Hard Example Mining 与 online Hard Example Mining
2016-12-13 14:31
423 查看
Hard Example Mining 与 online Hard Example Mining 的应用
online Hard Example Mining
这部分主要转载的关于人脸的样本的应用,博主写的就很好,直接跳过http://blog.csdn.net/u013608402/article/details/51275486
Online Hard Example Mining
1. Introductionhard example mining 是机器学习在训练时常见的步骤。总结起来,mining方法大概可以分为两类:一种是SVM中用到margin-based,即训练时将violate the
current model’s margin 的样本认为是hard example,迭代直到收敛;另一种是在级联框架中的将false positive 认为是hard example的方法。
而在CNN中目标检测根据分类前的patch选择策略的不同,可分为两类:sliding-window和proposal-based,但是在hard example mining方面算法还不成熟,已有的方法大多是基于loss来确定是否是hard的,且一般作为实验中的trick出现,并没有形成系统方法。
2. Fast R-CNN
这一部分主要介绍了Fast R-CNN,一种proposal-based的通用物体检测方法,值得注意的是,在Fast R-CNN中,确定一个proposal是背景时也是根据IoU范围[bg_lo,0.5],这个范围的前提假设是与gt有重叠的样本是hard的可能性较大,但是作者在此指出,这样得到的结果很可能是次优的,因为在其他位置可能存在更hard的样本,所以在本文提出的OHEM算法中移除了这个阈值。
3. OHEM
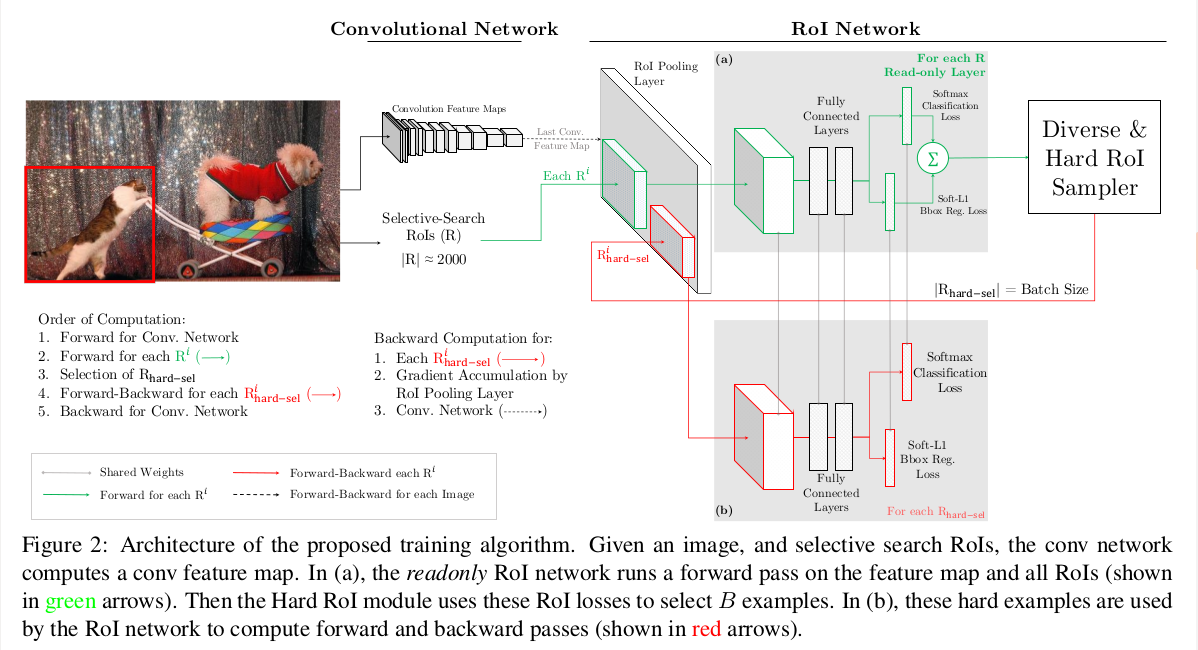
简单来说就是从ROI中选择hard,而不是简单的采样。
Forward: 全部的ROI通过网络,根据loss排序;
Backward:根据排序,选择B/N个loss值最大的(worst)样本来后向传播更新model的weights.
这里会有一个问题,即位置相近的ROI在map中可能对应的是同一个位置,loss值是相近的,所以针对这个问题,提出的解决方法是:对hard做nms,然后再选择B/N个ROI反向传播,这里nms选择的IoU=0.7。
在后向传播时,直觉想到的方法就是将那些未被选中的ROI的loss直接设置为0即可,但这实际上还是将所有的ROI进行反向传播,时间和空间消耗都很大,所以作者在这里提出了本文的网络框架,用两隔网络,一个只用来前向传播,另一个则根据选择的ROIs进行后向传播,的确增加了空间消耗(1G),但是有效的减少了时间消耗,实际的实验结果也是可以接受的。
(图)
4. Analyzing
与heuristic sampling比较:OHEM可以提高mAP 2.4个点
为什么只用hard examples,用全部的ROIs不好么?用全部的ROIs一是带来时间上的消耗,而且在用全部ROIs时,权重的更新还是集中在hard examples上做优化。
计算代价:1G more memory,时间上也是可以接受的。

