基于Hadoop1.2.1完全分布式集群的部署
2016-11-25 15:00
531 查看

一、准备工作
同一个局域网中的三台Linux虚拟机,发行版本均使用64位CentOS6.3,主机是 Windows 10 64位操作系统;通过 vmware workstation 实现三台虚机,这样就形成了一个以物理机为DNS服务器的局域网,物理机和3台虚机都有一个局域网IP,从而实现相互之间的通信。Hadoop是一个用java语言编程的开源软件,所以需要安装JDK,小编采用的JDK的版本是最新的jdk1.8;此外,Hadoop集群部分功能是用perl语言实现的,因此,还需安装perl环境;集群之间的通讯是通过SSH实现的,这就不需要小编介绍啦!你懂的......
安装Linux后一定要确讣iptables,selinux等防火墙戒访问控制机制已经关闭,否则实
验很可能受影响.
本次试验搭建的环境为:
namenode : 192.168.115.130 matser
datanode1:192.168.115.131 slave
datanode2:192.168.115.132 slave
二、配置hosts
在所有节点上(namenode、datanode1、datanode2)的终端上通过 vi /etc/hosts上添加如下代码:192.168.115.130 namenode 192.168.115.131 datanode1 192.168.115.132 datanode2
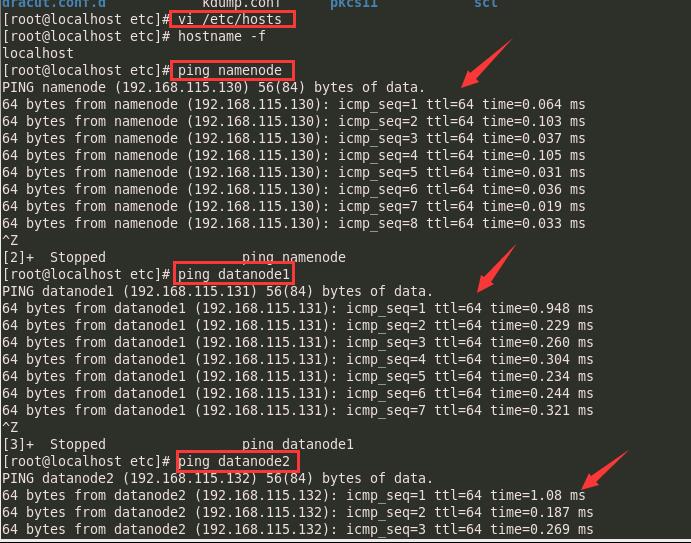
查看能否ping通,若出现下图,标识配置hosts成功:
三、JDK的安装
终端使用wget下载 jdk-8u111-linux-x64.tar.gzwge http://download.oracle.com/otn-pub/java/jdk/8u111-b14/jdk-8u111-linux-x64.tar.gz[/code]
解压 tar -xzvf jdk-8u111-linux-x64.tar.gz[root@namenode tpf]# tar -xzvf jdk-8u111-linux-x64.tar.gz
配置环境变量 vi /etc/profile ,在文件的结尾处添加如下代码,保存退出。#JAVA JAVA_HOME=/usr/local/jdk1.8.0_111 PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME PATH CLASSPATH
执行source /etc/profile,使修改的文件生效。
查看文件是否生效 echo $PATH[root@namenode Desktop]# echo $PATH /usr/local/jdk1.8.0_111/bin:/usr/local/jdk1.8.0_111/jre/bin:/usr/local/bin:/usr/bin:/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/tpf/bin
依次输入如下三个命令,出现下图情况,表示JDK安装成功;[root@namenode Desktop]# java -version java version "1.8.0_111" Java(TM) SE Runtime Environment (build 1.8.0_111-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)
常规来说,如果出现上图,JDK的安装可能是成功的,但要想确保安装准确无误,需要进一步验证(见下图):[root@namenode Desktop]# java Usage: java [-options] class [args...] (to execute a class) or java [-options] -jar jarfile [args...] (to execute a jar file) where options include: -d32 use a 32-bit data model if available -d64 use a 64-bit data model if available -server to select the "server" VM The default VM is server. -cp <class search path of directories and zip/jar files> -classpath <class search path of directories and zip/jar files> A : separated list of directories, JAR archives, and ZIP archives to search for class files. -D<name>=<value> set a system property -verbose:[class|gc|jni] [root@namenode Desktop]# javac Usage: javac <options> <source files> where possible options include: -g Generate all debugging info -g:none Generate no debugging info -g:{lines,vars,source} Generate only some debugging info -nowarn Generate no warnings -verbose Output messages about what the compiler is doing -deprecation Output source locations where deprecated APIs are used -classpath <path> Specify where to find user class files and annotation processors -cp <path> Specify where to find user class files and annotation processors -sourcepath <path> Specify where to find input source files -bootclasspath <path> Override location of bootstrap class files -extdirs <dirs> Override location of installed extensions -endorseddirs <dirs> Override location of endorsed standards path -proc:{none,only} Control whether annotation processing and/or compilation is done. -processor <class1>[,<class2>,<class3>...] Names of the annotation processors to r
如果出现上述图形的情况,小编恭喜你JDK安装成功啦!四、SSH互信
