王小草【机器学习】笔记--无监督算法之聚类
2016-12-08 16:48
936 查看
标签(空格分隔): 王小草机器学习笔记
根据这些特征数据计算样本点之间的相似性。
根据相似性将数据划分到多个类别中。
使得,同一个类别内的数据相似度大,类别之间的数据相似度小。
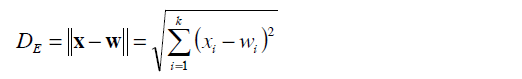

国外一般是分一个一个街区的,要想从街区的一角走到另一角,不能直接穿过,必须沿着街区两边的道路走。
所以上图中两点的曼哈顿距离是:
|x1-w1|+|x2-w2|
汉明距离的做法是,如果AB都没有买或都买了,表示他们行为一致,距离为0,相似度高;如果他们的行为不同,那么在该商品种类下距离为1,最后将17件商品对应的距离相加(也就是把1相加),求和的结果就是汉明距离

Pearsion相关系数的范围是[-1,1],如果完全正相关则为1,完全负相关则为-1,完全不先关则为0.

pearsion相关系数在回归中应用普遍,比如在建立回归模型之前,需要先计算各个自变量与应变量之间的相关度,如果相关度小,则应该讲该自变量从模型中去掉。另外,也有必要计算自变量之间的两两相关性,如果自变量之间存在相关性大的变量,那么非常有必要将其中一个剔除或者使用主成分分析PCA进行特征降维,因为线性回归的假设之一是自变量都是互相独立的,如果有自变量先关则会导致共线性,影响模型的质量与预测的准确度。
计算余弦角的公式:

假设向量a、b的坐标分别为(x1,y1)、(x2,y2)则余弦相似度为:
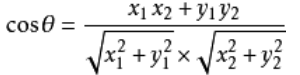
设向量 A = (A1,A2,…,An),B = (B1,B2,…,Bn) 。推广到多维:
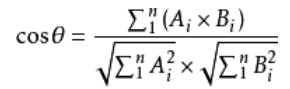
皮尔逊先关系数与预先相似度的关系:
相关系数即将x,y坐标向量各自平移到原点后的夹角余弦。
这即解释了为何文档间求距离使用夹角余弦,因为这一物理量表征了文档去均值化后的随机向量间的相关系数。
文档的去均值就是将计算文档的tf-idf值。
然后再将tf-idf来做余弦相似性。
两个集合A和B交集元素的个数在A、B并集中所占的比例,称为这两个集合的杰卡德系数,用符号 J(A,B) 表示。杰卡德相似系数是衡量两个集合相似度的一种指标。
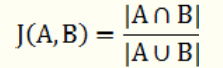
假设样本A和样本B是两个n维向量,而且所有维度的取值都是0或1。例如,A(0,1,1,0)和B(1,0,1,1)。我们将样本看成一个集合,1表示集合包含该元素,0表示集合不包含该元素。
p:样本A与B都是1的维度的个数
q:样本A是1而B是0的维度的个数
r:样本A是0而B是1的维度的个数
s:样本A与B都是0的维度的个数
那么样本A与B的杰卡德相似系数可以表示为:
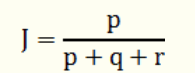
此处分母之所以不加s的原因在于:
对于杰卡德相似系数或杰卡德距离来说,它处理的都是非对称二元变量。非对称的意思是指状态的两个输出不是同等重要的,例如,疾病检查的阳性和阴性结果。
按照惯例,我们将比较重要的输出结果,通常也是出现几率较小的结果编码为1(例如HIV阳性),而将另一种结果编码为0(例如HIV阴性)。给定两个非对称二元变量,两个都取1的情况(正匹配)认为比两个都取0的情况(负匹配)更有意义。负匹配的数量s认为是不重要的,因此在计算时忽略。
杰卡德相似度算法没有考虑向量中潜在数值的大小,而是简单的处理为0和1,不过,做了这样的处理之后,杰卡德方法的计算效率肯定是比较高的,毕竟只需要做集合操作。
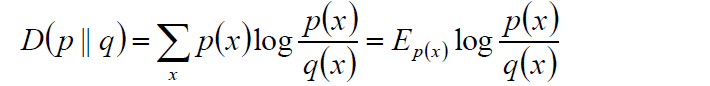
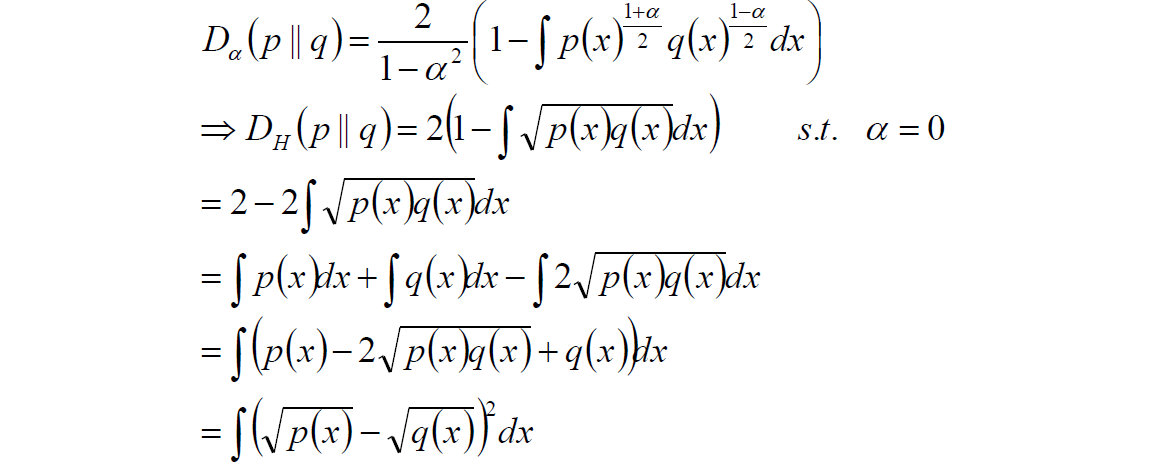
该距离满足三角不等式,是对称,非负距离
between derived density “bubbles” (hyper-spheres).
