| paper title | code link | code depends | paper link | keywords | snapshot | |
| DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients | https://github.com/ppwwyyxx/tensorpack/tree/master/examples/DoReFa-Net | tensoflow | https://arxiv.org/pdf/1606.06160v2.pdf | 旷视,low bitwidth weights, CPU/FPGA | | |
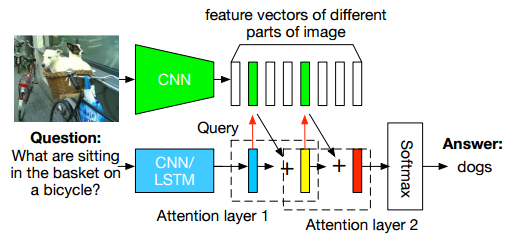
| Stacked attention networks for image question answering | https://github.com/zcyang/imageqa-san | Theano | https://arxiv.org/pdf/1511.02274.pdf | CMU,MSR, |
| |
| Newtonian Image Understanding: Unfolding the Dynamics of Objects in Statis Images | https://github.com/roozbehm/newtonian | Torch | https://arxiv.org/pdf/1511.04048.pdf | AI2 |

| |
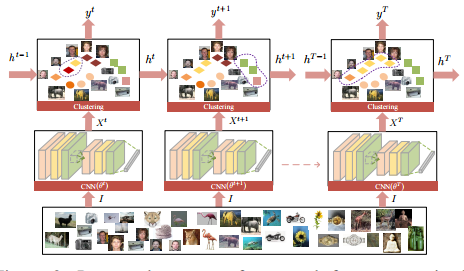
| Joint Unsupervised Learning of Deep Representations and Image Clusters | https://github.com/jwyang/joint-unsupervised-learning https://github.com/jwyang/JULE-Caffe | caffe | https://arxiv.org/pdf/1604.03628v3.pdf | 无监督,聚类 |
| |
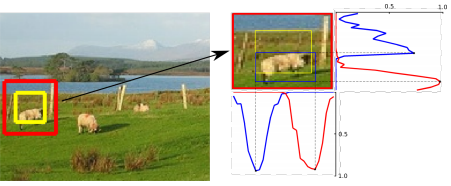
| Improving Localization Accuracy for Object Detection | https://github.com/gidariss/LocNet | caffe | https://arxiv.org/pdf/1511.07763v2.pdf | LOC,IoU |
| |
| Domain Guided Dropout for Person Re-identification | https://github.com/Cysu/dgd_person_reid | caffe | http://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Xiao_Learning_Deep_Feature_CVPR_2016_paper.pdf | CUHK | 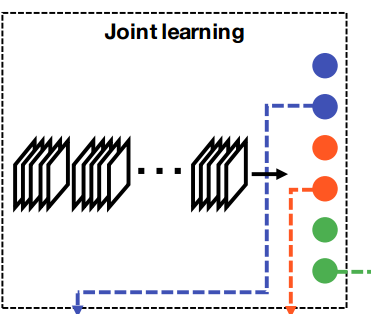
| |
| Repository containing wrapper to obtain various object proposals easily | https://github.com/batra-mlp-lab/object-proposals | matlab | https://arxiv.org/pdf/1505.05836.pdf | |

| |
| Pairwise Matching through Max-Weight Bipartite Belief Propagation | https://github.com/zzhang1987/HungarianBP | matlab | https://zzhang.org/pdfs/ZhangEtal2016Cvpr.pdf | UC |