在虚机192.168.115.130/namenode节点上root权限下运行命令 ssh-keygen -t rsa[root@namenode tpf]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: 2d:ed:ec:31:00:eb:18:23:59:83:8b:1f:df:ee:73:9b root@namenode The key's randomart image is: +--[ RSA 2048]----+ | | | . | | . o . | | . + . o o | |. = o . S o | | . + * = | | . o o = | | .. .o o | | .ooE.. | +-----------------+
查看密钥[root@namenode tpf]# cd /root/ [root@namenode ~]# ls anaconda-ks.cfg Desktop Documents Downloads install.log install.log.syslog Music Pictures Public Templates Videos [root@namenode ~]# ls -a . .bash_history .bashrc .dbus Downloads .gconfd .gnupg .gvfs install.log.syslog .nautilus Public .recently-used.xbel .tcshrc .xauthCtsxNO .. .bash_logout .config Desktop .esd_auth .gnome2 .gstreamer-0.10 .ICEauthority .local .oracle_jre_usage .pulse .spice-vdagent Templates anaconda-ks.cfg .bash_profile .cshrc Documents .gconf .gnote .gtk-bookmarks install.log Music Pictures .pulse-cookie .ssh Videos [root@namenode ~]# cd .ssh/ [root@namenode .ssh]# ls id_rsa id_rsa.pub known_hosts
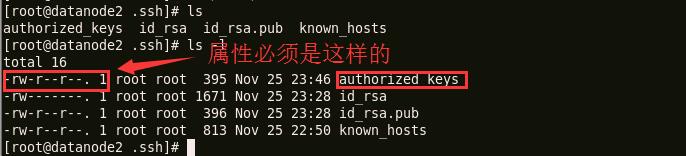
查看文件的属性,确保下图所示的文件属性[root@namenode .ssh]# ls -l total 12 -rw-------. 1 root root 1675 Nov 25 23:03 id_rsa -rw-r--r--. 1 root root 395 Nov 25 23:03 id_rsa.pub -rw-r--r--. 1 root root 2392 Nov 25 11:10 known_hosts
转到虚机192.168.115.131 slave/datanode1节点上以root权限重复上述步骤生成密钥[root@datanode2 ~]# cd /home/datanode2/ [root@datanode2 datanode2]# pwd /home/datanode2 [root@datanode2 datanode2]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: a9:da:e2:80:3a:d0:a9:1b:65:c0:c7:e6:10:61:a7:65 root@datanode2 The key's randomart image is: +--[ RSA 2048]----+ | +.E | |o B | |.+ + | | .= . | | .oo S | |.+o . | |+.. . | |+. ..o | |oo .o.. | +-----------------+ [root@datanode2 datanode2]# cd /root/ [root@datanode2 ~]# ls anaconda-ks.cfg install.log install.log.syslog [root@datanode2 ~]# ls -a . .. anaconda-ks.cfg .bash_history .bash_logout .bash_profile .bashrc .cshrc install.log install.log.syslog .oracle_jre_usage .ssh .tcshrc .xauth9yJBa2 [root@datanode2 ~]# cd .ssh [root@datanode2 .ssh]# ls id_rsa id_rsa.pub known_hosts [root@datanode2 .ssh]# ls -l total 12 -rw-------. 1 root root 1671 Nov 25 23:28 id_rsa -rw-r--r--. 1 root root 396 Nov 25 23:28 id_rsa.pub -rw-r--r--. 1 root root 813 Nov 25 22:50 known_hosts
转到虚机192.168.115.132 slave/datanode2节点上以root权限重复上述步骤生成密钥;[datanode2@datanode2 ~]$ pwd /home/datanode2 [datanode2@datanode2 ~]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/datanode2/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/datanode2/.ssh/id_rsa. Your public key has been saved in /home/datanode2/.ssh/id_rsa.pub. The key fingerprint is: b3:10:5c:18:5c:40:4c:4a:d0:00:26:0b:ec:b3:34:ed datanode2@datanode2 The key's randomart image is: +--[ RSA 2048]----+ |=oo+.===o | |+o ..o+. | |o . . o | | = . . | |. = . S | | . E . o | | . | | | | | +-----------------+ [datanode2@datanode2 ~]$ cd /root/ bash: cd: /root/: Permission denied [datanode2@datanode2 ~]$ ls -a . .bash_profile .dbus Downloads .gconfd .gstreamer-0.10 .icons .nautilus .pulse .ssh Videos .. .bashrc Desktop .esd_auth .gnome2 .gtk-bookmarks .local .oracle_jre_usage .pulse-cookie Templates .viminfo .bash_history .cache .dmrc .fontconfig .gnote .gvfs .mozilla Pictures .recently-used.xbel .themes .xsession-errors .bash_logout .config Documents .gconf .gnupg .ICEauthority Music Public .spice-vdagent .thumbnails .xsession-errors.old [datanode2@datanode2 ~]$ cd .ssh [datanode2@datanode2 .ssh]$ ls id_rsa id_rsa.pub [datanode2@datanode2 .ssh]$ ls -l total 8 -rw-------. 1 datanode2 datanode2 1675 Nov 25 23:35 id_rsa -rw-r--r--. 1 datanode2 datanode2 401 Nov 25 23:35 id_rsa.pub
