小白学《神经网络与深度学习》笔记之五:深度学习的胜利:AlphaGo
2016-12-18 21:53
423 查看
1.1 AlphaGo的主要原理
AlphaGo是由三个不同部分组成:(1)估值网络:估计棋局的状态(运行时没有任何搜素动作),计算谁领先了,领先了多少步--计算每一方赢的概率
(2)走棋策略网络:给定当前局面,预测/采样下一步的走棋,运行时也没有进行任何搜索。
(3)树搜索(MCTS, 蒙特卡洛树搜索):把两个网络结合在一起,模拟下一步会发生什么,并通过策略网络选择最佳的落子位置。
1.1.1 策略网络
1.1.2 MCTS拯救了围棋算法
1.1.3 强化学习:“周伯通,左右互搏”
1.1.4 估值网络
1.1.5 将所有组合到一起:树搜索
1.1.6 AlphaGo有多好
1.1.7 总结
可简单总结为:首先通过估值网络评估棋局情况,其次再通过一个快速的策略网络选择下一步的位置,一直下到最后。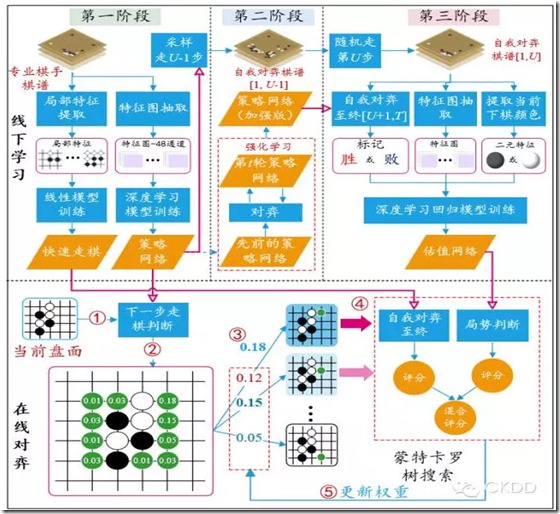
参考:http://www.leiphone.com/news/201603/VARZ2sn7aC2DPBkw.html
http://blog.csdn.net/starzhou/article/details/51295083

相关文章推荐
- 小白学《神经网络与深度学习》笔记之四-深度学习的常用方法(3)
- 小白学《神经网络与深度学习》笔记之三-深度学习是个什么东西
- 小白学《神经网络与深度学习》笔记之四-深度学习的常用方法(2)
- 小白学《神经网络与深度学习》笔记之四-深度学习的常用方法(1)
- 神经网络与深度学习笔记——第4章 神经网络可以计算任何函数的可视化证明
- 吴恩达deeplearning.ai课程《神经网络和深度学习》____学习笔记(第二周 1~6)
- 《神经网络和深度学习》系列文章八:迈向深度学习
- 1.3 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-4)-- 为什么深度学习会兴起?
- 吴恩达deeplearning.ai课程《神经网络和深度学习》____学习笔记(第二周 7~14)
- 吴恩达deeplearning.ai课程《神经网络和深度学习》____学习笔记(第四周)
- 神经网络与深度学习笔记(三)python 实现反向传播算法
- 神经网络与深度学习 笔记3 反向传播算法
- 吴恩达deeplearning.ai课程《神经网络和深度学习》____学习笔记(第一周)
- 神经网络与深度学习 笔记5 过度拟合和正则化
- 蒙特卡罗树搜索+深度学习 -- AlphaGo原版论文阅读笔记
- 神经网络与深度学习笔记(一)梯度下降算法
- 吴恩达深度学习入门学习笔记之神经网络和深度学习(第一周)
- 吴恩达深度学习入门学习笔记之神经网络和深度学习(第二周:神经网络基础)
- 吴恩达深度学习视频笔记1-4:《神经网络和深度学习》之《深层神经网络》
- Matlab深度学习笔记——深度学习工具箱说明