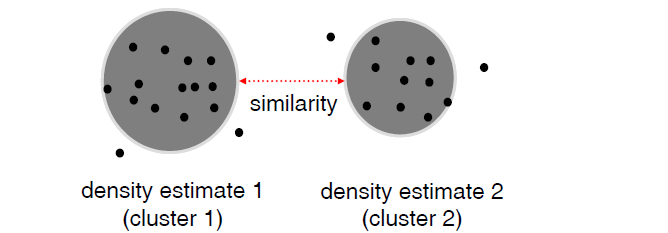
1.每个簇至少包含一个对象
2.每个对象属于且仅属于一个簇
3.将满足上述条件的K个簇称作一个合理的划分。
基本思想:
对于给定的类别数目k,首先给出初始的划分,通过迭代改变样本和簇的隶属关系,使得每一次改进之后的划分方案都较前一次好。
1.确定输入样本
假定输入样本为S=x1, x2, x3,…,xm
2.选择初始的k个类别中心,μ1, μ2, μ3,…,μk
3.对每个样本xi,都与各个类别中心求相似性,然后将它标记为与它相似度最高的那个类别中心所在的类别。即:

4.在新的类别中选出一个新的类别中心(该类中所有样本的均值)
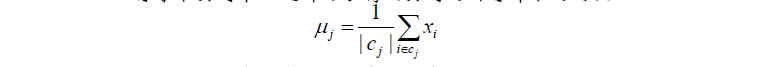
5.不断重复3,4炼骨,直到类别中心的变化小于某个阀值或者满足终止条件为止。完成聚类过程。
如下图,就是聚类的整个过程:
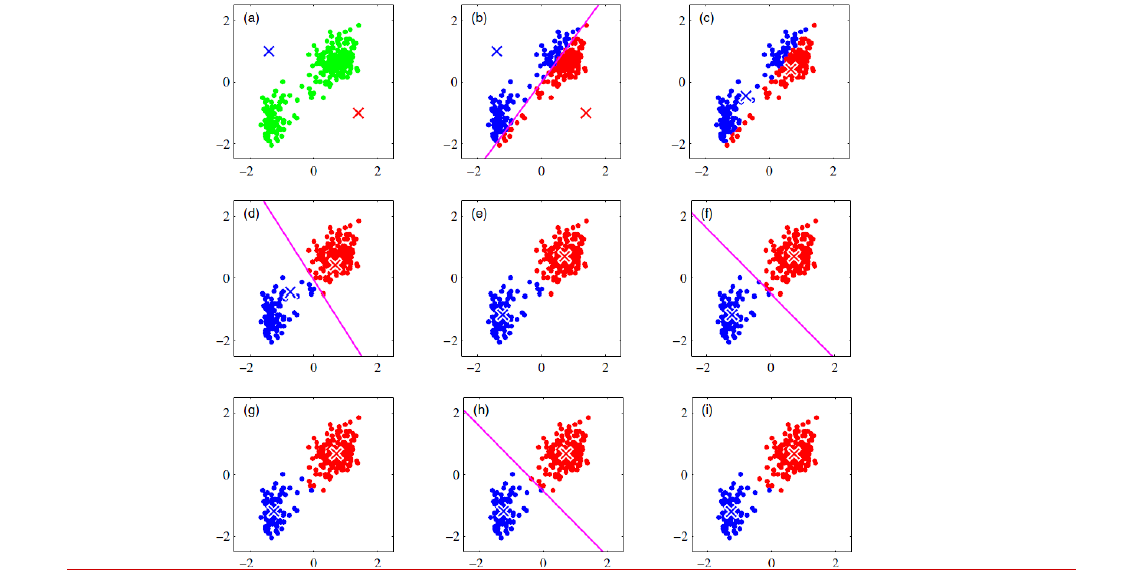
初始均值可以随机选择。但是万一选择不好,也可能影响之后的所有结果。
比如下图,要对左图分成4个类,非常明显的4个分布点。但是如果初始的均值选成了右图那样,最后聚类的结果完全不是我们想要的结果
所以初始均值是敏感的。
那么如何选择初始均值呢?
假设k=4
首先随机选择一个点作为第一个初始中心。
然后求其他所有样本点到这个中心的距离,用距离作为概率的权重,再随机得在样本中去选择第二中心点。
接着对剩下的样本再对现有的2个中心点求距离取出最短距离,以这个距离作为概率的权重,再随机选择第三个中心点。
同理,选出第4个中心点。
于是,4个初始的中心点都选好了。可以继续去做正常的聚类了。
这个过程我们叫K+means++
中心一定要用均值选吗?
比如说1,2,3,4,100的均值是22,但很显然22来当聚类中心有点牵强,因为它离大多数的点都比较远,100可能是一个噪声。所以选择 中位数3更为妥当。
这种聚类方法叫做k-Mediods聚类(k-中值距离)
在实际应用中具体问题具体分析。
关于终止条件的指标可以是?
迭代次数/簇中心变化率/最小平方误差MSE
关于如何选择k?
• Subject-matter knowledge (There
are most likely five groups.)
• Convenience (It is convenient to
market to three to four groups.)
• Constraints (You have six products
and need six segments.)
• Arbitrarily (Always pick 20.)
• Based on the data (Ward’s method)
每个簇数目为N1,N2,..Nk
使用平方误差作为目标函数:

对每个簇中,求每个样本到中心的距离的平方求和,然后将每个簇的误差相加。
该函数是关于μ1,μ2,μ3…,μk的凸函数,其驻点为:

所以是对目标函数的梯度下降。
如果对所有样本求梯度下降就是BGD
随机得对若干个样本做梯度下降就是随机下降法SGD.