| |
| Segment-CNN: A Framework for Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs | https://github.com/zhengshou/scnn | caffe | https://arxiv.org/pdf/1601.02129.pdf | UC, action |
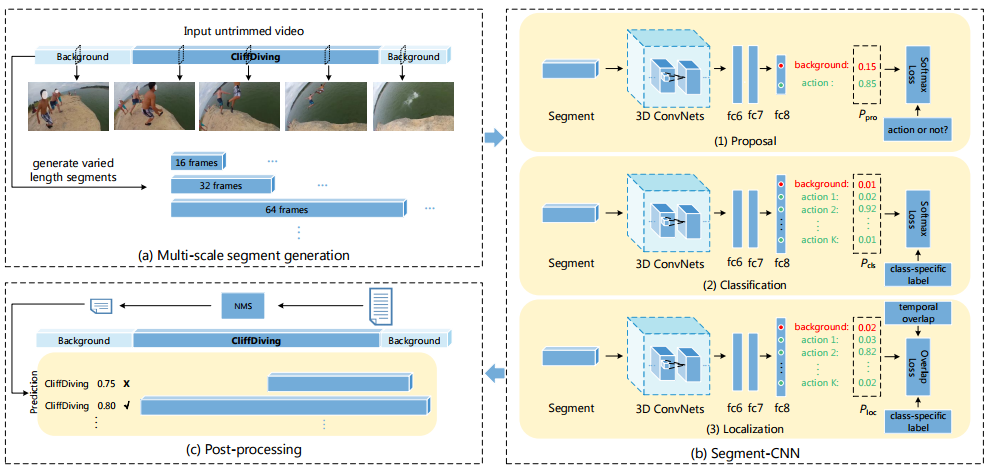
| |
| A Comparative Study for Single Image Blind Deblurring | https://github.com/phoenix104104/cvpr16_deblur_study | matlab | http://vllab1.ucmerced.edu/~wlai24/cvpr16_deblur_study/paper/cvpr16_deblur_study.pdf | UC,deblur |

| |
| Large-Scale Location Recognition and the Geometric Burstiness Problem | https://github.com/tsattler/geometric_burstiness | / | http://www.vision.ee.ethz.ch/en/publications/papers/proceedings/eth_biwi_01273.pdf | |

| |
| A Caffe-based implementation of very deep convolution network for image super-resolution | https://github.com/huangzehao/caffe-vdsr | caffe | http://cv.snu.ac.kr/research/VDSR/VDSR_CVPR2016.pdf | Super-Resolution |
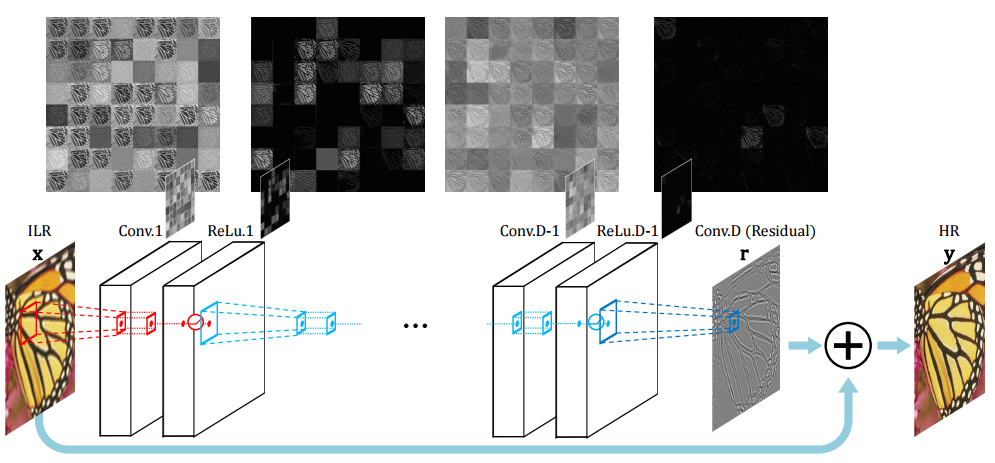
| |
| Dynamically neural network structures for multi-domain question answering | https://github.com/jacobandreas/nmn2 | caffe | https://arxiv.org/pdf/1511.02799v3.pdf | UC,Visual question answering |
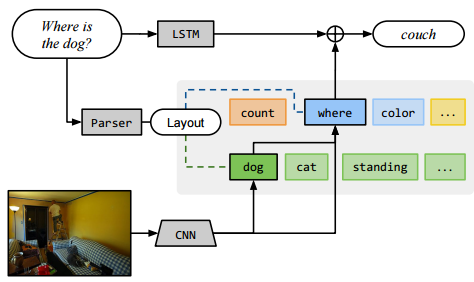
| |
| DPPnet: Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction | https://github.com/HyeonwooNoh/DPPnet | torch | https://arxiv.org/pdf/1511.05756v1.pdf | Visual question answering |
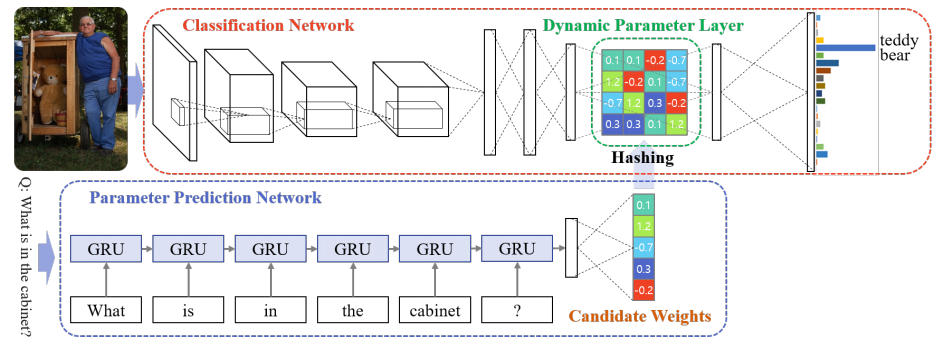
| |
| Shallow and Deep Convolutional Networks for Saliency Prediction | https://github.com/imatge-upc/saliency-2016-cvpr | caffe | http://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Pan_Shallow_and_Deep_CVPR_2016_paper.pdf | Saliency Prediction |