将节点1(192.168.115.130/namenode)的id_rsa.pub文件分别拷贝到节点2和节点3的/root/.ssh目录下,并重命名为authorized_keys;[root@namenode .ssh]# scp ./id_rsa.pub root@datanode1:/root/.ssh/authorized_keys root@datanode1's password: id_rsa.pub 100% 395 0.4KB/s 00:00 [root@namenode .ssh]# scp ./id_rsa.pub root@datanode2:/root/.ssh/authorized_keys root@datanode2's password: id_rsa.pub 100% 395 0.4KB/s 00:00 [root@namenode .ssh]# scp ./id_rsa.pub root@datanode2:/root/.ssh/authorized_keys id_rsa.pub 100% 395 0.4KB/s 00:00
分别在节点2 和节点3 的对于目录下查看拷贝文件的属性;
验证是否生效,实现免密码登录;
以上仅仅只是实现了从namenode节点SSH免密码登录到datanode1节点和datanode2节点,因为datanode1节点和datanode2节点只保留了namenode节点的公钥,且上述步骤并不能使namenode节点免密码SSH登录到自身节点,见下图:
如果我们想要在3个节点间实现任意节点的免密码SSH登录并且可以免密码SSH登录到自身节点,首先我们需要造在namenode节点的/root/.ssh目录下创建authorized_keys文件,将其他节点的公钥拷贝到的authorized_keys文件中,从而实现任意节点间的免密码SSH登录。
以namenode节点为例实现自身的SSH免密码登录;[root@namenode ~]# scp /root/.ssh/id_rsa.pub root@namenode:/root/.ssh/authorized_keys root@namenode's password: id_rsa.pub 100% 395 0.4KB/s 00:00 [root@namenode ~]# cd /root/ [root@namenode ~]# ls anaconda-ks.cfg Desktop Documents Downloads install.log install.log.syslog Music Pictures Public Templates Videos [root@namenode ~]# cd .ssh [root@namenode .ssh]# ls authorized_keys id_rsa id_rsa.pub known_hosts [root@namenode .ssh]# ls -l total 16 -rw-r--r--. 1 root root 395 Nov 26 00:24 authorized_keys -rw-------. 1 root root 1675 Nov 25 23:03 id_rsa -rw-r--r--. 1 root root 395 Nov 25 23:03 id_rsa.pub -rw-r--r--. 1 root root 2392 Nov 25 11:10 known_hosts [root@namenode .ssh]# ssh namenode Last login: Sat Nov 26 00:22:57 2016 from datanode2
使用vi authorized_keys命令编辑每个节点的authorized_keys文件,将缺少的节点公钥拷贝到该文件里,保存并退出;
验证任意节点的免密码自登陆及任意节点间的免密码SSH登录;[root@namenode .ssh]# ssh namenode Last login: Sat Nov 26 00:24:59 2016 from namenode [root@namenode ~]# ssh datanode1 Last login: Sat Nov 26 00:34:16 2016 from namenode [root@datanode1 ~]# ssh datanode2 Last login: Fri Nov 25 23:58:37 2016 from namenode [root@datanode2 ~]# ssh datanode1 Last login: Sat Nov 26 00:48:14 2016 from namenode [root@datanode1 ~]# ssh namenode Last login: Sat Nov 26 00:48:02 2016 from namenode
通过以上步骤,即可实现了本集群中任意一台机器免密码SSH登录到另外一台机器;接下来,小编带你进入Hadoop的正式安装......五、Hadoop1.2.1的安装
hadoop的安装一般是先在namenode节点上修改相关文件,然后将配置好的namenode节点上的hadoop文件夹向各节点复制;小编先是配置虚机192.168.115.130/namenode节点上的hadoop,然后向虚机92.168.115.131/datanode1节点和192.168.115.132/datanode2节点复制修改好的hadoop文件。
确保iptables,selinux等防火墙或访问控制机制已关闭[root@namenode Desktop]# service iptables stop iptables: Setting chains to policy ACCEPT: filter [ OK ] iptables: Flushing firewall rules: [ OK ] iptables: Unloading modules: [ OK ]
下载并解压到文件夹hadoop-1.2.1
cd /usr/local/hadoop-1.2.1/conf/ 转到hadoop配置目录下 进行文件的配置[tpf@namenode hadoop-1.2.1]$ cd conf [tpf@namenode conf]$ ls capacity-scheduler.xml fair-scheduler.xml hadoop-policy.xml mapred-queue-acls.xml slaves taskcontroller.cfg configuration.xsl hadoop-env.sh hdfs-site.xml mapred-site.xml ssl-client.xml.example task-log4j.properties core-site.xml hadoop-metrics2.properties log4j.properties masters ssl-server.xml.example
修改hadoop-env.sh# The java implementation to use. Required. export JAVA_HOME=/usr/local/jdk1.8.0_111