将以上两者结合就是Mini-batch K-means算法。
根据上述目标函数,另外一个更深入的重点
其实对每一个簇,有一个前提假设:所有样本服从高斯分布。
如果将目标函数中的(xi-μi)^2换成绝对值|xi-μi|,那就是上面提到过的k-Mediods聚类
1.解决聚类问题的一种经典算法,简单,快速
2.对处理大数据集,该算法保持可伸缩性和高效率
3.当簇近似为高斯分布,它的效果是较好的
缺点:
1.在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用
2.必须事先给出k,而且对初值敏感,对于不同的初始值,可能会导致不同的结果。
3.不适用于发现非凸形状的簇或者大小差别很大的簇
4.对噪声和孤立点数据敏感
k-means聚类算法可作为其他聚类算法的基础算法,如谱聚类。
对于给定样本x1,x2…,xm;给定先验值r1,r2(r1< r2)
x1,x2…,xm形成一个列表L;同时构造一个空列表C。
随机选择L中的样本c,计算了Lz中样本xj与c的距离dj
若dj
凝聚的层次聚类AGNES
一种自底向上的策略,首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到某个终结条件被满足。
分裂的层次聚类DIANA
采用自顶向下的策略,它首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到到达了某个终结条件。
基于距离的聚类只能发现“类圆形”的聚类(即高斯分布的假设),而密度聚类可以发现任意形状,并且对噪声数据不敏感。
但是计算密度单元的计算复杂度大,需要建立空间索引来降低计算量。
这里主要介绍两种密度聚类方法:DBSCAN和密度最大值法
DBSCAN的若干概念:
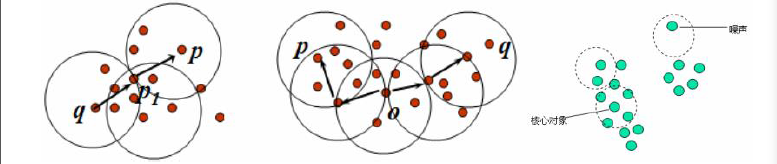
对象的ε-邻域:给定对象在半径ε内的区域。
核心对象:对于给定的数目m,如果一个对象的ε-邻域至少包含m个对象,则称该对象为核心对象。
直接密度可达:给定一个对象集合D,如果p是在q的ε邻域内,而q是一个核心对象,我们说对象p从对象q出发是直接密度可达的。
密度可达:如果p直接密度可达p1,p1直接密度可达q,则说q是从对象p关于ε和m的密度可达。
密度相连:如果对象o与p,o与q都是密度可达,则说p和q室密度相连。
簇:一个基于密度的簇是最大的密度相连对象的集合。
噪声:不包含在任何簇中的对象称为噪声。
DBSCAN算法流程:
1.如果一个点p的ε-邻域包含多于m个对象,则创建一个p作为核心对象的新簇;
2.寻找并合并核心对象直接密度可达的对象;
3.没有新点可以更新簇时,算法结束
由上述算法可知:
每个簇至少包含一个核心对象;
非核心对象可以是簇的一部分,构成了簇的边缘。
包含过少对象的簇被认为是噪声
例子:
以下分别是m为5,ε=25,30,40的时候的聚类
给定一个r值,对每个样本点xi,求出其以r为半径的圆内包含了多少个样本点,样本点的个数记为ρi,表示以xi的密度。于是我们可以求出ρ1,ρ2…ρm。
再对每个样本点,比如现在以x1为例。找出一堆离它距离比较近的点,比如x2,x4,x6,x7.
这4个点分别有自己的密度ρ2=6,ρ4=8,ρ6=4,ρ7=7.
假设ρ1=5,分别把ρ1与以上四个ρ值作比较,留下密度比自己大的样本点,所以剩下的是ρ2=6,ρ4=8,ρ7=7。
然后再求出x1分别到以上三个点的距离,分别是d2,d4,d7,选出距离最小的那个值,比如是d4,这个最小的距离我们记做δ1,即高局部密度点距离。
现在我们为x1求出了两个值:(ρ1,δ1)。
以此类推,所有的样本点xi都可以求出(ρi,δi)
想想,如果一个点的ρ和δ都很大,那么说明这个点的密度很大,并且密度比它大且离它最近的那个样本点距离它也比较远。也就说它们两可以自成一个类,彼此密度都很大,且距离也比较远。
如果一个点的ρ很小δ却很大,则说明它的密度很小,且离其他的大密度点也比较远,说明它是一个噪声!
簇中心的识别:那些有着比较大的局部密度ρi和很大的高密度距离的点被认为是簇的中心。
确定簇中心之后,其他点按照距离已知中心簇的中心最近进行分类。
(也可以按照密度可达方法进行分类)
举个例子:
左图是所有样本点在二维空间的分布,右图是以ρ为横坐标,以δ为纵坐标绘制的决策图。可以看到,1和10两个点的ρδ都比较大,作为簇中心、而26.27.28三个点的δ也比较大,但是ρ比较小,所以是噪声。

假设我们有m个样本(a1,a2,…,am),每个样本的特征维度是n维。
现在将每个样本(ai,aj)根据特征两两求相似性wij。于是就有了m*m维的相似性矩阵W。
因为(ai,aj)的相似性 = (aj,ai)的相似性,所以这个相似性矩阵W是一个对称矩阵。
相似性矩阵W的的每一行都是ai与a1,a2,..am的相似性,将每行的值求和,每个样本点ai都会得到一个值di.
