Zookeeper、Hadoop、Sqoop、Mahout、HBase整合安装
2016-11-29 12:54
549 查看
环境说明
系统 CentOS 7.2用户 root
用户 hadoop
服务器3台
IP:10.1.5.51(master),10.1.5.52(slave1),10.1.5.53(slave2)
JAVA 1.7.X
Zookeeper版本:3.4.9
Hadoop版本:2.7.3
Sqoop版本:1.99.7
Spark版本:2.0.2
HBase版本 :1.2.4
风.fox
其他设置
防火墙
systemctl stop firewalld.service # 关闭firewall systemctl disable firewalld.service # 禁止firewall开机启动
用户设置
每台服务都要设置一样注意:如果不设置用户,那么hadoop将会以root用户启动,并且每次启动都要输入root的密码
useradd -m hadoop -s /bin/bash # 创建hadoop用户 passwd hadoop # 修改密码,这个时候会让你输入密码2次
注意:这里设置hadoop密码为hadoop,当然你可以设置其他密码
设置hadoop用户组为root用户组,即管理员权限
usermod -G root hadoop # 增加管理员权限
设置管理员或用户组权限
执行命令visudo
方法一
找到以下 一行 去除 前缀#号
%wheel ALL=(ALL) ALL
方法二
在root 那行增加 hadoop一行,如下所示
root ALL=(ALL) ALL hadoop ALL=(ALL) ALL
用户应用设置
退出当前用户root,改用hadoop登录用命令
su –,即可获得root权限进行操作
后续操作都是用
hadoop用户操作
用户设置无密码登录
切换用户su hadoop
进入当前用户目录 hadoop
cd ~ pwd
pwd 命令会显示如下目录
/home/hadoop
生成秘钥
mkdir -p /home/hadoop/.ssh cd ~/.ssh/ ssh-keygen -t rsa #如有提示,直接按回车 cat id_rsa.pub >> authorized_keys # 加入授权
以上部分要把 master 下的复制到 slave1,slave2上
slave1,slave2 服务器要建立.ssh文件
mkdir -p /home/hadoop/.ssh
传输文件
scp /home/hadoop/.ssh/authorized_keys slave1:/home/hadoop/.ssh/authorized_keys #传输到 slave1上 scp /home/hadoop/.ssh/authorized_keys slave2:/home/hadoop/.ssh/authorized_keys #传输到 slave2上
JAVA JDK安装和配置
安装 JAVA 1.7.X 版本http://blog.csdn.net/fenglailea/article/details/26006647
设置JAVA环境变量
统一把环境变量设置到 /etc/profile 最后设置全局变量(记得切换 用户,改完了在切换回来)
vim /etc/profile
http://blog.csdn.net/fenglailea/article/details/52457731
生效
. /etc/profile
Zookeeper 安装和配置
介绍请看
http://blog.csdn.net/fenglailea/article/details/53284263Zookeeper安装
wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz tar -zxvf zookeeper-3.4.9.tar.gz mv zookeeper-3.4.9 /home/hadoop/zookeeper
设置全局变量(记得切换 用户,改完了在切换回来)
vim /etc/profile
最后一行加入
export ZOOKEEPER_HOME=/home/hadoop/zookeeper export PATH=$ZOOKEEPER_HOME/bin:$PATH
使之生效
. /etc/profile
Zookeeper 配置
集群中任意一台机器上的zoo.cfg文件的内容都是一致的zoo.cfg
vim /home/hadoop/zookeeper/conf/zoo.cfg
增加
tickTime=2000 dataDir=/home/hadoop/zookeeper/data clientPort=2181 initLimit=5 syncLimit=2 server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888
机器配置:server.id=host:port:port(每行写一个)
server.X=A:B:C 其中X是一个数字, 表示这是第几号server. A是该server所在的IP地址. B配置该server和集群中的leader交换消息所使用的端口. C配置选举leader时所使用的端口.
我们需要在数据目录(数据目录就是dataDir参数指定的那个目录)下创建一个myid文件,myid中就是这个X数字
X的范围是1~255
tickTime: Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。毫秒值.
