机器学习 - 线性模型
2016-12-12 11:13
260 查看
一.线性回归—LR
线性回归是一种监督学习下的线性模型,线性回归试图从给定数据集中学习一个线性模型来较好的预测输出(可视为:新来一个不属于D的数据,我们只知道他的x,要求预测y,D如下表示)。首先我们还是给定数据集的严格表示(我们这里直接讲多维的线性回归):
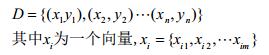
即是线性模型,那么我们容易给出目标函数:
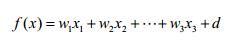
用向量的方式来表示目标函数,其中目标函数产生的结果即是我们的输出:
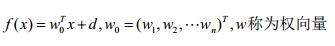
为了便于后文分析,我们将d归并到w中:
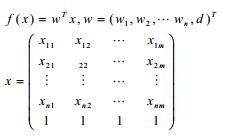
现在,输入,目标函数,输出都有了。我们要想要好的预测y,那么我们首先应该在D上f(x)要能够表现的比较满意,即当D中任意一个(xi,yi),将xi带入f(x),最后得出的f(xi)≈yi,当然某些情况除外,比如离群点,这些点可能本身受噪声影响太大,或者本身就是个错误的数据。要衡量f(xi)是否约等于yi,我们可以定义f(xi)与yi之间的均方误差,这种误差非常直观,它实际上也可以看成是欧几里得空间的距离计算。
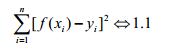
上述分析是从直观上的结果,我们必须要用代数的方式来表示f(xi)与yi之间的进阶程度;这实际上是对1.1的一个优化问题。即寻找一组(w,b)使得1.1式的值足够小,使用矩阵对1.1式进行表达:
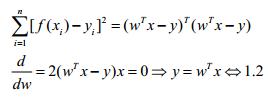
根据线性方程组有解的条件,由于x,y是任意的,因此我们无法判断方程是否有解。分以下情况讨论:
(1)y=wTx满足有解条件,即R(wTx)=R(wTx|y)。此时可以直接解除w。
(2)y=wTx无解,但肯定存在最小二乘解:
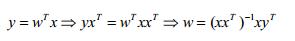
此时最终学到的模型为:
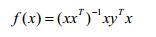
二.Logistic回归
对于这个logistic回归,先说两点容易误解的地方:一是他是一种线性模型,针对权向量w的线性模型;二是虽然他的名字带有回归,但他是如假包换的分类算法。Logistic回归实际是在线性回归的基础上引入一个函数将原先的回归转化为分类。考虑二分类任务:
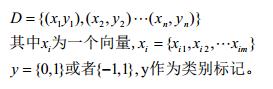
有了数据集及类别标记,那么我们可以将上文中线性模型的结果与类别label通过某种映射统一起来:
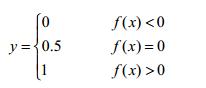
即预测值f(x)>0,label=1;f(x)<0,label=0;这个函数是我们常见的阶跃函数(0.5视为过渡值,这是与单位阶跃函数的唯一区别)。
这个函数可以对我们的计算结果进行分类,但是这个函数非凸非连续,数学性质较差。因此我们可以考虑定义一个与阶跃函数类似,但是既凸又连续的函数。这个函数自然就是我们的sigmoid函数,其定义形式如下:
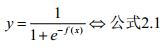
Sigmoid函数与单位阶跃函数的曲线如图2.1所示:
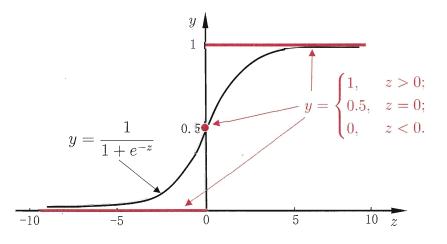
图2.1
对公式2.1进行推演:
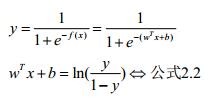
观察公式2.2的对数内部的分数我们容易发现,y与1-y具有很好的性质,即类别上的互补。换句话说,当wTx+b的结果出来之后,我们容易算出右边的对数值只要评定该对数值与0的大小,我们即可进行分类。甚而至于,我们可以将右边对数值视为概率的比值,即wTx+b的结果更倾向于我们将x分入到哪一类。这里开始等价于我们引入了统计机器学习的知识。
我们可将y视为类后验概率密度P(y=1|x),1-y则视为类后验概率密度P(y=0|x)。2.2式可继续推演:
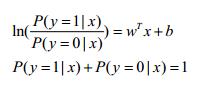
可以解得:
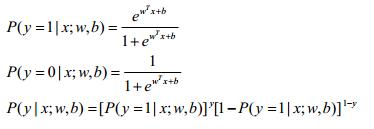
联合概率密度为:
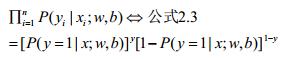
不要忘记,跟线性模型一样,logistic回归在做分类问题,那么一样的需要对数据训练,得到我们最优(或者较优)的模型。也就是我们需要求出w、b这俩参数。我们可以用最大似然法来对w、b的参数进行估计。在这里举个栗子来说明下最大似然法为什么可以对w、b进行参数估计。
栗子:某个男人不幸患了肺癌,现在我毫无征兆的让你判断这个男人是否抽烟,只有是和否没其他答案?我相信只要是个正常人,都会判断这个男人是抽烟的。这其实就是频率学派的最大似然原理。因为我们只有判断这个男人抽烟才能使“该男人患肺癌”这一事件发生的可能性更大。
同样的道理,对公式2.3也是一样的道理。当训练集被采集出来打上label之后,从我们的角度来讲,我们只有使2.3(即x属于其真实label的概率)越高,我们才能达到更好的泛化能力,即通过2.3最大来求w、b。假如2.3很小,即原样本标记就出错了,那么我们也就没有建模的必要了。
对公式2.3取对数就得到似然函数:
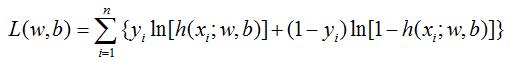
采用梯度下降算法可以求解出w、b。梯度下降算法将有专题讲解。

相关文章推荐
- 机器学习和数据挖掘(3):线性模型
- 【机器学习-斯坦福】学习笔记4 ——牛顿方法;指数分布族; 广义线性模型(GLM)
- 机器学习之理论篇—线性模型
- 机器学习(5)多项式回归:用基函数扩展线性模型
- 小白学习机器学习---第三章:线性模型(3):线性判别分析
- 机器学习笔记—再谈广义线性模型
- 周志华《机器学习》笔记:第3章 线性模型
- 机器学习笔记3.线性模型----教材周志华西瓜书
- 【深度】机器学习进化史:从线性模型到神经网络
- 机器学习与数据挖掘_线性模型 II
- 机器学习之理论篇—线性模型
- 机器学习和数据挖掘(9):线性模型
- 加州理工学院公开课:机器学习与数据挖掘_线性模型 II(第九课)
- 斯坦福机器学习实现与分析之四(广义线性模型)
- 【机器学习杂货铺】——线性模型和非线性模型(暂缺)
- 机器学习-广义线性模型
- 应用机器学习(八):线性模型
- 机器学习.周志华《3 线性模型》
- 机器学习笔记(IX)线性模型(V)多分类学习
- 读书笔记《机器学习》: 第三章:线性模型