将di(d1,d2,…,dn)放在n*n矩阵的对角线上,形成了一个n*n的对角矩阵D。
好了现在我们有两个矩阵:对角矩阵D,与对称矩阵W
定义一个L矩阵:L=D-W
这个L的来头非常大,它就是拉普拉斯矩阵。
对这个L矩阵提取特征值与特征向量。
特征值:λ1,λ2,…,λm
特征向量:u1,u2,…,um
可以证明L是一个半正定矩阵,所以最小特征值肯定是0.(为什么是半正定,为什么半正定就有特征值0呢?这个不放在这里细讲先)
将所有特征值由小到大排列,取出最小的前k个特征值。将这些特征值对应的特征矩阵组合在一起。
因为一个特征矩阵ui是m*1维度。所有k个特征矩阵组合在一起就形成了m*k维度的大矩阵U。
U的行数是m,对应的是m个样本,列数为k,对应的是k个指标。
这k个指标可以看成是k个特征。
于是我们有了针对m个样本的k维特征的这样一组数据。直接将这组数据用于做k-means聚类即可。(其实就是将原来的特征用转换后的新的特征代替了)。
以上就是谱聚类的具体过程。
对了还要说一下相似度的计算,也就是W矩阵是咋滴来的。
有这样几个方法,一般都是用高斯相似性:
距离越大,相似度越小
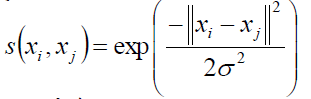
关于高斯相似性的东东在“王小草【机器学习】笔记–支持向量机”一文的核函数处有解释。
其计算公式为:
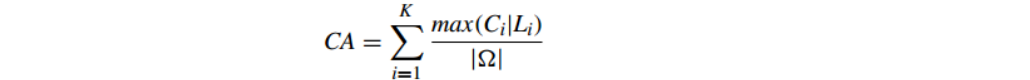
CA也叫purity。
purity方法的优势是方便计算,值在0~1之间,完全错误的聚类方法值为0,完全正确的方法值为1。同时,purity方法的缺点也很明显它无法对退化的聚类方法给出正确的评价,设想如果聚类算法把每篇文档单独聚成一类,那么算法认为所有文档都被正确分类,那么purity值为1!而这显然不是想要的结果。
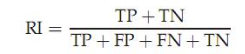
其中TP是指应该被聚在一类的两个样本被正确分类了,TN是只不应该被聚在一类的两个文档被正确分开了,FP是不应该放在一类的文档被错误的放在了一类,FN只不应该分开的文档被错误的分开了。

均一性可以通过以下公式求得:
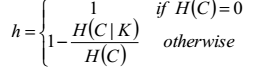
假设我们是已经知道这批聚类数据的真实类别的,聚类之后,在同一个簇中的类别,如果只有一个,那么这个簇的经验为0jj,均一性为1, 如果有大于1个类别,那么计算该类别下的簇的条件经验熵,如果条件经验熵越大,则均一性就越小。
均一性在0-1之间。
完整性的计算公式如下:
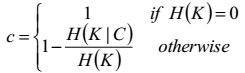
假设我们是已经知道这批聚类数据的真实类别的,聚类之后,如果同一个类的样本的确被全部分在了同一个簇中,那么这个类的经验熵就是0,完整性就是1,;反之,如果同一类的样本被分到了不同的簇中,H(K|C)的条件经验熵就会增大,从而完整性就降低了。
完整性在0-1之间。
通过以下公式我们将均一性与完整性的加权平均:
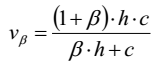
其实V-measure与F-measure是一样的,前者用的是经验熵,后者用的是频率。
假设数据集S共有N个元素,我们对N个元素去做聚类。
用不同的聚类方法得到两个不同的聚类结果:
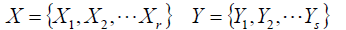
Xi,Yi分别为各自的簇。
(当然,如果事先知道样本的标签就更好,其中一个结果就是真实的结果,另一个是聚类得到的结果)
ai,bi分别为对应簇中的元素个数:
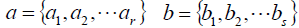
nij表示Xi和Yi两个簇中相同的元素的个数:
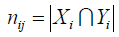
将以上关系表示成如下表格:
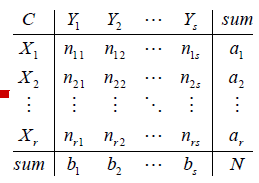
那么我们最终要求的ARI指数的计算公式为:

ARI取值范围为[−1,1],值越大意味着聚类结果与真实情况越吻合。从广义的角度来讲,ARI衡量的是两个数据分布的吻合程度。
其实ARI是由AR转变优化而来的,可将以上公式简写为:
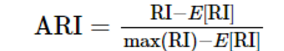
互信息为:
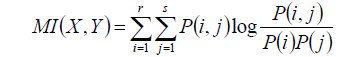
正则化的互信息为
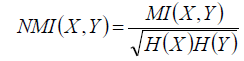
X服从超几何分布,则互信息的期望是:

借鉴ARI,则AMI为:
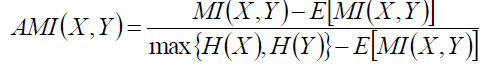
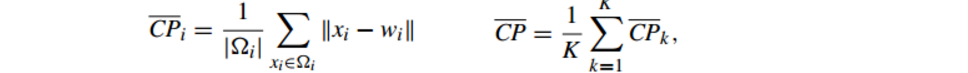
CP计算 每一个类 各点到聚类中心的平均距离
CP越低意味着类内聚类距离越近
缺点:没有考虑类间效果
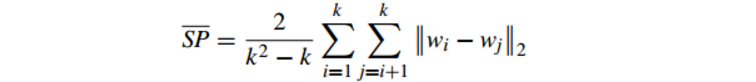
SP计算 各聚类中心两两之间平均距离
SP越高意味类间聚类距离越远
缺点:没有考虑类内效果
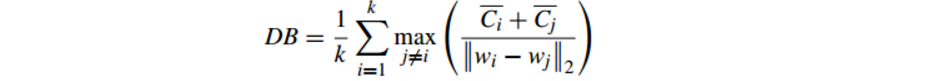
DB计算 任意两类别的类内距离平均距离(CP)之和除以两聚类中心距离 求最大值
DB越小意味着类内距离越小 同时类间距离越大
缺点:因使用欧式距离 所以对于环状分布 聚类评测很差
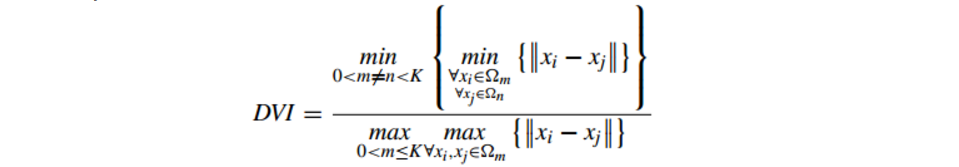
DVI计算 任意两个簇元素的最短距离(类间)除以任意簇中的最大距离(类内)
DVI越大意味着类间距离越大 同时类内距离越小
缺点:对离散点的聚类测评很高、对环状分布测评效果差
样本i到同簇其他样本的平均距离为ai;
样本i到最近的其他簇的所有样本的平均距离为bi;
于是轮廓系数的计算公式为:
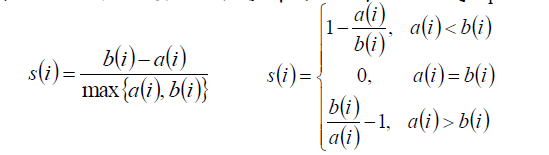
所有样本轮廓系数的平均值称为聚类结果的轮廓系数。
轮廓系数越接近于1则聚类效果越好!