InitLimit : 允许 follower (相对于 leader 而言的“客户端”)连接并同步到 leader 的初始化连接时间,它以 tickTime 的倍数来表示。当超过设置倍数的 tickTime 时间,则连接失败。
syncLimit:该参数配置leader和follower之间发送消息, 请求和应答的最大时间长度. 此时该参数设置为2, 说明时间限制为2倍tickTime, 即4000ms.
dataDir: Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
dataLogDir : Zookeeper 保存日志的目录。
clientPort:客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
创建目录
mkdir -p /home/hadoop/zookeeper/data
设置 myid
echo "1" > /home/hadoop/zookeeper/data/myid
其他两台请自行设置
Zookeeper启动关闭
每台服务器都要启动
启动
/home/hadoop/zookeeper/bin/zkServer.sh start
返回以下信息启动成功
ZooKeeper JMX enabled by default Using config: /home/hadoop/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
其他操作
/home/hadoop/zookeeper/bin/zkServer.sh stop 停止 /home/hadoop/zookeeper/bin/zkServer.sh restart 重启 /home/hadoop/zookeeper/bin/zkServer.sh status 状态 /home/hadoop/zookeeper/bin/zkServer.sh upgrade /home/hadoop/zookeeper/bin/zkServer.sh print-cmd
客户端
/home/hadoop/zookeeper/bin/zkCli.sh -server localhost:2181
Zookeeper 3台服务器设置如下
10.1.5.51 master myid设置为 1 10.1.5.52 client1 myid设置为 2 10.1.5.53 client2 myid设置为 3
Hadoop 安装和配置
集群hosts设置
设置hosts(记得切换 用户,改完了在切换回来)vim /etc/hosts
master服务器增加
10.1.5.52 slave1 10.1.5.53 slave2
slave1服务器增加
10.1.5.51 master 10.1.5.53 slave2
slave2服务器增加
10.1.5.51 master 10.1.5.52 slave1
检测(例如master服务器中检测其他2个是否连接通)
ping slave1 -c 3 # 只ping 3次,否则要按 Ctrl+c 中断 ping slave2 -c 3
Hadoop安装
http://archive.apache.org/dist/hadoop/common/当前最新版 2.7.3
wget http://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz tar zxvf hadoop-2.7.3.tar.gz
安装Hadoop
mv hadoop-2.7.3 /home/hadoop/hadoop #目录位置 chmod -R +x /home/hadoop/hadoop/bin # 修改文件权限 chmod -R +x /home/hadoop/hadoop/sbin # 修改文件权限 mkdir -p /home/hadoop/hadoop/tmp #临时文件目录
Hadoop 环境变量设置
设置全局变量(记得切换 用户,改完了在切换回来)vim /etc/profile
最后一行加入
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_MAPRED_HOME=$HADOOP_HOME/share/hadoop/mapreduce export HADOOP_COMMON_HOME=$HADOOP_HOME/share/hadoop/common export HADOOP_HDFS_HOME=$HADOOP_HOME/share/hadoop/hdfs export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export YARN_HOME=$HADOOP_HOME/share/hadoop/yarn export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