修改core-site.xml 写入如下信息,要注意,自己要在/usr/local/hadoop-1.2.1/ 目录下手动建立tmp目录,如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoop-dfs。而这个目录在每次重启后都会被删掉,必须重新执行format才行,否则会出错,hdfs后面的ip号就是名称节点的ip,即namenode的ip,端口号默认9000,不用改动 ;<configuration> <property> <name>fs.default.name</name> <value>hdfs://namenode:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop-1.2.1/tmp</value> </property> </configuration>
修改hdfs-site.xml
设置数据备份数目,这里我们有有一个namenode,两个datanode,所以备份数目设置为2<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> </configuration>
修改mapred-site.xml 设置map-reduce的作业跟踪器(jobtracker)所在节点,这里我们同样将其放置在namenode(192.168.115.130)节点上,端口号9001<configuration> <property> <name>mapred.job.tracker</name> <value>http://namenode:9001</value> </property> </configuration>
修改master 指定namenode所在节点;namenode
修改slave 指定集群的datanode节点 ;datanode1 datanode2
向各节点复制hadoop[root@namenode local]# scp -r /usr/local/hadoop-1.2.1/ datanode1:/usr/local/ [root@namenode local]# scp -r /usr/local/hadoop-1.2.1/ datanode2:/usr/local/
执行文件系统格式化:bin/hadoop namenode -format,如果没有任何warning,error,fatal等并且最后出现,format successfully字样,则格式化成;[root@namenode hadoop-1.2.1]# bin/hadoop namenode -format 16/11/26 04:30:08 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = namenode/192.168.115.130 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.2.1 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1503152; compiled by 'mattf' on Mon Jul 22 15:23:09 PDT 2013 STARTUP_MSG: java = 1.8.0_111 ************************************************************/ 16/11/26 04:30:09 INFO util.GSet: Computing capacity for map BlocksMap 16/11/26 04:30:09 INFO util.GSet: VM type = 64-bit 16/11/26 04:30:09 INFO util.GSet: 2.0% max memory = 1013645312 16/11/26 04:30:09 INFO util.GSet: capacity = 2^21 = 2097152 entries 16/11/26 04:30:09 INFO util.GSet: recommended=2097152, actual=2097152 16/11/26 04:30:09 INFO namenode.FSNamesystem: fsOwner=root 16/11/26 04:30:09 INFO namenode.FSNamesystem: supergroup=supergroup 16/11/26 04:30:09 INFO namenode.FSNamesystem: isPermissionEnabled=true 16/11/26 04:30:10 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100 16/11/26 04:30:10 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s) 16/11/26 04:30:10 INFO namenode.FSEditLog: dfs.namenode.edits.toleration.length = 0 16/11/26 04:30:10 INFO namenode.NameNode: Caching file names occuring more than 10 times 16/11/26 04:30:11 INFO common.Storage: Image file /usr/local/hadoop-1.2.1/tmp/dfs/name/current/fsimage of size 110 bytes saved in 0 seconds. 16/11/26 04:30:11 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/usr/local/hadoop-1.2.1/tmp/dfs/name/current/edits 16/11/26 04:30:11 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/usr/local/hadoop-1.2.1/tmp/dfs/name/current/edits 16/11/26 04:30:11 INFO common.Storage: Storage directory /usr/local/hadoop-1.2.1/tmp/dfs/name has been successfully formatted. 16/11/26 04:30:11 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at namenode/192.168.115.130 ************************************************************/
