3、kafka中topic多Partition以提高读写速度
2016-12-05 00:00
896 查看
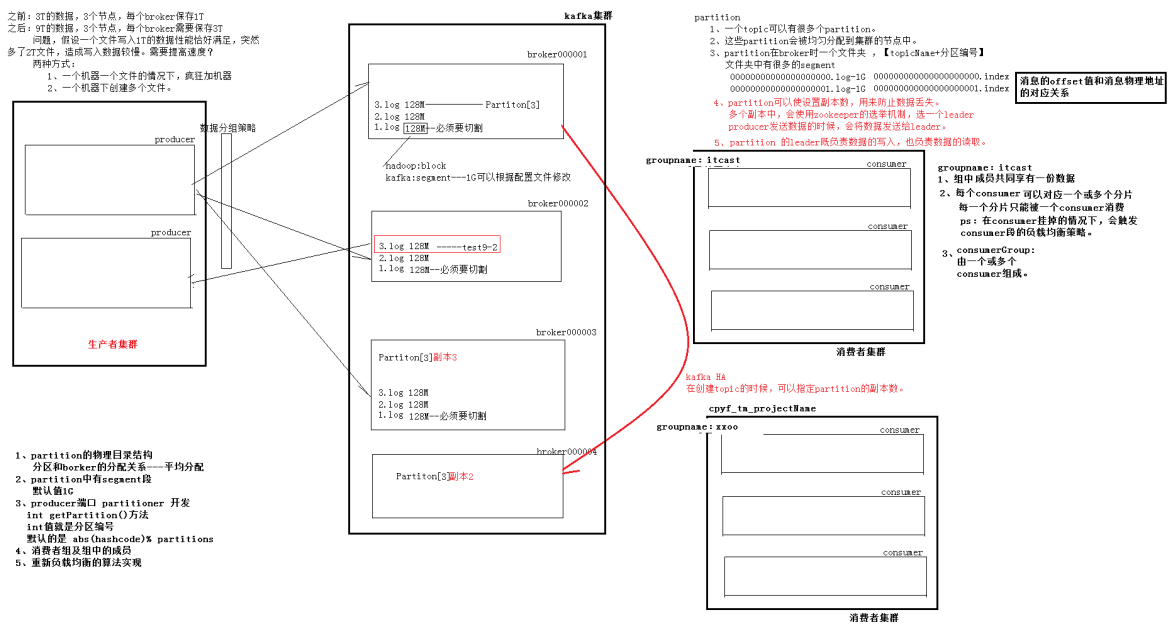
#总结:
##客户端:
当向kafka中生产消息的时候,需要指定topic、可以为这个topic指定多个partition,
每个partition可以指定有多个副本。如果有多个partition,producer端默认有getPartition()得到分区好来进行均匀读写。
##kafka端:
每个topic对应一个或者多个partition,partition会被均匀的配备到不同的broker上,
每个partition在磁盘上是一个文件夹[topic-partiton编号],他下面会有很多的文件,
因为一个partition的信息很大,可能有1T这么多,需要分割为多个小文件(segment)。
segment是成双成对出现的如下: 000000000000000000000.log 000000000000000000000.index
partition多个副本的时候,利用zookeeper的选举策略选择出leader,并且读写操作都是有leader负责,其他的flower只是打打酱油,备份一下而已。
##为什么要分为多个partition?
因为如果有很多的生产者需要往kafka集群中存入消息,如果partition只有一个的话,kafka的读写就会存在性能瓶颈,所以分为多个partition,每个partition在不同的broker上,那么就可以类似于HDFS,通过往多个datanode存储和读取数据,已凸显集群分布式的优势。
##那么为什么每个partition下又搞多个segment?
因为如果一个文件非常大的话,在读取数据时寻址是很困难的,但是如果分为了多个端,每段都有一个索引文件去对应,那么就可以快速的定位到需要读取的区间,这样提高读写操作。
#消费者集群:
1、组中的成员共享一份数据
2、每个consumor独享一个或者多个partition,也就是一个partition只能给一个consumor消费。
3、当consumor 5秒钟没有响应,被判定为挂掉,再过10秒钟没有响应,会触发consumor的负载均衡策略。也就是从新分配,分配算法还记得吗????、
4、通过分配算法,我们可以得出结论:
当consumor的数量大于partition数量时,后续的consumor不会得到partition分区消息。

相关文章推荐
- Qt中提高sqlite的读写速度
- 关于Xcode提高读写速度遇到的问题和一些想法
- Qt中提高sqlite的读写速度
- 疑问:调用Java NIO提高文件读写速度
- Qt中提高SQLite的读写速度
- 请问如何提高文件的读写速度
- Qt中提高sqlite的读写速度
- 用IO完成端口提高读写速度的探讨试验
- 调用Java NIO提高文件读写速度(1)
- 利用链接复用来提高数据库读写速度
- Linux下提高硬盘读写速度(hdparm)
- 如何提高多文件读写速度
- C#实现提高xml读写速度的方法
- Linux下提高硬盘读写速度
- Qt中提高sqlite的读写速度
- Windows文件读写(提高读写速度)
- Linux下提高硬盘读写速度
- 用IO完成端口提高读写速度的探讨试验
- 通过硬盘4K对齐,提高硬盘的读写速度!
- Qt中提高sqlite的读写速度