这些变量在启动 Hadoop 进程时需要用到,不设置的话可能会报错(这些变量也可以通过修改 /home/hadoop/hadoop/etc/hadoop/hadoop-env.sh 实现)。
使之生效
. /etc/profile
Hadoop配置集群/分布式环境
集群/分布式模式需要修改 /home/hadoop/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml1, 文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,可以保留 localhost,也可以删掉,让 master 节点仅作为 NameNode 使用。
这里让
master节点即作为
NameNode使用,又作为节点使用,因此文件中原来的 localhost 保留,后面添加2行内容:slave1,slave2
vim /home/hadoop/hadoop/etc/hadoop/slaves
修改为:
localhost slave1 slave2
2, 文件 core-site.xml
vim /home/hadoop/hadoop/etc/hadoop/core-site.xml
改为下面的配置:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> </configuration>
3, 文件 hdfs-site.xml
dfs.replication 一般设为 3,但我们有3个 Slave 节点(master中那个也作为一个节点),
所以 dfs.replication 的值还是设为 3:
vim /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
修改为
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:50090</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/hadoop/tmp/dfs/data</value> </property> </configuration>
4, 文件 mapred-site.xml
cp -rf /home/hadoop/hadoop/etc/hadoop/mapred-site.xml.template /home/hadoop/hadoop/etc/hadoop/mapred-site.xml vim /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
然后配置修改如下:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
5, 文件 yarn-site.xml:
vim /home/hadoop/hadoop/etc/hadoop/yarn-site.xml
然后配置修改如下:
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
Hadoop集群 slave节点配置
配置好后,将 master 上的 /home/hadoop/hadoop 文件夹复制到各个节点上。如果之前有运行过分布式模式,建议在切换到集群模式前先删除之前的临时文件。
Hadoop执行
master 节点执行
rm -r /home/hadoop/hadoop/tmp # 删除 Hadoop 临时文件 rm -r /home/hadoop/hadoop/logs/* # 删除日志文件 cd /home/hadoop tar -zcvf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制 cd ~ scp ./hadoop.master.tar.gz slave1:/home/hadoop #传输到 slave1上 scp ./hadoop.master.tar.gz slave2:/home/hadoop #传输到 slave2上
slave 节点执行
rm -r /home/hadoop/hadoop # 删掉旧的(如果存在) tar -zxf ~/hadoop.master.tar.gz -C /home/hadoop