1. 聚类的概述
存在大量未标注的数据集,即只有特征,没有标签的数据。根据这些特征数据计算样本点之间的相似性。
根据相似性将数据划分到多个类别中。
使得,同一个类别内的数据相似度大,类别之间的数据相似度小。
2. 相似性的度量方法
2.1 欧式距离
欧氏距离指的是在任何维度的空间内,两点之间的直线距离。距离越大,相似度越小,距离越小,相似度越大。公式如下:2.2 曼哈顿距离
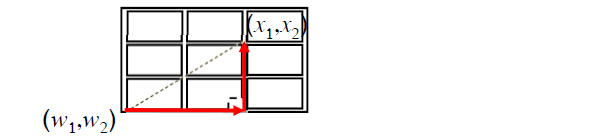
曼哈顿距离(Manhattan DistanceCity)也叫街区距离(Block Distance)。两点之间的距离是直角三角形的两条边长和。国外一般是分一个一个街区的,要想从街区的一角走到另一角,不能直接穿过,必须沿着街区两边的道路走。
所以上图中两点的曼哈顿距离是:
|x1-w1|+|x2-w2|
2.3 汉明距离Hamming Distance
假设有两组数据分别是两个用户在淘宝上买过的东西,如下图,假设1-17是17件商品,如果买了就在该用户下标记为1,没买的标记为0.根据这两组数据比较AB两个用户在购物行为上的相似性。汉明距离的做法是,如果AB都没有买或都买了,表示他们行为一致,距离为0,相似度高;如果他们的行为不同,那么在该商品种类下距离为1,最后将17件商品对应的距离相加(也就是把1相加),求和的结果就是汉明距离
2.4 皮而逊相关系数
Pearson相关系数是用来衡量两个数据集合是否在一条线上面。Pearsion相关系数的范围是[-1,1],如果完全正相关则为1,完全负相关则为-1,完全不先关则为0.
pearsion相关系数在回归中应用普遍,比如在建立回归模型之前,需要先计算各个自变量与应变量之间的相关度,如果相关度小,则应该讲该自变量从模型中去掉。另外,也有必要计算自变量之间的两两相关性,如果自变量之间存在相关性大的变量,那么非常有必要将其中一个剔除或者使用主成分分析PCA进行特征降维,因为线性回归的假设之一是自变量都是互相独立的,如果有自变量先关则会导致共线性,影响模型的质量与预测的准确度。
2.5 余弦相似度
通过计算两个向量的夹角余弦值来评估他们的相似度。因为我们认为夹角如果越大则相距越远,夹角小则距离近,余弦值越接近1。计算余弦角的公式:
假设向量a、b的坐标分别为(x1,y1)、(x2,y2)则余弦相似度为:
设向量 A = (A1,A2,…,An),B = (B1,B2,…,Bn) 。推广到多维:
皮尔逊先关系数与预先相似度的关系:
相关系数即将x,y坐标向量各自平移到原点后的夹角余弦。
这即解释了为何文档间求距离使用夹角余弦,因为这一物理量表征了文档去均值化后的随机向量间的相关系数。
文档的去均值就是将计算文档的tf-idf值。
然后再将tf-idf来做余弦相似性。
2.6 杰卡德相似系数
Jaccard similarity coefficient两个集合A和B交集元素的个数在A、B并集中所占的比例,称为这两个集合的杰卡德系数,用符号 J(A,B) 表示。杰卡德相似系数是衡量两个集合相似度的一种指标。
假设样本A和样本B是两个n维向量,而且所有维度的取值都是0或1。例如,A(0,1,1,0)和B(1,0,1,1)。我们将样本看成一个集合,1表示集合包含该元素,0表示集合不包含该元素。
p:样本A与B都是1的维度的个数
q:样本A是1而B是0的维度的个数
r:样本A是0而B是1的维度的个数
s:样本A与B都是0的维度的个数
那么样本A与B的杰卡德相似系数可以表示为:
此处分母之所以不加s的原因在于:
对于杰卡德相似系数或杰卡德距离来说,它处理的都是非对称二元变量。非对称的意思是指状态的两个输出不是同等重要的,例如,疾病检查的阳性和阴性结果。
按照惯例,我们将比较重要的输出结果,通常也是出现几率较小的结果编码为1(例如HIV阳性),而将另一种结果编码为0(例如HIV阴性)。给定两个非对称二元变量,两个都取1的情况(正匹配)认为比两个都取0的情况(负匹配)更有意义。负匹配的数量s认为是不重要的,因此在计算时忽略。
杰卡德相似度算法没有考虑向量中潜在数值的大小,而是简单的处理为0和1,不过,做了这样的处理之后,杰卡德方法的计算效率肯定是比较高的,毕竟只需要做集合操作。
2.7 相对熵
相对熵也叫K-L距离,计算公式如下:2.8 Hellinger距离
计算过程如下:该距离满足三角不等式,是对称,非负距离
2.9 基于密度的相似性
Density-based methods define similarity as the distancebetween derived density “bubbles” (hyper-spheres).
3. K-means聚类的过程与步骤
给定一个有N个对象的数据集,构造数据的K各簇。k<=n。满足下列条件:1.每个簇至少包含一个对象
2.每个对象属于且仅属于一个簇
3.将满足上述条件的K个簇称作一个合理的划分。
基本思想:
对于给定的类别数目k,首先给出初始的划分,通过迭代改变样本和簇的隶属关系,使得每一次改进之后的划分方案都较前一次好。
3.1 k-means算法基本步骤
The three-step k-means methodology is given1.确定输入样本
假定输入样本为S=x1, x2, x3,…,xm
2.选择初始的k个类别中心,μ1, μ2, μ3,…,μk
3.对每个样本xi,都与各个类别中心求相似性,然后将它标记为与它相似度最高的那个类别中心所在的类别。即:
4.在新的类别中选出一个新的类别中心(该类中所有样本的均值)
5.不断重复3,4炼骨,直到类别中心的变化小于某个阀值或者满足终止条件为止。完成聚类过程。
如下图,就是聚类的整个过程:
3.2 对K-means的思考
如何选择初始均值?初始均值可以随机选择。但是万一选择不好,也可能影响之后的所有结果。
比如下图,要对左图分成4个类,非常明显的4个分布点。但是如果初始的均值选成了右图那样,最后聚类的结果完全不是我们想要的结果
所以初始均值是敏感的。
那么如何选择初始均值呢?
