READING NOTE: Weakly Supervised Cascaded Convolutional Networks
2016-12-06 20:29
302 查看
TITLE: Weakly Supervised Cascaded Convolutional Networks
AUTHOR: Ali Diba, Vivek Sharma, Ali Pazandeh, Hamed Pirsiavash, Luc Van Gool
ASSOCIATION: KU Leuven, Sharif Tech., UMBC, ETH Zürich
FROM: arXiv:1611.08258
expensive human annotations.
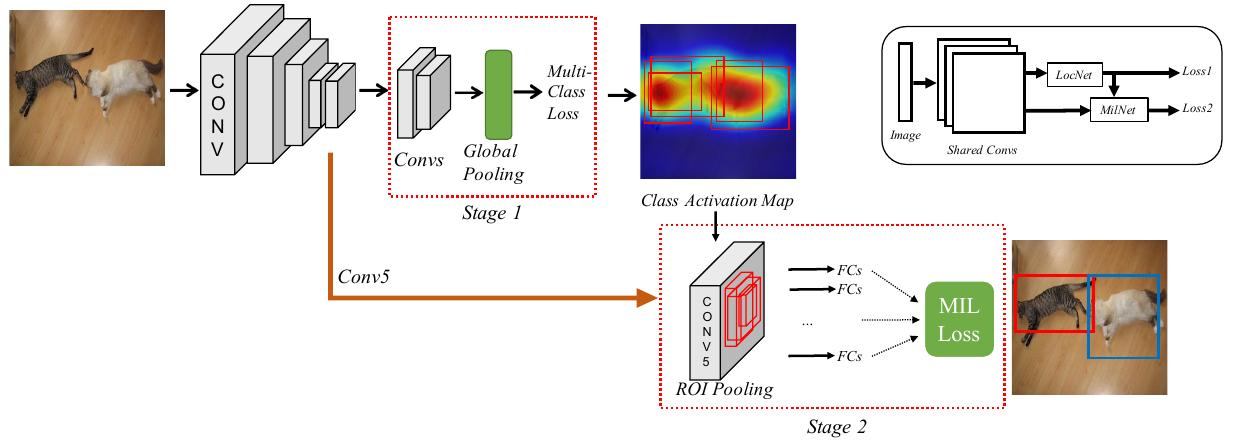
The first stage is a location network, which is a fully-convolutional CNN with a global average pooling or global maximum pooling. In order to learn multiple classes for single image, an independent loss function for each class is used. The class activation maps are used to select candidate boxes.
The second stage is multiple instance learning network. Given a bag for instances xc={xj|j=1,...,n} and a label set yc={yi|yi∈{0,1},i=1,..,C}, where each x is one of the condidate boxes, n is the number of candidate box, C is the number of categories and ∑Ci=1yi, the probabilities and loss can be defined as
Score(I,fi)=max(fi1,...,fin)
P(I,fi)=exp(Score(I,fi))∑Ck=1exp(Score(I,fk))
LMIL(P,y)=−∑i=1Cyilog(P(I,fi))
Im my understanding, only the boxes with the most confidence in each category will be punished if they are wrong. Besides, the equations in the paper have some mistakes.

The weak segmentation network uses the results of the first stage as supervision signal. sic is defined as the CNN score for pixel i and class c in image I. The score is normalized using softmax
Sic=exp(sic)/∑k=1Cexp(sik)
Considering y as the label set for image I , the loss function for the weakly supervised segmentation network is given by
Lseg(S,G,y)=−∑i=1Cyilog(Stcc)−∑i∈Isαilog(StcGi)
By tc=argmaxi∈ISic
where Gi is the supervision map for the segmentation from the first stage.
AUTHOR: Ali Diba, Vivek Sharma, Ali Pazandeh, Hamed Pirsiavash, Luc Van Gool
ASSOCIATION: KU Leuven, Sharif Tech., UMBC, ETH Zürich
FROM: arXiv:1611.08258
CONTRIBUTIONS
A new architecture of cascaded networks is proposed to learn a convolutional neural network handling the task withoutexpensive human annotations.
METHOD
This work trains a CNN to detect objects using image level annotaion, which tells what are in one image. At training stage, the input of the network are 1) original image, 2) image level labels and 3) object proposals. At inference stage, the image level labels are excluded. The object proposals can be generated by any method, such as Selective Search and EdgeBox. Two differenct cascaded network structures are proposed.Two-stage Cascade
The two-stage cascade network structure is illustrated in the following figure.The first stage is a location network, which is a fully-convolutional CNN with a global average pooling or global maximum pooling. In order to learn multiple classes for single image, an independent loss function for each class is used. The class activation maps are used to select candidate boxes.
The second stage is multiple instance learning network. Given a bag for instances xc={xj|j=1,...,n} and a label set yc={yi|yi∈{0,1},i=1,..,C}, where each x is one of the condidate boxes, n is the number of candidate box, C is the number of categories and ∑Ci=1yi, the probabilities and loss can be defined as
Score(I,fi)=max(fi1,...,fin)
P(I,fi)=exp(Score(I,fi))∑Ck=1exp(Score(I,fk))
LMIL(P,y)=−∑i=1Cyilog(P(I,fi))
Im my understanding, only the boxes with the most confidence in each category will be punished if they are wrong. Besides, the equations in the paper have some mistakes.
Three-stage Cascade
The three-stage cascade network structure adds a weak segmentation network between the two stages in the two-stage cascade network. It is illustrated in the following figure.The weak segmentation network uses the results of the first stage as supervision signal. sic is defined as the CNN score for pixel i and class c in image I. The score is normalized using softmax
Sic=exp(sic)/∑k=1Cexp(sik)
Considering y as the label set for image I , the loss function for the weakly supervised segmentation network is given by
Lseg(S,G,y)=−∑i=1Cyilog(Stcc)−∑i∈Isαilog(StcGi)
By tc=argmaxi∈ISic
where Gi is the supervision map for the segmentation from the first stage.
SOME IDEAS
This work requires little annotation. The only annotation is the image level label. However, this kind of training still needs complete annotation. For example, we want to detect 20 categories, then we need a 20-d vector to annotate the image. What if we only know 10/20 categories’ status in one image?
相关文章推荐
- 计算机导论2--语言与算法
- Ubuntu 14.04下Redis安装报错:“You need tcl 8.5 or newer in order to run the Redis test”问题解决
- 面试题总结
- 封装一个函数afterDate(date,n),得到日期date的n天后的日期
- 关于匿名内部类的问题
- elasticsearch使用river同步mysql数据
- aliyun阿里云Maven仓库镜像地址
- 实时操作系统内核的任务调度点
- 程序员的走与留?
- 希尔排序
- MPAndroidChart添加自定义样式
- web前端之锋利的jQuery七:jQuery表格应用、其他应用
- vmstat详解
- springMVC学习笔记(七) ---- json
- 4-19 Count Connected Components(DFS的栈实现+邻接表存图)
- 什么是产品运营?
- python 实践 九九乘法表
- codeforces 699C(广东工业大学新生杯决赛网络同步赛暨全国新生邀请赛)
- hdu2072 单词数
- 圆上的整数点