同样,如果有其他 Slave 节点,也要执行将 hadoop.master.tar.gz 传输到 Slave 节点、在 Slave 节点解压文件的操作。
首次启动 master 节点
需要先在master节点执行 NameNode 的格式化:
hdfs namenode -format # 首次运行需要执行初始化,之后不需要
最后出现下面表示格式化初始成功
...... 16/11/28 17:36:30 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 16/11/28 17:36:30 INFO util.ExitUtil: Exiting with status 0 16/11/28 17:36:30 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at slave1/10.1.5.52 ************************************************************/
Hadoop集群启动
启动需要在master节点上进行:
start-dfs.sh start-yarn.sh mr-jobhistory-daemon.sh start historyserver
通过命令
jps可以查看各个节点所启动的进程。正确的话,在
master节点上可以看到
NameNode、
ResourceManager、
SecondrryNameNode、
JobHistoryServer、
DataNode进程,如下所示:
2576 NodeManager 2276 ResourceManager 1959 DataNode 2711 JobHistoryServer 2125 SecondaryNameNode 30414 QuorumPeerMain 1823 NameNode 2751 Jps
在 Slave 节点可以看到 DataNode 和 NodeManager 进程,如下所示:
2640 NodeManager 2754 Jps 2499 DataNode
缺少任一进程都表示出错。另外还需要在 Master 节点上通过命令
hdfs dfsadmin -report
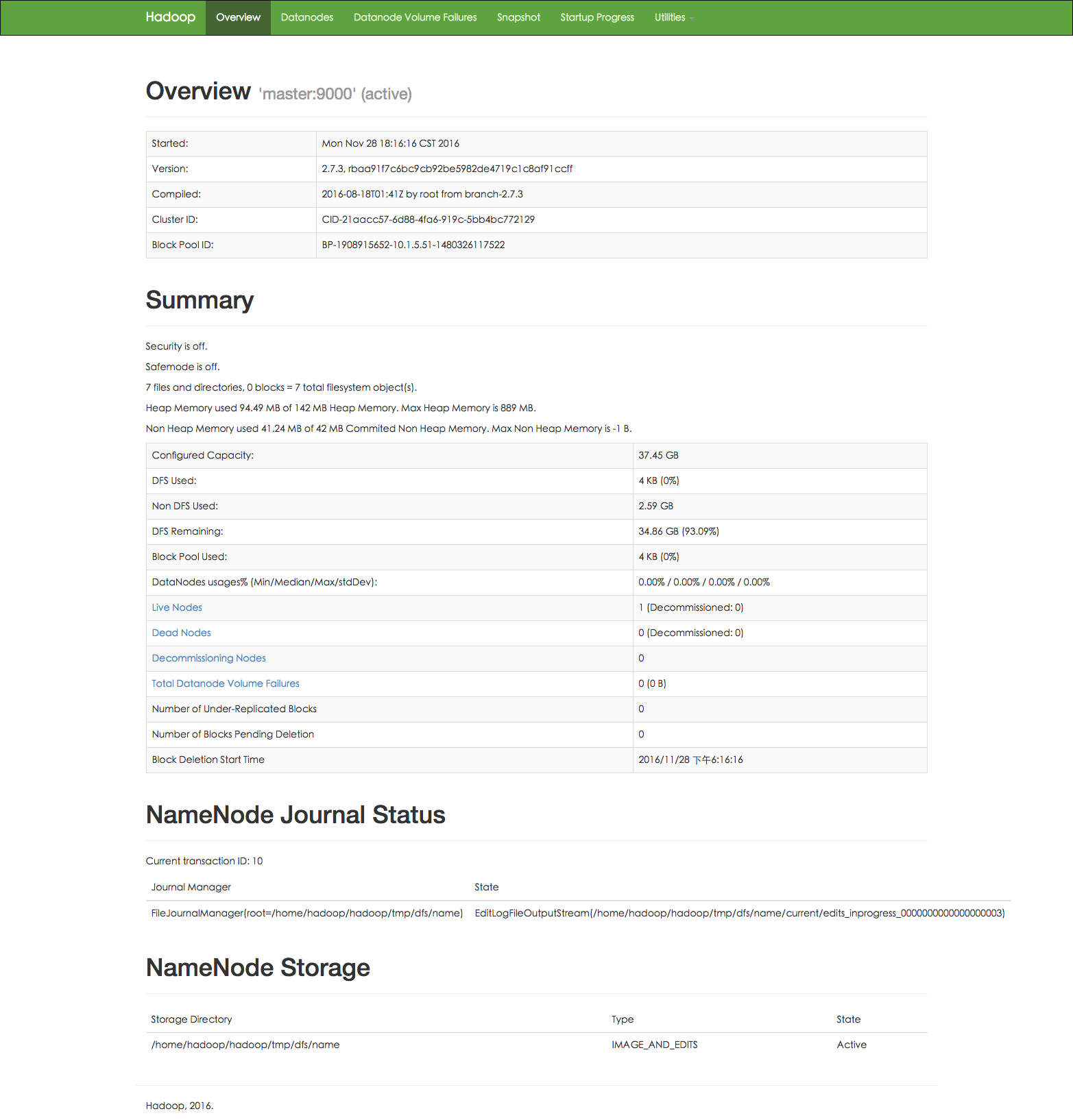
查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。例如我这边一共有 1 个 Datanodes:
Live datanodes (1): Name: 10.1.5.52:50010 (slave1) Hostname: slave1 Decommission Status : Normal Configured Capacity: 40207929344 (37.45 GB) DFS Used: 4096 (4 KB) Non DFS Used: 2779082752 (2.59 GB) DFS Remaining: 37428842496 (34.86 GB) DFS Used%: 0.00% DFS Remaining%: 93.09% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Mon Nov 28 18:23:20 CST 2016
也可以通过 Web 页面看到查看 DataNode 和 NameNode 的状态:
http://master:50070/ 或 http://10.1.5.51:50070/[/code]
如果不成功,可以通过启动日志排查原因。
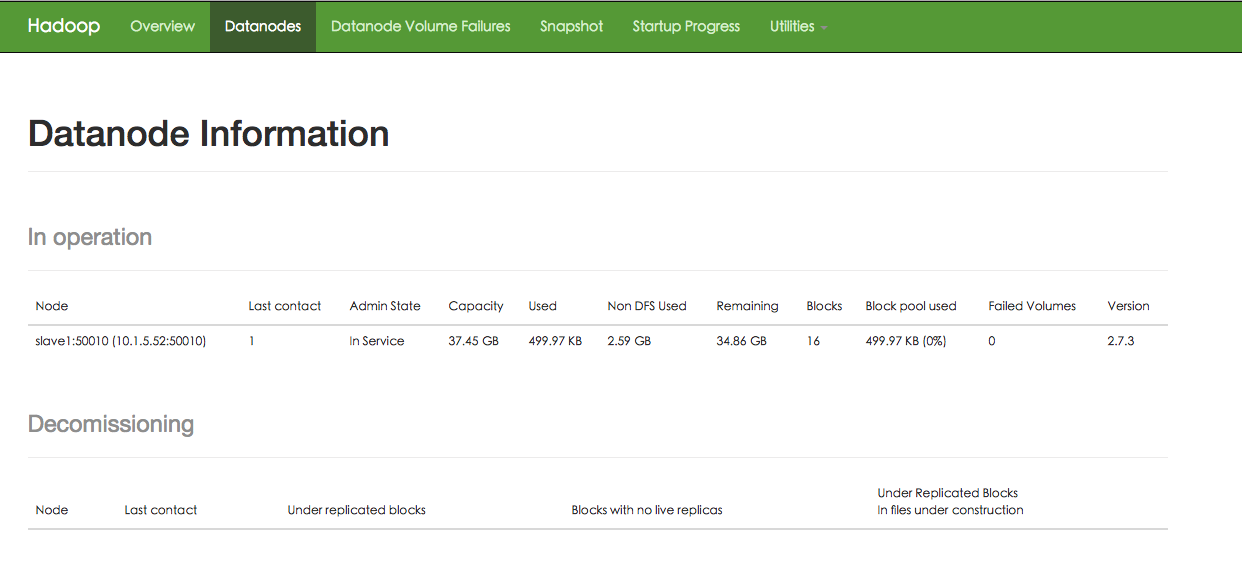
测试的时候使用1个节点,现在使用的为3个节点,所以下图 节点 是不对的,图就不重新传了Hadoop集群关闭
关闭 Hadoop 集群也是在 Master 节点上执行的:stop-yarn.sh stop-dfs.sh mr-jobhistory-daemon.sh stop historyserver
此外,同伪分布式一样,也可以不启动 YARN,但要记得改掉 mapred-site.xml 的文件名。执行分布式实例
执行分布式实例过程与伪分布式模式一样,首先创建 HDFS 上的用户目录:hdfs dfs -mkdir -p /user/hadoop
将 /usr/local/hadoop/etc/hadoop 中的配置文件作为输入文件复制到分布式文件系统中:hdfs dfs -mkdir input hdfs dfs -put /home/hadoop/hadoop/etc/hadoop/*.xml input