假设k=4
首先随机选择一个点作为第一个初始中心。
然后求其他所有样本点到这个中心的距离,用距离作为概率的权重,再随机得在样本中去选择第二中心点。
接着对剩下的样本再对现有的2个中心点求距离取出最短距离,以这个距离作为概率的权重,再随机选择第三个中心点。
同理,选出第4个中心点。
于是,4个初始的中心点都选好了。可以继续去做正常的聚类了。
这个过程我们叫K+means++
中心一定要用均值选吗?
比如说1,2,3,4,100的均值是22,但很显然22来当聚类中心有点牵强,因为它离大多数的点都比较远,100可能是一个噪声。所以选择 中位数3更为妥当。
这种聚类方法叫做k-Mediods聚类(k-中值距离)
在实际应用中具体问题具体分析。
关于终止条件的指标可以是?
迭代次数/簇中心变化率/最小平方误差MSE
关于如何选择k?
• Subject-matter knowledge (There
are most likely five groups.)
• Convenience (It is convenient to
market to three to four groups.)
• Constraints (You have six products
and need six segments.)
• Arbitrarily (Always pick 20.)
• Based on the data (Ward’s method)
3.3 K-means的公式解释
记K个簇中心为μ1,μ2,μ3…,μk,每个簇数目为N1,N2,..Nk
使用平方误差作为目标函数:
对每个簇中,求每个样本到中心的距离的平方求和,然后将每个簇的误差相加。
该函数是关于μ1,μ2,μ3…,μk的凸函数,其驻点为:
所以是对目标函数的梯度下降。
如果对所有样本求梯度下降就是BGD
随机得对若干个样本做梯度下降就是随机下降法SGD.
将以上两者结合就是Mini-batch K-means算法。
根据上述目标函数,另外一个更深入的重点
其实对每一个簇,有一个前提假设:所有样本服从高斯分布。
如果将目标函数中的(xi-μi)^2换成绝对值|xi-μi|,那就是上面提到过的k-Mediods聚类
3.4K-means聚类方法的总结
优点1.解决聚类问题的一种经典算法,简单,快速
2.对处理大数据集,该算法保持可伸缩性和高效率
3.当簇近似为高斯分布,它的效果是较好的
缺点:
1.在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用
2.必须事先给出k,而且对初值敏感,对于不同的初始值,可能会导致不同的结果。
3.不适用于发现非凸形状的簇或者大小差别很大的簇
4.对噪声和孤立点数据敏感
k-means聚类算法可作为其他聚类算法的基础算法,如谱聚类。
4.其他聚类算法
4.1 Canopy算法
虽然Canopy算法可以划归为聚类算法,但更多的可以使用它做空间索引,其时空复杂度都很出色,算法描述如下:对于给定样本x1,x2…,xm;给定先验值r1,r2(r1< r2)
x1,x2…,xm形成一个列表L;同时构造一个空列表C。
随机选择L中的样本c,计算了Lz中样本xj与c的距离dj
若dj
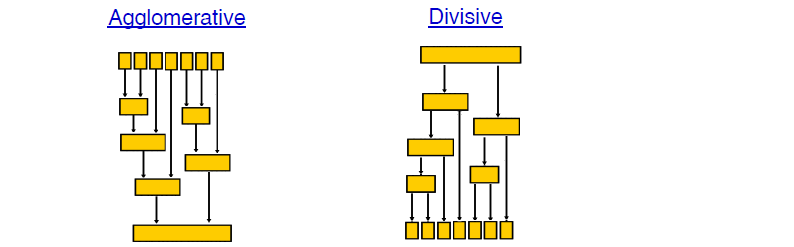
4.2 层次聚类方法
层次聚类方法对给定的数据集进行层次分解,直到某种条件满足为止。具体可以分为两类:凝聚的层次聚类AGNES
一种自底向上的策略,首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到某个终结条件被满足。
分裂的层次聚类DIANA
采用自顶向下的策略,它首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到到达了某个终结条件。
4.3 密度聚类法