| |
| Main repository for Deep Metric Learning via Lifted Structured Feature Embedding | https://github.com/rksltnl/Deep-Metric-Learning-CVPR16 | caffe | http://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Song_Deep_Metric_Learning_CVPR_2016_paper.pdf | Stanford,Metric Learning |

| |
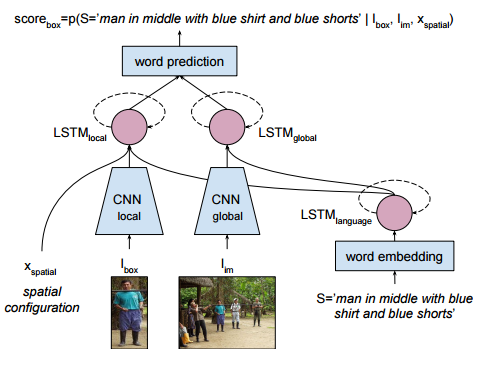
| Natural Language Object Retrieva | http://ronghanghu.com/text_obj_retrieval https://github.com/ronghanghu/natural-language-object-retrieval | caffe | https://arxiv.org/pdf/1511.04164.pdf | UC,NUS |
| |
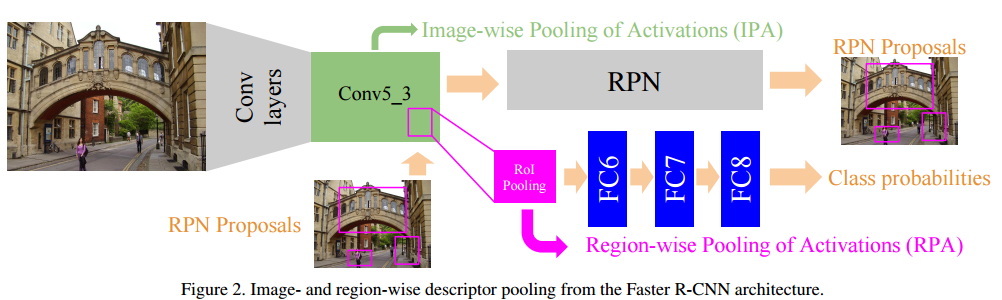
| Faster R-CNN features for Instance Search | https://github.com/imatge-upc/retrieval-2016-deepvision | caffe | https://arxiv.org/pdf/1604.08893v1.pdf | faster R-CNN |
| |
| Object Skeleton Extraction in Natural Images by Fusing Scale-associated Deep Side Outputs | https://github.com/zeakey/DeepSkeleton | caffe | https://arxiv.org/pdf/1603.09446v2.pdf | |