过查看 DataNode 的状态(占用大小有改变),输入文件确实复制到了 DataNode 中,如下图所示:
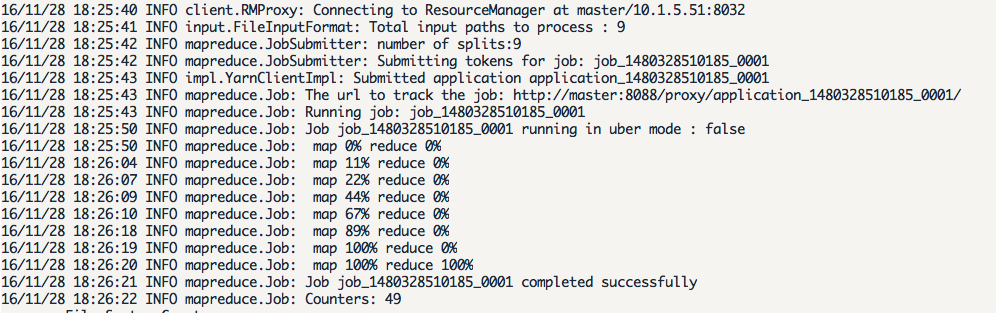
接着就可以运行 MapReduce 作业了:hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
运行时的输出信息与伪分布式类似,会显示 Job 的进度。
可能会有点慢,但如果迟迟没有进度,比如 5 分钟都没看到进度,那不妨重启 Hadoop 再试试。若重启还不行,则很有可能是内存不足引起,建议增大虚拟机的内存,或者通过更改 YARN 的内存配置解决。
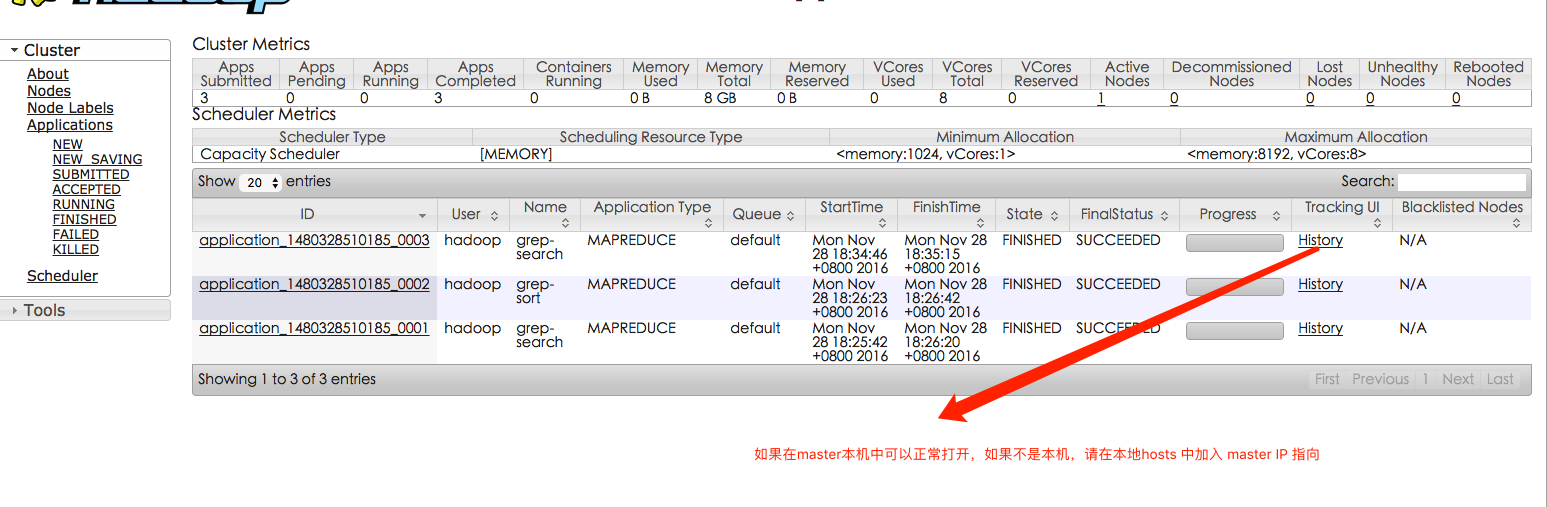
同样可以通过 Web 界面查看任务进度http://master:8088/cluster 或 http://10.1.5.52:8088/cluster[/code]
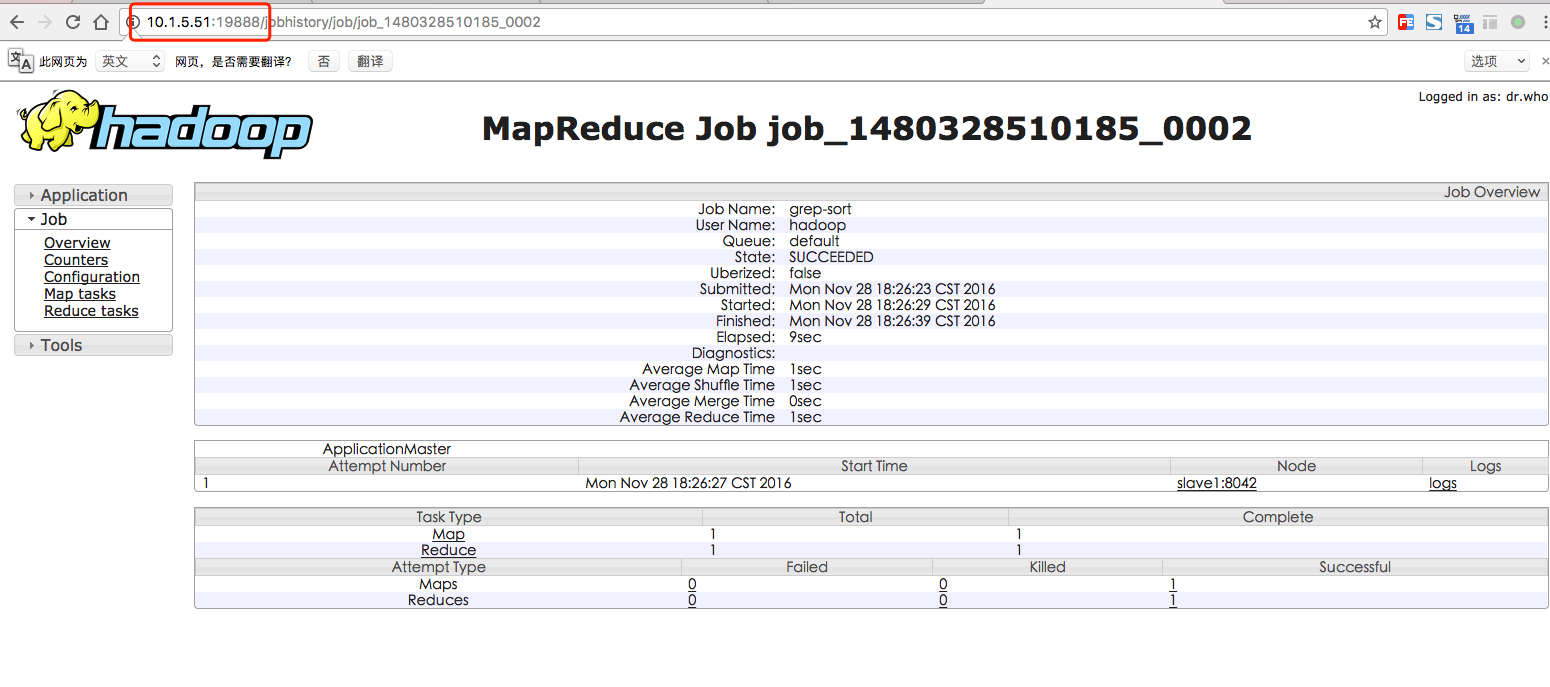
,在 Web 界面点击 “Tracking UI” 这一列的 History 连接,可以看到任务的运行信息,如下图所示:
执行完毕后的输出结果:hdfs dfs -cat output/*Mahout安装配置
Mahout下载地址
http://archive.apache.org/dist/mahout/
http://archive.apache.org/dist/mahout/0.12.2/wget http://archive.apache.org/dist/mahout/0.12.2/apache-mahout-distribution-0.12.2.tar.gz tar -zxvf apache-mahout-distribution-0.12.2.tar.gz mv apache-mahout-distribution-0.12.2 /home/hadoop/mahoutMahout环境变量设置
统一把环境变量设置到 /etc/profile 最后
设置全局变量(记得切换 用户,改完了在切换回来)vim /etc/profile
最后加入export MAHOUT_HOME=/home/hadoop/mahout export MAHOUT_CONF_DIR=$MAHOUT_HOME/conf export PATH=$MAHOUT_HOME/conf:$MAHOUT_HOME/bin:$PATH
应用环境变量. /etc/profile
查询是否安装成功,mahout
若出现一下,表示安装成功...... trainnb: : Train the Vector-based Bayes classifier transpose: : Take the transpose of a matrix validateAdaptiveLogistic: : Validate an AdaptivelogisticRegression model against hold-out data set vecdist: : Compute the distances between a set of Vectors (or Cluster or Canopy, they must fit in memory) and a list of Vectors vectordump: : Dump vectors from a sequence file to text viterbi: : Viterbi decoding of hidden states from given output states sequenceMahout 和Hadoop 集成测试
下载测试数据
http://archive.ics.uci.edu/ml/databases/synthetic_control/wget http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data[/code]hadoop 上传测试数据
hadoop fs -mkdir -p ./testdata hadoop fs -put synthetic_control.data ./testdata
查看目录及文件hadoop fs -ls hadoop fs -ls ./testdata使用Mahout中的kmeans聚类算法进行测试
