httpd -y[root@node1 ~]# vim /var/www/html/index.html<h1>服务器维护中</h1>[root@node1 ~]# service httpd start[root@node1 keepalived]# vim keepalived.conf在virtual_server中加入 sorry_server 127.0.0.1 80[root@node1 keepalived]# service keepalived restart[root@node2 keepalived]# service keepalived restart [root@node4 sh]# service httpd stop[root@node5 ~]# service httpd stop可以看到Local 127.0.0.1上线[root@node1 keepalived]# ipvsadm -l -nIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 192.168.139.100:80 wrr -> 127.0.0.1:80 Local 1 0 0浏览器测试,node4 node5都挂了后由运行有VIP的DR提供维护页面[root@node4 sh]# service httpd start只要有一个RS在线,Local server就会下线 [root@node1 keepalived]# ipvsadm -l -nIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP 192.168.139.100:80 wrr -> 192.168.139.8:80 Route 1 1 0 [root@node5 ~]# service httpd start写一个检测脚本,完成DR的切换,直接编辑文件[root@node1 ~]# vim /etc/keepalived/keepalived.confvrrp_script chk_down { 定义一个叫chk_down的脚本检查DR_Serverscript "[ -e /etc/keepalived/down ] && exit 1 || exit 0 " \\当/etc/keepalived/down \\ 文件存在时则检查失败,否则成功(只有返回值为0,才表示成 \\功),次数还可以通过文件设置复杂检测脚本,而不止一个命令 interval 2 \\每隔2秒监测一次 weight -2 \\如果监测为失败则此节点priority减去2(如node1由101变成99小于node2 \\的100则变为备节点) fall 2 \\只有连续监测两次都失败才证明此DR真的挂了 rise 1 \\只要有一次监测成功则此DR没有挂 }vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 101 advert_int 1 authentication { auth_type PASS auth_pass keepalived } virtual_ipaddress { 192.168.139.100/24 dev eth0 label eth0:0 } track_script { chk_down \\这里定义执行上面写的chk_down脚本}}编辑node2,重启服务[root@node2 ~]# vim /etc/keepalived/keepalived.conf[root@node1 ~]# service keepalived restart[root@node2 ~]# service keepalived restart[root@node1 ~]# cd /etc/keepalived/创建down文件从node1转移到node2,node1变成备节点[root@node1 keepalived]# touch down[root@node1 keepalived]# ifconfig eth0 Link encap:Ethernet HWaddr 00:0C:29:1C:13:12 inet addr:192.168.139.2 Bcast:192.168.139.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe1c:1312/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:18158 errors:0 dropped:0 overruns:0 frame:0 TX packets:18798 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:3011063 (2.8 MiB) TX bytes:3830969 (3.6 MiB)lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:155 errors:0 dropped:0 overruns:0 frame:0 TX packets:155 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:11194 (10.9 KiB) TX bytes:11194 (10.9 KiB)可以看到eth0:0(VIP)从本机转移了,查看一下日志描述[root@node1 keepalived]# tail /var/log/messagesDec 22 18:31:43 node1 Keepalived_vrrp[2107]: VRRP_Script(chk_down) failed检测失败Dec 22 18:31:44 node1 Keepalived_vrrp[2107]: VRRP_Instance(VI_1) Received higher prio advert收到更高的优先级(node1优先级由101-2=99小于node2的100)Dec 22 18:31:44 node1 Keepalived_vrrp[2107]: VRRP_Instance(VI_1) Entering BACKUP STATEnode1转换为备节点Dec 22 18:31:44 node1 Keepalived_vrrp[2107]: VRRP_Instance(VI_1) removing protocol VIPs.移除VIPDec 22 18:31:44 node1 Keepalived_healthcheckers[2106]: Netlink reflector reports IP 192.168.139.100 removedVIP在node2已经设置[root@node2 ~]# ifconfig eth0 Link encap:Ethernet HWaddr 00:0C:29:5F:68:2F inet addr:192.168.139.4 Bcast:192.168.139.