| |
| Accumulated Stability Voting: A Robust Descriptor From Descriptors of Multiple Scales | https://github.com/shamangary/ASV | matlab | https://drive.google.com/file/d/0B_q2Q4O-rzP6bmlxTzFyMGJfaWs/view?usp=drive_web | | | |
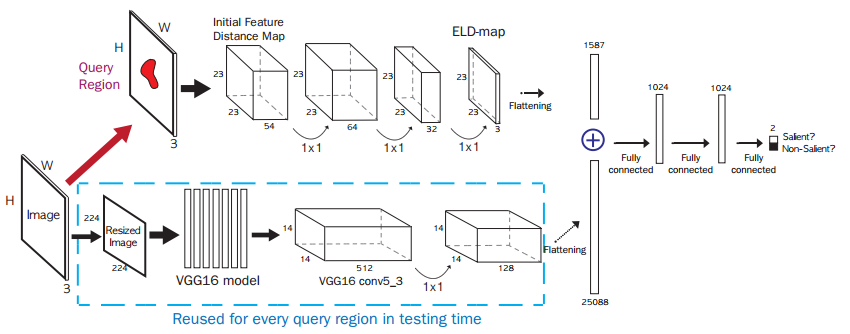
| Deep Saliency with Encoded Low Level Distance Map and High Level Features | https://github.com/gylee1103/SaliencyELD | caffe | https://arxiv.org/pdf/1604.05495v1.pdf | Saliency detection |
| |
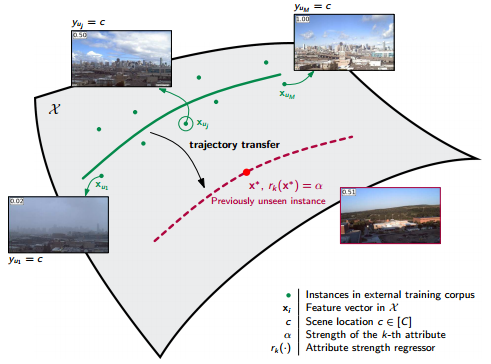
| One-Shot Learning of Scene Locations via Feature Trajectory Transfer | https://github.com/rkwitt/TrajectoryTransfer | / | http://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Kwitt_One-Shot_Learning_of_CVPR_2016_paper.pdf | |
| |
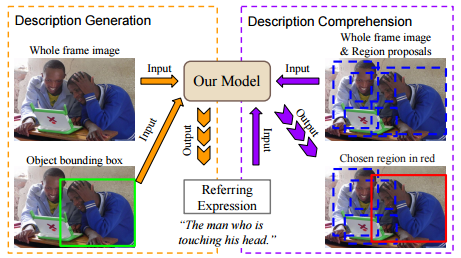
| Generation and Comprehension of Unambiguous Object Descriptions | https://github.com/mjhucla/Google_Refexp_toolbox | / | https://arxiv.org/abs/1511.02283 | google |
| |
| A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation (DAVIS) | https://github.com/fperazzi/davis | / | https://graphics.ethz.ch/~perazzif/davis/files/davis.pdf | Video object segmentation |

| |
| Activation function used in "Learning to Assign Orientations to Feature Points“ | https://github.com/nyanp/tiny-cnn/pull/61 | tiny-dnn | https://arxiv.org/pdf/1511.04273v2.pdf | |

| |
| DenseCap: Fully Convolutional Localization Networks for Dense Captioning | https://github.com/jcjohnson/densecap | torch | http://cs.stanford.edu/people/karpathy/densecap.pdf | Li Fei-Fe,FCLN |

| |