mahout -core org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
XX执行完成,最后几行如下1.0 : [distance=55.039831561905785]: [33.67,38.675,39.742,41.989,37.291,43.975,31.909,25.878,31.08,15.858,13.95,23.097,19.983,21.692,31.579,38.57,33.376,38.843,41.936,33.534,39.195,32.897,25.343,18.523,15.089,17.771,22.614,25.313,23.687,29.01,41.995,35.712,40.872,41.669,32.156,25.162,24.98,23.705,18.413,20.975,14.906,26.171,30.165,27.818,35.083,39.514,37.851,33.967,32.338,34.977,26.589,28.079,19.597,24.669,23.098,25.685,28.215,34.94,36.91,39.749] 16/11/24 16:47:52 INFO ClusterDumper: Wrote 6 clusters 16/11/24 16:47:52 INFO MahoutDriver: Program took 22175 ms (Minutes: 0.3695833333333333)查看输出
hadoop fs -ls ./outputFound 15 items -rw-r--r-- 1 hadoop supergroup 194 2016-11-24 16:47 output/_policy drwxr-xr-x - hadoop supergroup 0 2016-11-24 16:47 output/clusteredPoints drwxr-xr-x - hadoop supergroup 0 2016-11-24 16:47 output/clusters-0 drwxr-xr-x - hadoop supergroup 0 2016-11-24 16:47 output/clusters-1 drwxr-xr-x - hadoop supergroup 0 2016-11-24 16:47 output/clusters-10-final drwxr-xr-x - hadoop supergroup 0 2016-11-24 16:47 output/clusters-2 drwxr-xr-x - hadoop supergroup 0 2016-11-24 16:47 output/clusters-3 drwxr-xr-x - hadoop supergroup 0 2016-11-24 16:47 output/clusters-4 drwxr-xr-x - hadoop supergroup 0 2016-11-24 16:47 output/clusters-5 drwxr-xr-x - hadoop supergroup 0 2016-11-24 16:47 output/clusters-6 drwxr-xr-x - hadoop supergroup 0 2016-11-24 16:47 output/clusters-7 drwxr-xr-x - hadoop supergroup 0 2016-11-24 16:47 output/clusters-8 drwxr-xr-x - hadoop supergroup 0 2016-11-24 16:47 output/clusters-9 drwxr-xr-x - hadoop supergroup 0 2016-11-24 16:47 output/data drwxr-xr-x - hadoop supergroup 0 2016-11-24 16:47 output/random-seeds查看数据
mahout vectordump -i ./output/data/part-m-00000Sqoop 安装配置
Sqoop 安装
http://archive.apache.org/dist/sqoop/wget http://archive.apache.org/dist/sqoop/1.99.7/sqoop-1.99.7-bin-hadoop200.tar.gz tar -zxvf sqoop-1.99.7-bin-hadoop200.tar.gz mv sqoop-1.99.7-bin-hadoop200 ~/sqoopSqoop环境变量设置