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe5f:682f/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:21023 errors:0 dropped:0 overruns:0 frame:0 TX packets:20015 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:3081886 (2.9 MiB) TX bytes:2313640 (2.2 MiB)eth0:0 Link encap:Ethernet HWaddr 00:0C:29:5F:68:2F inet addr:192.168.139.100 Bcast:0.0.0.0 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:226 errors:0 dropped:0 overruns:0 frame:0 TX packets:226 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:21401 (20.8 KiB) TX bytes:21401 (20.8 KiB)[root@node2 ~]# tail /var/log/messagesDec 22 18:30:42 node2 Keepalived_vrrp[5295]: VRRP_Script(chk_down) succeeded检测成功Dec 22 18:31:47 node2 Keepalived_vrrp[5295]: VRRP_Instance(VI_1) Transition to MASTER STATE转换为主节点Dec 22 18:31:48 node2 Keepalived_vrrp[5295]: VRRP_Instance(VI_1) setting protocol VIPs.设置VIPDec 22 18:31:48 node2 Keepalived_healthcheckers[5294]: Netlink reflector reports IP 192.168.139.100 addedVIP添加成功Dec 22 18:31:48 node2 Keepalived_vrrp[5295]: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth0 for 192.168.139.100node2节点进行ARP欺骗(因为前端交换机与DR_Server通信是建立在MAC地址上的,而DR现在由node1变成了node2,所以交互机上原来的MAC表失效,交换机不能通过MAC表连接到VIP,所以node2就进行了一个ARP欺骗,自问自答,伪造了node1的MAC,从而实现了前端交换机照样可以根据原来的MAC表VIP(node2))这样就能实现DR_Server 的转移当Vrrp事物变化时,如何发送警告邮件给指定的管理员?写脚本控制邮件的发送脚本内容如下[root@node1 keepalived]# vim notify.sh#!/bin/bash#contact='root@localhost'Usage() { \\定义的一个Usage函数 echo "Usage:`basename $0` {master|backup|fault} VIP"}Notify() { subject="`hostname`'s state changed to $1" \\邮件主题 mailbody="`date "+%F %T"`: `hostname`'s state change to $1,$VIP floating." \\邮件内容 echo $mailbody |mail -s "$subject" $contact \\发送邮件}[ $# -lt 2 ] && Usage && exit \\参数小于2时执行Usage函数并退出VIP=$2 \\VIP为第二个参数case $1 in master) Notify master \\第一个参数是master时,调用Notify函数 ;; backup) Notify backup ;; fault) Notify fault ;; *) Usage exit 1 ;;esac[root@node1 keepalived]# chmod +x notify.sh两个节点重启sendmail和keepalived[root@node1 keepalived]# service keepalived restart[root@node1 keepalived]# service sendmail restart[root@node2 keepalived]# service keepalived restart[root@node2 keepalived]# service sendmail restart删除创建的down文件,进行DR切换[root@node1 keepalived]# rm -rf down[root@node1 keepalived]# mail 25 root Thu Dec 22 19:30 23/896 "node1.zxl.com's state changed to backup"& 25Message 25:From root@node1.zxl.com Thu Dec 22 19:30:36 2016Return-Path: <root@node1.zxl.com>X-Original-To: root@node1.zxl.comDelivered-To: root@node1.zxl.comFrom: root <root@node1.zxl.com>Date: Thu, 22 Dec 2016 19:30:36 +0800To: root@node1.zxl.comSubject: node1.zxl.com's state changed to backupUser-Agent: Heirloom mailx 12.4 7/29/08Content-Type: text/plain; charset=us-asciiStatus: RO2016-12-22 19:30:36: node1.zxl.com's state change to backup,192.168.139.100 floating.VIP转移发送的邮件已经收到本次实验完毕!

相关文章推荐
- Keepalived+lvs/DR 的 HA 集群、Keepalived实现web服务的HA集群
- lvs DR模式 +keepalived 实现directory 高可用、httpd服务负载均衡集群
- lvs DR模式 +keepalived 实现directory 高可用、httpd服务负载均衡集群
- 高可用集群技术之keepalived实现lvs高可用并负载均衡web服务
- LVS+Keepalived DR模式实现web负载均衡高可用
- LVS+Keepalived DR模式实现web负载均衡高可用
- 企业web高可用集群实战之lvs+keepalived+mysql HA
- keepalived基于LVS实现高可用,实现web服务的高可用
- Lvs+keepalived实现负载均衡、故障剔除(DR模式)
- lvs+keepalived实现DR模式热备
- 企业web高可用集群实战之lvs+keepalived+mysql HA
- CentOS6.5高可用集群LVS+Keepalived(DR模式)
- ubuntu server 10.4 下LVS-DR+heartbeat +Ldirectord实现web服务高可性负载均衡实验
- keepalived实现LVS的高可用以及实现web服务的高可用(主从模型、双主模型)
- CentOS6.2下搭建LVS(DR)+Keepalived实现高性能高可用负载均衡服务
- linux集群系列(一):LVS+Keepalived以DR模式实现负载均衡
- 基于Keepalived实现了LVS高可用及Web服务高可用包括主从模型和主主模型
- 企业web高可用集群实战之lvs+keepalived+mysql HA
- lvs/dr+keepalived实现Web负载均衡Dr高可用
- Lvs+keepalived 实现负载均衡、故障剔除(DR模式)