验证码识别技术二——北京市
2016-11-27 15:28
274 查看
大约8个月前,曾经写过一篇关于验证码识别的文章,很久没再更新了,今天再来介绍一下北京市的验证码识别技术。

第二种是计算类,如下图:

我们将主要破解第一种类型的验证码,第二类验证码我们也做过,可以达到85%以上的识别率,但是第一类验证码我们可以达到更高的识别率,所以第二类暂且不做介绍。
**a)、观察图片:**拿过一组验证码图片,我们首先要能发现图片自身的特点有哪些,重点是哪些特性呢?
要识别的内容:字母+数字
是否存在噪音、前景背景是否易区分:存在噪音,背景色及噪音与字母区别较大,易去噪
多张验证码图片中字符的位置是否固定:基本固定
是否存在旋转、扭曲:存在一定程度的扭曲现象
字符是否易分割:存在部分粘连现象,不太好分割
b)、假设预估:[b]通过上面发现的图片特点,我们可以根据自己的经验,简单假设预估一下识别的策略以及识别的难度,这样也会对接下来的工作缕清一个基本思路。因此根据上面的5条内容,我们可以清楚,要进行分类的最多26+10个类别,噪音也容易去,而且位置基本固定,因此我们只要去噪然后按照固定位置切割基本就可以了。我们可以先通过该方法暴力切割,暂且不管是否存在扭曲,按照该思路进行破解,这是方案一。方案一思路很简单,也很容易实现,但该方式下的识别效果却并不是很好,甚至很差,尤其是倾斜角度稍大以及存在粘连字符的情况下基本就识别不出来了。因此我们接下来的重点工作就是如何处理扭曲的字符[/b]。
**c)、牛逼复杂算法VS投机取巧:**这一步我们的重点是想办法将扭曲的字符复原并解决字符粘连问题。关于这两个问题的处理,有很多优秀的算法及论文可以借鉴,大家感兴趣的可以自己去搜索一下,但是对我个人而言,不把我逼到那个份上我是不会用那些高大上的算法的,为什么呢?第一个是此类算法很复杂,想要真正弄明白并不是一件容易的事,而且并不一定适用于你当前的特定类型验证码图片处理。另外是验证码识别时间上的限制,大家都知道对于图片的处理,实际上是基于像素点的高维矩阵运算,应该说是很忌讳复杂运算的。

那么仔细观察图片,你会发现每个图片左侧或者右侧都会有一些黑色的噪音点,图中两个红色框中所示,那么根据这些噪音点的形状以及验证码字符的扭曲形状,你发现了什么端倪吗?不错,左边的黑色噪音点将字符向右偏移,偏移量取决于噪音的多少,同理右侧也是一样,因此根据这个特点,我们就可以将扭曲的验证码复原,再次按照固定位置切割,一举两得,而且识别效果也是很高的。这就是我一开始就提出的,一定要发现图片的固有特点,取巧的方式不仅可以降低识别复杂度,还会从根本上提升识别率。
欲识别的验证码图片原图是:

去噪的方式:以当前点[i,j]为中心点的3*3矩阵框里凡是超过5个像素点的RGB中的B通道结果值大于200,则认为当前点[i,j]是噪音点。注意:使用opencv得到的三通道顺序是BGR。
去噪效果图如下:

第二步:复原扭曲前的验证码图片:
这一步主要是根据噪音的多少进行逆向复原,左侧噪音的区间在[0, 8],右侧的噪音区间范围是[142,150]。下面给出具体代码:
复原效果图如下:
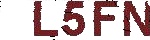
第三步:固定位置切割
切割位置如下:
切割效果如下所示:



第四步:二值化图片
第五步:生成训练集、训练模型
第六步:测试。。。(后面的步骤就不再重复了,可以参照天津市的处理方法)
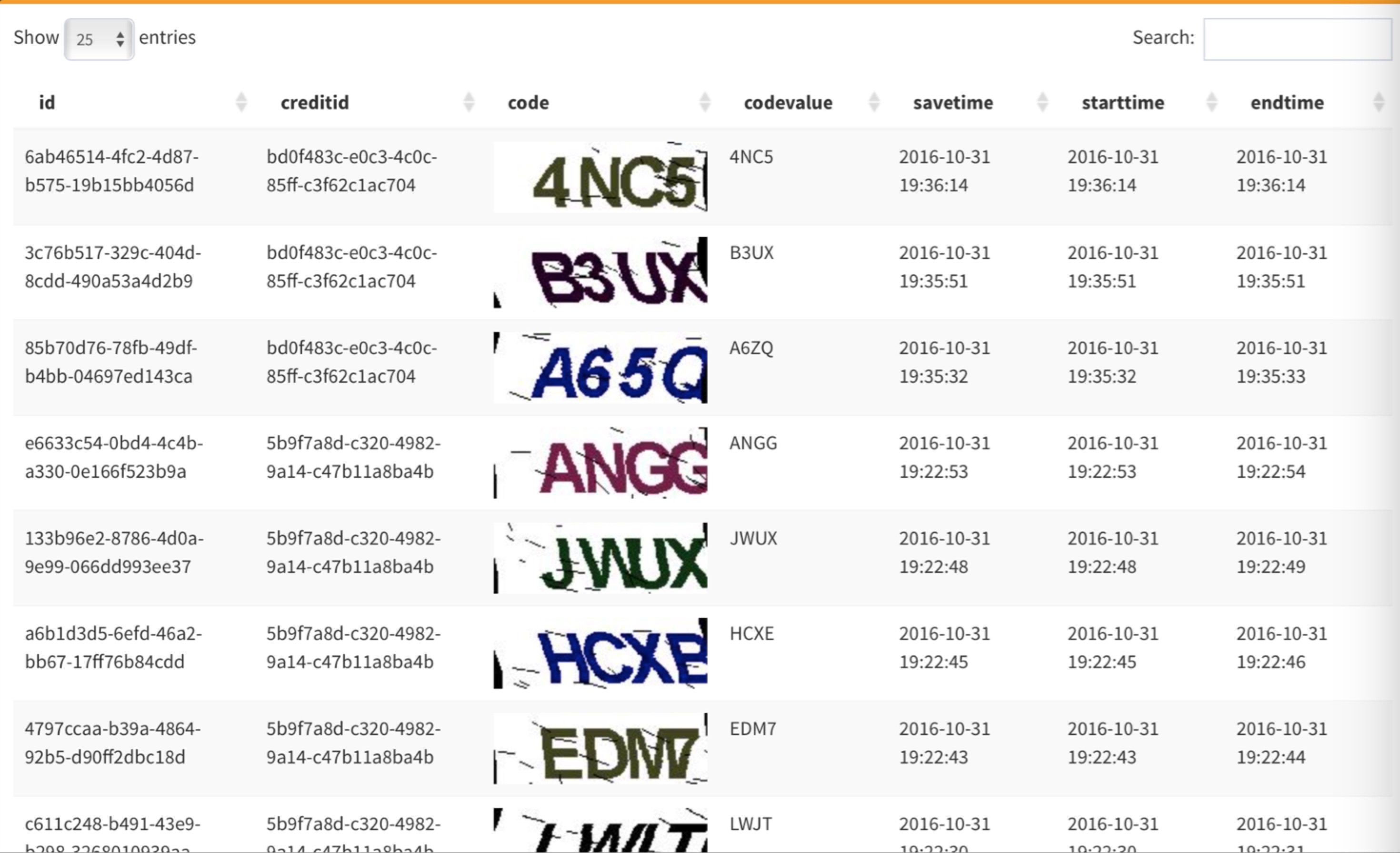
下面是一个测试效果图,其中savetime是验证码入库时间,starttime是验证码开始识别时间,endtime是验证码识别结束时间,整体上可以达到可用状态。
关于完整的代码现阶段还不方便公开,但是核心的代码部分以及识别思路都说的很清楚了,感兴趣的可以自己尝试一下!
1、验证码样例
北京市验证码有两种类型,第一种类型是四个字母或数字混合类,如下图:第二种是计算类,如下图:
我们将主要破解第一种类型的验证码,第二类验证码我们也做过,可以达到85%以上的识别率,但是第一类验证码我们可以达到更高的识别率,所以第二类暂且不做介绍。
2、识别思路
在我们识别验证码的过程中,我们并不会去使用一些高深复杂的算法,最主要是我们还是小白,很多高大上的算法我们暂时还整不明白它的原理,其次是再牛逼的算法不可能具有很强的通用性可以一次性识别多种类型的验证码。因此在进行识别的过程中都是充分挖掘图片的固有特定,寻找巧劲,利用“投机取巧”的方式进行破解,在一点在该篇文章讲解的识别方法中尤为重要。**a)、观察图片:**拿过一组验证码图片,我们首先要能发现图片自身的特点有哪些,重点是哪些特性呢?
要识别的内容:字母+数字
是否存在噪音、前景背景是否易区分:存在噪音,背景色及噪音与字母区别较大,易去噪
多张验证码图片中字符的位置是否固定:基本固定
是否存在旋转、扭曲:存在一定程度的扭曲现象
字符是否易分割:存在部分粘连现象,不太好分割
b)、假设预估:[b]通过上面发现的图片特点,我们可以根据自己的经验,简单假设预估一下识别的策略以及识别的难度,这样也会对接下来的工作缕清一个基本思路。因此根据上面的5条内容,我们可以清楚,要进行分类的最多26+10个类别,噪音也容易去,而且位置基本固定,因此我们只要去噪然后按照固定位置切割基本就可以了。我们可以先通过该方法暴力切割,暂且不管是否存在扭曲,按照该思路进行破解,这是方案一。方案一思路很简单,也很容易实现,但该方式下的识别效果却并不是很好,甚至很差,尤其是倾斜角度稍大以及存在粘连字符的情况下基本就识别不出来了。因此我们接下来的重点工作就是如何处理扭曲的字符[/b]。
**c)、牛逼复杂算法VS投机取巧:**这一步我们的重点是想办法将扭曲的字符复原并解决字符粘连问题。关于这两个问题的处理,有很多优秀的算法及论文可以借鉴,大家感兴趣的可以自己去搜索一下,但是对我个人而言,不把我逼到那个份上我是不会用那些高大上的算法的,为什么呢?第一个是此类算法很复杂,想要真正弄明白并不是一件容易的事,而且并不一定适用于你当前的特定类型验证码图片处理。另外是验证码识别时间上的限制,大家都知道对于图片的处理,实际上是基于像素点的高维矩阵运算,应该说是很忌讳复杂运算的。
那么仔细观察图片,你会发现每个图片左侧或者右侧都会有一些黑色的噪音点,图中两个红色框中所示,那么根据这些噪音点的形状以及验证码字符的扭曲形状,你发现了什么端倪吗?不错,左边的黑色噪音点将字符向右偏移,偏移量取决于噪音的多少,同理右侧也是一样,因此根据这个特点,我们就可以将扭曲的验证码复原,再次按照固定位置切割,一举两得,而且识别效果也是很高的。这就是我一开始就提出的,一定要发现图片的固有特点,取巧的方式不仅可以降低识别复杂度,还会从根本上提升识别率。