密度聚类的指导思想是,只要样本点的密度大于某阀值,则将该样本添加到最近的簇中。基于距离的聚类只能发现“类圆形”的聚类(即高斯分布的假设),而密度聚类可以发现任意形状,并且对噪声数据不敏感。
但是计算密度单元的计算复杂度大,需要建立空间索引来降低计算量。
这里主要介绍两种密度聚类方法:DBSCAN和密度最大值法
4.3.1DBSCAN算法
全称:Densiti-Based Spatial Clustering of Applications with NoiseDBSCAN的若干概念:
对象的ε-邻域:给定对象在半径ε内的区域。
核心对象:对于给定的数目m,如果一个对象的ε-邻域至少包含m个对象,则称该对象为核心对象。
直接密度可达:给定一个对象集合D,如果p是在q的ε邻域内,而q是一个核心对象,我们说对象p从对象q出发是直接密度可达的。
密度可达:如果p直接密度可达p1,p1直接密度可达q,则说q是从对象p关于ε和m的密度可达。
密度相连:如果对象o与p,o与q都是密度可达,则说p和q室密度相连。
簇:一个基于密度的簇是最大的密度相连对象的集合。
噪声:不包含在任何簇中的对象称为噪声。
DBSCAN算法流程:
1.如果一个点p的ε-邻域包含多于m个对象,则创建一个p作为核心对象的新簇;
2.寻找并合并核心对象直接密度可达的对象;
3.没有新点可以更新簇时,算法结束
由上述算法可知:
每个簇至少包含一个核心对象;
非核心对象可以是簇的一部分,构成了簇的边缘。
包含过少对象的簇被认为是噪声
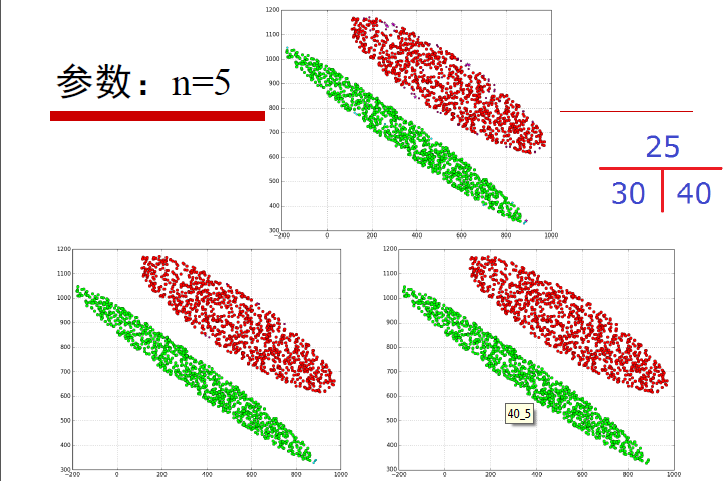
例子:
以下分别是m为5,ε=25,30,40的时候的聚类
4.3.2密度最大值聚类
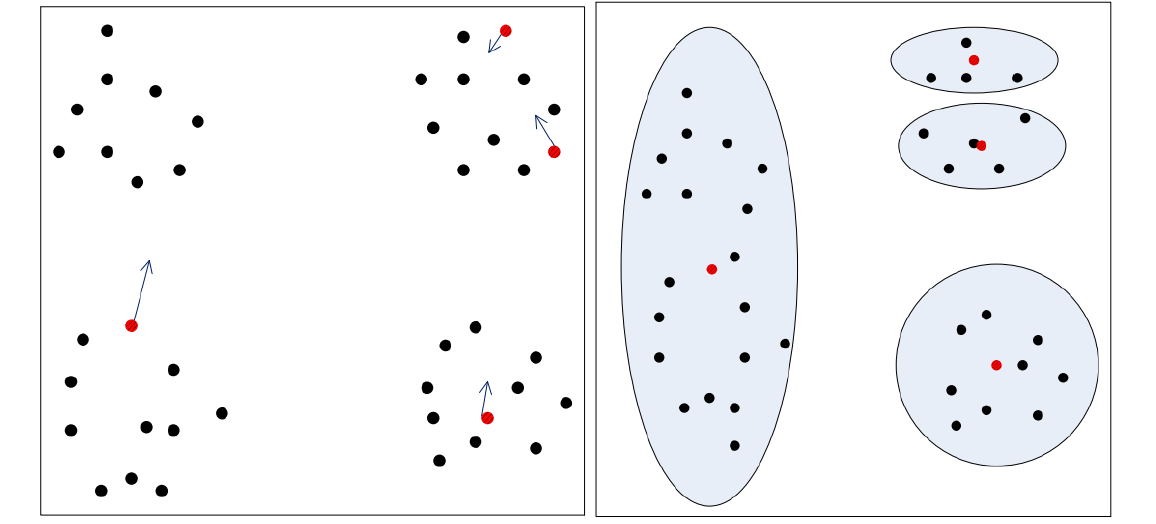
密度最大值聚类是一种简洁优美的聚类算法,可以识别各种形状的类簇,并且参数很容易确定。给定一个r值,对每个样本点xi,求出其以r为半径的圆内包含了多少个样本点,样本点的个数记为ρi,表示以xi的密度。于是我们可以求出ρ1,ρ2…ρm。
再对每个样本点,比如现在以x1为例。找出一堆离它距离比较近的点,比如x2,x4,x6,x7.
这4个点分别有自己的密度ρ2=6,ρ4=8,ρ6=4,ρ7=7.
假设ρ1=5,分别把ρ1与以上四个ρ值作比较,留下密度比自己大的样本点,所以剩下的是ρ2=6,ρ4=8,ρ7=7。
然后再求出x1分别到以上三个点的距离,分别是d2,d4,d7,选出距离最小的那个值,比如是d4,这个最小的距离我们记做δ1,即高局部密度点距离。
现在我们为x1求出了两个值:(ρ1,δ1)。
以此类推,所有的样本点xi都可以求出(ρi,δi)
想想,如果一个点的ρ和δ都很大,那么说明这个点的密度很大,并且密度比它大且离它最近的那个样本点距离它也比较远。也就说它们两可以自成一个类,彼此密度都很大,且距离也比较远。
如果一个点的ρ很小δ却很大,则说明它的密度很小,且离其他的大密度点也比较远,说明它是一个噪声!
簇中心的识别:那些有着比较大的局部密度ρi和很大的高密度距离的点被认为是簇的中心。
确定簇中心之后,其他点按照距离已知中心簇的中心最近进行分类。
(也可以按照密度可达方法进行分类)
举个例子:
左图是所有样本点在二维空间的分布,右图是以ρ为横坐标,以δ为纵坐标绘制的决策图。可以看到,1和10两个点的ρδ都比较大,作为簇中心、而26.27.28三个点的δ也比较大,但是ρ比较小,所以是噪声。
5.谱聚类
5.1 谱聚类的过程
(据说谱聚类是使用起来比较简单但是解释起来比较困难的。。。)假设我们有m个样本(a1,a2,…,am),每个样本的特征维度是n维。
现在将每个样本(ai,aj)根据特征两两求相似性wij。于是就有了m*m维的相似性矩阵W。
因为(ai,aj)的相似性 = (aj,ai)的相似性,所以这个相似性矩阵W是一个对称矩阵。
相似性矩阵W的的每一行都是ai与a1,a2,..am的相似性,将每行的值求和,每个样本点ai都会得到一个值di.