启动hadoop[root@namenode hadoop-1.2.1]# bin/start-all.sh starting namenode, logging to /usr/local/hadoop-1.2.1/libexec/../logs/hadoop-tpf-namenode-namenode.out datanode2: starting datanode, logging to /usr/local/hadoop-1.2.1/libexec/../logs/hadoop-root-datanode-datanode2.out datanode1: starting datanode, logging to /usr/local/hadoop-1.2.1/libexec/../logs/hadoop-root-datanode-datanode1.out namenode: starting secondarynamenode, logging to /usr/local/hadoop-1.2.1/libexec/../logs/hadoop-root-secondarynamenode-namenode.out starting jobtracker, logging to /usr/local/hadoop-1.2.1/libexec/../logs/hadoop-tpf-jobtracker-namenode.out datanode1: starting tasktracker, logging to /usr/local/hadoop-1.2.1/libexec/../logs/hadoop-root-tasktracker-datanode1.out datanode2: starting tasktracker, logging to /usr/local/hadoop-1.2.1/libexec/../logs/hadoop-root-tasktracker-datanode2.out
namenode节点的启动日志:[root@namenode hadoop-1.2.1]# cd logs/ [root@namenode logs]# ls hadoop-root-secondarynamenode-namenode.log hadoop-tpf-jobtracker-namenode.log hadoop-tpf-namenode-namenode.log history hadoop-root-secondarynamenode-namenode.out hadoop-tpf-jobtracker-namenode.out hadoop-tpf-namenode-namenode.out
datanode1节点的启动日志:[root@datanode1 logs]# ls hadoop-root-datanode-datanode1.log hadoop-root-datanode-datanode1.out hadoop-root-tasktracker-datanode1.log hadoop-root-tasktracker-datanode1.out
datanode2节点的启动日志:[root@datanode2 hadoop-1.2.1]# cd logs/ [root@datanode2 logs]# ls hadoop-root-datanode-datanode2.log hadoop-root-datanode-datanode2.out hadoop-root-tasktracker-datanode2.log hadoop-root-tasktracker-datanode2.out
用jps检验各后台进程是否成功启动[root@namenode hadoop-1.2.1]# jps 55553 SecondaryNameNode 55411 NameNode 55637 JobTracker 55737 Jps[root@datanode1 hadoop-1.2.1]# jps 39219 Jps 39155 TaskTracker 39077 DataNode[root@datanode2 hadoop-1.2.1]# jps 6641 DataNode 6814 Jps 6719 TaskTracker
第一次启动的时候,datanode1节点总是启动不了;最后找下来发现是由于datanode1的防火墙没关闭,阻止了相应的端口号。[root@namenode hadoop-1.2.1]# bin/stop-all.sh stopping jobtracker datanode2: stopping tasktracker datanode1: no tasktracker to stop stopping namenode datanode2: stopping datanode datanode1: no datanode to stop namenode: stopping secondarynamenode [root@datanode1 logs]# jps 38824 Jps六、集群测试
[root@namenode hadoop-1.2.1]# bin/hadoop fs -put /usr/local/input/ in [root@namenode hadoop-1.2.1]# bin/hadoop fs -cat /usr/local/input/ in cat: File does not exist: /usr/local/input cat: File does not exist: /user/root/in [root@namenode hadoop-1.2.1]# bin/hadoop fs -cat /usr/local/input/ ./in/* cat: File does not exist: /usr/local/input hello world hello hadoop [root@namenode hadoop-1.2.1]# bin/hadoop fs -cat /usr/local/input/ ./in cat: File does not exist: /usr/local/input cat: File does not exist: /user/root/in [root@namenode hadoop-1.2.1]# bin/hadoop fs -ls ./in Found 2 items -rw-r--r-- 2 root supergroup 12 2016-11-26 07:18 /user/root/in/text1.txt -rw-r--r-- 2 root supergroup 13 2016-11-26 07:18 /user/root/in/text2.txt [root@namenode hadoop-1.2.1]# bin/hadoop fs -cat ./in/text1.txt hello world [root@namenode hadoop-1.2.1]# bin/hadoop fs -cat ./in/text2.txt hello hadoop [root@namenode hadoop-1.2.1]# ls bin c++ conf docs hadoop-client-1.2.1.jar hadoop-examples-1.2.1.jar hadoop-test-1.2.1.jar ivy lib LICENSE.txt NOTICE.txt sbin src webapps build.xml CHANGES.txt contrib hadoop-ant-1.2.1.jar hadoop-core-1.2.1.jar hadoop-minicluster-1.2.1.jar hadoop-tools-1.2.1.jar ivy.xml libexec logs README.txt share tmp [root@namenode hadoop-1.2.1]# bin/hadoop jar hadoop-examples-1.2.1.jar wordcount in out 16/11/26 07:24:35 INFO input.FileInputFormat: Total input paths to process : 2 16/11/26 07:24:35 INFO util.NativeCodeLoader: Loaded the native-hadoop