3、具体实现:
第一步:去噪欲识别的验证码图片原图是:
去噪的方式:以当前点[i,j]为中心点的3*3矩阵框里凡是超过5个像素点的RGB中的B通道结果值大于200,则认为当前点[i,j]是噪音点。注意:使用opencv得到的三通道顺序是BGR。
去噪效果图如下:
第二步:复原扭曲前的验证码图片:
这一步主要是根据噪音的多少进行逆向复原,左侧噪音的区间在[0, 8],右侧的噪音区间范围是[142,150]。下面给出具体代码:
im1 = im[10:, ...] # 截取整个图片下面 40 行,减小矩阵大小,减小计算量 im2 = np.ones((40, 150, 3)) * 255 # 初始化复原图片画布 for ii in range(40): # 验证码图片大小 40*150 num1 = 0 num2 = 0 for jj in range(8): if im1[ii, jj, 0] < 10 or im1[ii, jj, 1] < 10 or im1[ii, jj, 2] < 10: num1 += 1 # 第i行左侧黑色噪音数量 for jj in range(142, 150): if im1[ii, jj, 0] < 10 or im1[ii, jj, 1] < 10 or im1[ii, jj, 2] < 10: num2 += 1 # 第i行右侧黑色噪音数量 if num1 != 0: for jj in range(num1, 150): im2[ii, jj - num1,] = im1[ii, jj,] # 依次向左平移 elif num2 != 0: for jj in range(150 - num2): im2[ii, jj + num2,] = im1[ii, jj,] # 依次向右平移 else: for jj in range(150): im2[ii, jj,] = im1[ii, jj,] # 保持不变
复原效果图如下:
第三步:固定位置切割
切割位置如下:
im11 = im2[:, 34:61, ] im12 = im2[:, 62:89, ] im13 = im2[:, 91:118, ] im14 = im2[:, 122:149, ]
切割效果如下所示:
第四步:二值化图片
第五步:生成训练集、训练模型
第六步:测试。。。(后面的步骤就不再重复了,可以参照天津市的处理方法)
4、模型效果:
模型共采用约40张图片作为训练集,预测模型采用随机森林算法,算法中树的数量为25,其他为默认参数值,识别准确率在95%以上,识别时间约0.17s/个。下面是一个测试效果图,其中savetime是验证码入库时间,starttime是验证码开始识别时间,endtime是验证码识别结束时间,整体上可以达到可用状态。
关于完整的代码现阶段还不方便公开,但是核心的代码部分以及识别思路都说的很清楚了,感兴趣的可以自己尝试一下!