记得要切换用户vim /etc/profile
增加export SQOOP_HOME=/home/hadoop/sqoop export PATH=$SQOOP_HOME/bin:$PATH export CATALINA_BASE=$SQOOP_HOME/server export LOGDIR=$SQOOP_HOME/logs/
应用环境变量. /etc/profileSqoop与Hadoop整合配置
修改Sqoop 配置文件中的 Hadoop 配置文件路径vim /home/hadoop/sqoop/conf/sqoop.properties
修改为org.apache.sqoop.submission.engine.mapreduce.configuration.directory=/home/hadoop/hadoop/etc/hadoop/Sqoop启动
/home/hadoop/sqoop/bin/sqoop.sh server startSqoop关闭
/home/hadoop/sqoop/bin/sqoop.sh server stopSqoop客户端
/home/hadoop/sqoop/bin/sqoop.sh clientHBase安装配置
http://www.apache.org/dyn/closer.cgi/hbase/
http://archive.apache.org/dist/hbase/stable/
http://apache.fayea.com/hbase/wget http://mirrors.cnnic.cn/apache/hbase/1.2.4/hbase-1.2.4-bin.tar.gz tar zxvf hbase-1.2.4-bin.tar.gz mv hbase-1.2.4 ~/hbase chown -R hadoop:hadoop hbaseHBase配置
配置hbase-env.sh
vim /home/hadoop/hbase/conf/hbase-env.sh
修改export HBASE_CLASSPATH=/home/hadoop/hadoop/etc/hadoop #通过hadoop的配置文件找到hadoop集群 export HBASE_MANAGES_ZK=false #使用HBASE自带的zookeeper管理集群配置 hbase-site.xml
vim /home/hadoop/hbase/conf/hbase-site.xml
修改为<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hbase.master</name> <value>localhost:6000</value> </property> <property> <name>hbase.master.maxclockskew</name> <value>180000</value> </property> <property> <name>hbase.rootdir</name> <value>hdfs://master:9000/hbase</value> <description>hbase的存储根路径</description> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> <description>是否采用集群方式部署</description> </property> <property> <name>hbase.zookeeper.quorum</name> <value>master,slave1,slave2</value> <description>zookeeper的server地址,多台机器用逗号隔开</description> </property> <property> <name>zookeeper.session.timeout</name> <value>60000</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/hadoop/zookeeper/data</value> <description>zookeeper的数据存储目录</description> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.support.append</name> <value>true</value> <description>确保再使用HDFS存储时,不出现数据遗失</description> </property> </configuration>