library 16/11/26 07:24:35 WARN snappy.LoadSnappy: Snappy native library not loaded 16/11/26 07:24:36 INFO mapred.JobClient: Running job: job_201611260717_0001 16/11/26 07:24:37 INFO mapred.JobClient: map 0% reduce 0% 16/11/26 07:24:49 INFO mapred.JobClient: map 50% reduce 0% 16/11/26 07:24:52 INFO mapred.JobClient: map 100% reduce 0% 16/11/26 07:25:03 INFO mapred.JobClient: map 100% reduce 100% 16/11/26 07:25:06 INFO mapred.JobClient: Job complete: job_201611260717_0001 16/11/26 07:25:06 INFO mapred.JobClient: Counters: 29 16/11/26 07:25:06 INFO mapred.JobClient: Map-Reduce Framework 16/11/26 07:25:06 INFO mapred.JobClient: Spilled Records=8 16/11/26 07:25:06 INFO mapred.JobClient: Map output materialized bytes=61 16/11/26 07:25:06 INFO mapred.JobClient: Reduce input records=4 16/11/26 07:25:06 INFO mapred.JobClient: Virtual memory (bytes) snapshot=5800710144 16/11/26 07:25:06 INFO mapred.JobClient: Map input records=2 16/11/26 07:25:06 INFO mapred.JobClient: SPLIT_RAW_BYTES=216 16/11/26 07:25:06 INFO mapred.JobClient: Map output bytes=41 16/11/26 07:25:06 INFO mapred.JobClient: Reduce shuffle bytes=61 16/11/26 07:25:06 INFO mapred.JobClient: Physical memory (bytes) snapshot=418377728 16/11/26 07:25:06 INFO mapred.JobClient: Reduce input groups=3 16/11/26 07:25:06 INFO mapred.JobClient: Combine output records=4 16/11/26 07:25:06 INFO mapred.JobClient: Reduce output records=3 16/11/26 07:25:06 INFO mapred.JobClient: Map output records=4 16/11/26 07:25:06 INFO mapred.JobClient: Combine input records=4 16/11/26 07:25:06 INFO mapred.JobClient: CPU time spent (ms)=3400 16/11/26 07:25:06 INFO mapred.JobClient: Total committed heap usage (bytes)=337780736 16/11/26 07:25:06 INFO mapred.JobClient: File Input Format Counters 16/11/26 07:25:06 INFO mapred.JobClient: Bytes Read=25 16/11/26 07:25:06 INFO mapred.JobClient: FileSystemCounters 16/11/26 07:25:06 INFO mapred.JobClient: HDFS_BYTES_READ=241 16/11/26 07:25:06 INFO mapred.JobClient: FILE_BYTES_WRITTEN=173342 16/11/26 07:25:06 INFO mapred.JobClient: FILE_BYTES_READ=55 16/11/26 07:25:06 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=25 16/11/26 07:25:06 INFO mapred.JobClient: Job Counters 16/11/26 07:25:06 INFO mapred.JobClient: Launched map tasks=2 16/11/26 07:25:06 INFO mapred.JobClient: Launched reduce tasks=1 16/11/26 07:25:06 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=12312 16/11/26 07:25:06 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 16/11/26 07:25:06 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=20972 16/11/26 07:25:06 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 16/11/26 07:25:06 INFO mapred.JobClient: Data-local map tasks=2 16/11/26 07:25:06 INFO mapred.JobClient: File Output Format Counters 16/11/26 07:25:06 INFO mapred.JobClient: Bytes Written=25 [root@namenode hadoop-1.2.1]# bin/hadoop fs -ls Found 2 items drwxr-xr-x - root supergroup 0 2016-11-26 07:18 /user/root/in drwxr-xr-x - root supergroup 0 2016-11-26 07:25 /user/root/out [root@namenode hadoop-1.2.1]# bin/hadoop fs -ls ./out Found 3 items -rw-r--r-- 2 root supergroup 0 2016-11-26 07:25 /user/root/out/_SUCCESS drwxr-xr-x - root supergroup 0 2016-11-26 07:24 /user/root/out/_logs -rw-r--r-- 2 root supergroup 25 2016-11-26 07:24 /user/root/out/part-r-00000 [root@namenode hadoop-1.2.1]# bin/hadoop fs -cat ./out/part-r-00000 hadoop 1 hello 2 world 1七、注意事项