5. Experients
两个数据集:PASCAL VOC和MS COCO
有趣的是在VOC上的结果显示,队不同类物体的提升效果是不同的,有待研究。
6. Bells and Whistle
加上了其他论文提出的两个方法
一个是Multi-scale,随机选择一个scale训练,用所有的scale测试
迭代的对bounding-box进行回归

triplet select
选择与anchor最不像的positive作为hard positive,与anchor最像的negative作为hard negative。
在实验中用所有的a-p对,然后挑选hard的a-n对,在挑选hardest negative时容易导致局部最优,所以去掉了alpha项。
[1]:Training Region-based Object Detectors with Online Hard Example Mining, cvpr 2016 oral
[2]:FaceNet: A Unified Embedding for Face Recognition and Clustering, cvpr 2015
Hard Example Mining
这里主要是根据SSD的hard negative mining 思想,这里比较简单,现做个记录,具体等熟悉SSD代码后进行详细的阐述正样本
本类的真值标定框。
负样本
考察每一个候选框,如果和本类所有标定框的重叠都小于0.3,认定其为负样本

相关文章推荐
- OHEM-Training Region-based Object Detectors with Online Hard Example Mining - cvpr 2016 oral
- Training Region-based Object Detectors with Online Hard Example Mining - cvpr 2016 oral
- Training Region-based Object Detectors with Online Hard Example Mining - cvpr 2016 oral
- [文献阅读]Training Region-based Object Detectors with Online Hard Example Mining
- 【论文笔记】(CVPR2016 Oral) Training Region-based Object Detectors with Online Hard Example Mining
- 论文提要“Training Region-based Object Detectors with Online Hard Example Mining”
- 论文笔记 OHEM: Training Region-based Object Detectors with Online Hard Example Mining
- Training Region-based Object Detectors with Online Hard Example Mining - cvpr 2016 oral
- Training Region-based Object Detectors with Online Hard Example Mining
- 论文笔记 | Training Region-based Object Detectors with Online Hard Example Mining
- 论文笔记:Training Region-based Object Detectors with Online Hard Example Mining
- 目标检测--Training Region-based Object Detectors with Online Hard Example Mining
- 论文笔记--FaceNet & Online Hard Example Mining
- 论文阅读-《Training Region-based Object Detectors with Online Hard Example Mining》
- OHEM安装运行(Training Region-based Object Detectors with Online Hard Example Mining)
- Training Region-based Object Detectors with Online Hard Example Mining(CVPR2016 Oral)
- Training Region-based Object Detectors with Online Hard Example Mining
- 什么是hard negative mining
- hard nagetive mining
- 非极大抑制(Non-Maximum Suppression)和Hard negative mining