hbase.master是指定运行HMaster的服务器及端口号;
hbase.master.maxclockskew是用来防止HBase节点之间时间不一致造成regionserver启动失败,默认值是30000;
hbase.rootdir指定HBase的存储目录;
hbase.cluster.distributed设置集群处于分布式模式;
hbase.zookeeper.quorum设置Zookeeper节点的主机名,它的值个数必须是奇数;
hbase.zookeeper.property.dataDir 指zookeeper集群data目录
dfs.replication设置数据备份数,集群节点小于3时需要修改,本次试验是一个节点,所以修改为1。HBase配置regionservers
vim /home/hadoop/hbase/conf/regionservers
修改为master slave1 slave2
设置所运行HBase的机器,此文件配置和hadoop中的slaves类似,一行指定一台机器软连接
hadoop 的hdfs-site.xml 链接到 conf目录下ln -s /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml /home/hadoop/hbase/conf/hdfs-site.xml
ZooKeeper 的 zoo.cfg 链接到 conf目录下ln -s /home/hadoop/zookeeper/conf/zoo.cfg /home/hadoop/hbase/conf/zoo.cfgHBase配置环境变量
设置全局变量(记得切换 用户,改完了在切换回来)vim /etc/profile
最后加入export HBASE_HOME=/home/hadoop/hbase export PATH=$PATH:$HBASE_HOME/bin
应用环境变量. /etc/profileHBase启动
/home/hadoop/hbase/bin/start-hbase.shHBase关闭
/home/hadoop/hbase/bin/stop-hbase.shFAQ
如果报 JAVA_HOME 没有配置
把 /etc/profile 中添加的环境变量加入到下面中,然后应用环境变量即可vim /etc/bashrc
http://www.powerxing.com/install-hadoop-cluster/
http://blog.sina.com.cn/s/blog_9f48885501011yfw.html
http://blog.csdn.net/javaman_chen/article/details/7191669


相关文章推荐
- hadoop-2.5.0,hbase,hive,pig,sqoop,zookeeper 集群安装
- Hadoop2.6.4、zookeeper3.4.6、HBase1.2.2、Hive1.2.1、sqoop1.99.7、spark1.6.2安装
- [置顶] hadoop+zookeeper+hbase+hive+mahout整合配置
- hbase安装配置(整合到hadoop) Huangguisu
- Hadoop+Hbase+ZooKeeper 安装配置及需要注意的事项
- Hadoop-HBase-Zookeeper安装记录
- hbase安装配置(整合到hadoop)
- hadoop,hbase,zookeeper安装配置
- hadoop+hbase+zookeeper集群安装方法 - mary的博客 - 51CTO技术博客
- hadoop+zookeeper+hbase安装_dekar_x的空间_百度空间
- Hadoop-1.0.3和hbase-0.92.1整合安装
- hadoop+hbase+zookeeper集群安装方法
- hbase安装配置(整合到hadoop)
- hbase安装配置(整合到hadoop)
- HADOOP__HBASE集群安装(自带ZOOKEEPER)
- hadoop生态系统搭建(hadoop hive hbase zookeeper oozie sqoop)
- Hadoop+Hbase+ZooKeeper 安装配置及需要注意的事项
- Hadoop 0.20.205.0 + zookeeper + hbase安装历程
- hadoop+hbase+zookeeper完全分布安装(1)
- apache-hadoop-1.2.1、hbase、hive、mahout、nutch、solr安装教程