确保关闭防火墙#关闭: service iptables stop #查看: service iptables status #重启不启动: chkconfig iptables off #重启启动: chkconfig iptables on[INFO] Reactor Summary: [INFO] [INFO] Apache Hadoop Main ................................. SUCCESS [ 01:05 h] [INFO] Apache Hadoop Project POM .......................... SUCCESS [05:58 min] [INFO] Apache Hadoop Annotations .......................... SUCCESS [03:01 min] [INFO] Apache Hadoop Assemblies ........................... SUCCESS [ 0.598 s] [INFO] Apache Hadoop Project Dist POM ..................... SUCCESS [02:07 min] [INFO] Apache Hadoop Maven Plugins ........................ FAILURE [02:08 min] [INFO] Apache Hadoop MiniKDC .............................. SKIPPED [INFO] Apache Hadoop Auth ................................. SKIPPED [INFO] Apache Hadoop Auth Examples ........................ SKIPPED [INFO] Apache Hadoop Common ............................... SKIPPED [INFO] Apache Hadoop NFS .................................. SKIPPED [INFO] Apache Hadoop Common Project ....................... SKIPPED [INFO] Apache Hadoop HDFS ................................. SKIPPED [INFO] Apache Hadoop HttpFS ............................... SKIPPED [INFO] Apache Hadoop HDFS BookKeeper Journal .............. SKIPPED [INFO] Apache Hadoop HDFS-NFS ............................. SKIPPED [INFO] Apache Hadoop HDFS Project ......................... SKIPPED [INFO] hadoop-yarn ........................................ SKIPPED [INFO] hadoop-yarn-api .................................... SKIPPED [INFO] hadoop-yarn-common ................................. SKIPPED [INFO] hadoop-yarn-server ................................. SKIPPED [INFO] hadoop-yarn-server-common .......................... SKIPPED [INFO] hadoop-yarn-server-nodemanager ..................... SKIPPED [INFO] hadoop-yarn-server-web-proxy ....................... SKIPPED [INFO] hadoop-yarn-server-resourcemanager ................. SKIPPED [INFO] hadoop-yarn-server-tests ........................... SKIPPED [INFO] hadoop-yarn-client ................................. SKIPPED [INFO] hadoop-yarn-applications ........................... SKIPPED [INFO] hadoop-yarn-applications-distributedshell .......... SKIPPED [INFO] hadoop-yarn-applications-unmanaged-am-launcher ..... SKIPPED [INFO] hadoop-yarn-site ................................... SKIPPED [INFO] hadoop-yarn-project ................................ SKIPPED [INFO] hadoop-mapreduce-client ............................ SKIPPED [INFO] hadoop-mapreduce-client-core ....................... SKIPPED [INFO] hadoop-mapreduce-client-common ..................... SKIPPED [INFO] hadoop-mapreduce-client-shuffle .................... SKIPPED [INFO] hadoop-mapreduce-client-app ........................ SKIPPED [INFO] hadoop-mapreduce-client-hs ......................... SKIPPED [INFO] hadoop-mapreduce-client-jobclient .................. SKIPPED [INFO] hadoop-mapreduce-client-hs-plugins ................. SKIPPED [INFO] Apache Hadoop MapReduce Examples ................... SKIPPED [INFO] hadoop-mapreduce ................................... SKIPPED [INFO] Apache Hadoop MapReduce Streaming .................. SKIPPED [INFO] Apache Hadoop Distributed Copy ..................... SKIPPED [INFO] Apache Hadoop Archives ............................. SKIPPED [INFO] Apache Hadoop Rumen ................................ SKIPPED [INFO] Apache Hadoop Gridmix .............................. SKIPPED [INFO] Apache Hadoop Data Join ............................ SKIPPED [INFO] Apache Hadoop Extras ............................... SKIPPED [INFO] Apache Hadoop Pipes ................................ SKIPPED [INFO] Apache Hadoop OpenStack support .................... SKIPPED [INFO] Apache Hadoop Client ............................... SKIPPED [INFO] Apache Hadoop Mini-Cluster ......................... SKIPPED [INFO] Apache Hadoop Scheduler Load Simulator ............. SKIPPED [INFO] Apache Hadoop Tools Dist ........................... SKIPPED [INFO] Apache Hadoop Tools ................................ SKIPPED [INFO] Apache Hadoop Distribution ......................... SKIPPED [INFO] ------------------------------------------------------------------------ [INFO] BUILD FAILURE [INFO] ------------------------------------------------------------------------ [INFO] Total time: 01:51 h [INFO] Finished at: 2016-11-27T06:31:52-08:00 [INFO] Final Memory: 44M/106M [INFO] ------------------------------------------------------------------------ [ERROR] Failed to execute goal org.apache.maven.plugins:maven-javadoc-plugin:2.8.1:jar (module-javadocs) on project hadoop-maven-plugins: MavenReportException: Error while creating archive: [ERROR] Exit code: 1 - /home/grid/release-2.3.0/hadoop-maven-plugins/src/main/java/org/apache/hadoop/maven/plugin/util/Exec.java:47: error: unknown tag: String [ERROR] * @param command List<String> containing command and all arguments [ERROR] ^ [ERROR] /home/grid/release-2.3.0/hadoop-maven-plugins/src/main/java/org/apache/hadoop/maven/plugin/util/Exec.java:48: error: unknown tag: String [ERROR] * @param output List<String> in/out parameter to receive command output [ERROR] ^ [ERROR] /home/grid/release-2.3.0/hadoop-maven-plugins/src/main/java/org/apache/hadoop/maven/plugin/util/FileSetUtils.java:52: error: unknown tag: File [ERROR] * @return List<File> containing every element of the FileSet as a File [ERROR] ^ [ERROR] [ERROR] Command line was: /usr/local/jdk1.8.0_111/jre/../bin/javadoc @options @packages [ERROR] [ERROR] Refer to the generated Javadoc files in '/home/grid/release-2.3.0/hadoop-maven-plugins/target' dir. [ERROR] -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException [ERROR] [ERROR] After correcting the problems, you can resume the build with the command
官网地址:http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-common/SingleCluster.html
http://f.dataguru.cn/thread-253905-1-1.html






相关文章推荐
- 基于hadoop集群的Hive1.2.1、Hbase1.2.2、Zookeeper3.4.8完全分布式安装
- 【Hadoop】8、基于虚拟机的Hadoop1.2.1完全分布式集群安装
- Hadoop1.2.1 完全分布式集群搭建实操笔记
- Linux集群部署系列(五):Hadoop 2.x完全分布式集群部署
- 如何在Centos6.5下部署Hadoop2.2的完全分布式集群(三)
- hadoop-2.7.1+zookeeper-3.4.8+hbase-1.2.1+apache-hive-2.0.0完全分布式集群
- Hadoop集群完全分布式模式环境部署
- 基于虚拟linux+docker搭建hadoop完全分布式集群
- 超详细从零记录Hadoop2.7.3完全分布式集群部署过程
- hadoop-2.7.1+zookeeper-3.4.8+hbase-1.2.1+apache-hive-2.0.0完全分布式集群
- centos6.5之Hadoop1.2.1完全分布式部署安装
- Hadoop集群完全分布式模式环境部署
- hadoop2.5.1集群部署(完全分布式)
- CentOS6.4之图解Hadoop1.2.1完全分布式部署
- 基于hadoop2.7集群的Spark2.0,Sqoop1.4.6,Mahout0.12.2完全分布式安装
- Hadoop1.2.1+Zookeeper3.4.5+HBase0.94.18完全分布式集群配置过程中遇到的问题
- Hadoop集群完全分布式模式环境部署和管理的5大工具
- 基于HA的hadoop2.7.1完全分布式集群搭建
- hadoop-2.7.3完全分布式集群部署
- 超详细从零记录Hadoop2.7.3完全分布式集群部署过程