将di(d1,d2,…,dn)放在n*n矩阵的对角线上,形成了一个n*n的对角矩阵D。
好了现在我们有两个矩阵:对角矩阵D,与对称矩阵W
定义一个L矩阵:L=D-W
这个L的来头非常大,它就是拉普拉斯矩阵。
对这个L矩阵提取特征值与特征向量。
特征值:λ1,λ2,…,λm
特征向量:u1,u2,…,um
可以证明L是一个半正定矩阵,所以最小特征值肯定是0.(为什么是半正定,为什么半正定就有特征值0呢?这个不放在这里细讲先)
将所有特征值由小到大排列,取出最小的前k个特征值。将这些特征值对应的特征矩阵组合在一起。
因为一个特征矩阵ui是m*1维度。所有k个特征矩阵组合在一起就形成了m*k维度的大矩阵U。
U的行数是m,对应的是m个样本,列数为k,对应的是k个指标。
这k个指标可以看成是k个特征。
于是我们有了针对m个样本的k维特征的这样一组数据。直接将这组数据用于做k-means聚类即可。(其实就是将原来的特征用转换后的新的特征代替了)。
以上就是谱聚类的具体过程。
对了还要说一下相似度的计算,也就是W矩阵是咋滴来的。
有这样几个方法,一般都是用高斯相似性:
距离越大,相似度越小
关于高斯相似性的东东在“王小草【机器学习】笔记–支持向量机”一文的核函数处有解释。
6.聚类的衡量指标
6.1 在有标记的样本数据下
6.1.1 准确性Cluster Accuracy(CA)
CA计算 聚类正确的百分比;CA越大证明聚类效果越好.其计算公式为:
CA也叫purity。
purity方法的优势是方便计算,值在0~1之间,完全错误的聚类方法值为0,完全正确的方法值为1。同时,purity方法的缺点也很明显它无法对退化的聚类方法给出正确的评价,设想如果聚类算法把每篇文档单独聚成一类,那么算法认为所有文档都被正确分类,那么purity值为1!而这显然不是想要的结果。
6.1.2 RI
RI的公式表示为:其中TP是指应该被聚在一类的两个样本被正确分类了,TN是只不应该被聚在一类的两个文档被正确分开了,FP是不应该放在一类的文档被错误的放在了一类,FN只不应该分开的文档被错误的分开了。
6.1.3 F-meature
这是基于上述RI方法衍生出的一个方法,6.1.4 均一性Homogeneity
均一性是指一个簇只能包含一个类别的样本,即只对一个簇中的样本做考虑,至于这个类别是否还被归到了其他的簇中,它不管。均一性可以通过以下公式求得:
假设我们是已经知道这批聚类数据的真实类别的,聚类之后,在同一个簇中的类别,如果只有一个,那么这个簇的经验为0jj,均一性为1, 如果有大于1个类别,那么计算该类别下的簇的条件经验熵,如果条件经验熵越大,则均一性就越小。
均一性在0-1之间。
6.1.5 完整性Completeness
完整性是指同类别样本被归类到相同的簇中,至于这个簇中还有没有其他类别的样本,它不管。完整性的计算公式如下:
假设我们是已经知道这批聚类数据的真实类别的,聚类之后,如果同一个类的样本的确被全部分在了同一个簇中,那么这个类的经验熵就是0,完整性就是1,;反之,如果同一类的样本被分到了不同的簇中,H(K|C)的条件经验熵就会增大,从而完整性就降低了。
完整性在0-1之间。
6.1.6 V-meature
单一地考虑均一性与完整性两个指标都是片面的。通过以下公式我们将均一性与完整性的加权平均:
其实V-measure与F-measure是一样的,前者用的是经验熵,后者用的是频率。
6.1.7 ARI
Adjusted Rand index(调整兰德指数)(ARI)假设数据集S共有N个元素,我们对N个元素去做聚类。
用不同的聚类方法得到两个不同的聚类结果:
Xi,Yi分别为各自的簇。
(当然,如果事先知道样本的标签就更好,其中一个结果就是真实的结果,另一个是聚类得到的结果)
ai,bi分别为对应簇中的元素个数:
nij表示Xi和Yi两个簇中相同的元素的个数:
将以上关系表示成如下表格:
那么我们最终要求的ARI指数的计算公式为:
ARI取值范围为[−1,1],值越大意味着聚类结果与真实情况越吻合。从广义的角度来讲,ARI衡量的是两个数据分布的吻合程度。
其实ARI是由AR转变优化而来的,可将以上公式简写为:
6.1.8 AMI
AMI使用与ARI相同的几号,但是用的是信息熵。互信息为:
正则化的互信息为
X服从超几何分布,则互信息的期望是:
借鉴ARI,则AMI为:
6.2 在没有标记样本的情况下
6.2.1 Compactness(紧密性)(CP)
公式如下:CP计算 每一个类 各点到聚类中心的平均距离
CP越低意味着类内聚类距离越近
缺点:没有考虑类间效果
6.2.2 Separation(间隔性)(SP)
公式如下:SP计算 各聚类中心两两之间平均距离
SP越高意味类间聚类距离越远
缺点:没有考虑类内效果
6.2.3 Davies-Bouldin Index(戴维森堡丁指数)(分类适确性指标)(DB)(DBI)
公式如下:DB计算 任意两类别的类内距离平均距离(CP)之和除以两聚类中心距离 求最大值
DB越小意味着类内距离越小 同时类间距离越大
缺点:因使用欧式距离 所以对于环状分布 聚类评测很差
6.2.4 Dunn Validity Index (邓恩指数)(DVI)
公式如下:DVI计算 任意两个簇元素的最短距离(类间)除以任意簇中的最大距离(类内)
DVI越大意味着类间距离越大 同时类内距离越小
缺点:对离散点的聚类测评很高、对环状分布测评效果差
6.2.5 轮廓系数Silhouette
与以上评价指标不同,轮廓系数是不需要标记样本的。因为聚类本身是无监督的,要寻找有标记的样本比较困难。样本i到同簇其他样本的平均距离为ai;
样本i到最近的其他簇的所有样本的平均距离为bi;
于是轮廓系数的计算公式为:
所有样本轮廓系数的平均值称为聚类结果的轮廓系数。
轮廓系数越接近于1则聚类效果越好!

相关文章推荐
- 王小草【机器学习】笔记--分类算法之朴素贝叶斯
- 机器学习笔记 监督学习算法小结(一)
- Andrew Ng机器学习笔记week8 无监督学习(聚类、PCA)
- 【机器学习-斯坦福】学习笔记2 - 监督学习应用与梯度下降
- 机器学习实战笔记一 k-近邻算法
- 神经网络与机器学习笔记——K-均值聚类
- 机器学习(二)——K-均值聚类(K-means)算法
- 机器学习-斯坦福:学习笔记2-监督学习应用与梯度下降
- 【机器学习-斯坦福】学习笔记5 - 生成学习算法
- 【机器学习-斯坦福】学习笔记2 - 监督学习应用与梯度下降
- Andrew Ng 机器学习 第一课 监督学习应用.梯度下降 笔记
- 【机器学习-斯坦福】学习笔记5 - 生成学习算法
- 机器学习第四篇(stanford大学公开课学习笔记) —生成型学习算法之高斯判别分析模型和朴素贝叶斯方法
- 机器学习实战笔记2(k-近邻算法)
- 机器学习笔记(1)K-近邻算法
- 【机器学习-斯坦福】学习笔记5 - 生成学习算法
- [数据挖掘课程笔记]无监督学习——聚类(clustering)
- 【代码相似论文笔记】基于序列聚类的相似代码检测算法
- 【斯坦福---机器学习】复习笔记之监督学习应用.梯度下降