scrapy_redis种子优化
2016-11-24 16:40
330 查看
前言:
继《scrapy_redis去重优化(已有7亿条数据),附Demo福利》优化完去重之后,Redis的内存消耗降了许多,然而还不满足。这次对scrapy_redis的种子队列作了一些优化(严格来说并不能用上“优化”这词,其实就是结合自己的项目作了一些改进,对本项目能称作优化,对scrapy_redis未必是个优化)。scrapy_redis默认是将Request对象序列化后(变成一条字符串)存入Redis作为种子,需要的时候再取出来进行反序列化,还原成一个Request对象。
现在的问题是:序列化后的字符串太长,短则几百个字符,长则上千。我的爬虫平时至少也要维护包含几千万种子的种子队列,占用内存在20G~50G之间(Centos)。想要缩减种子的长度,这样不仅Redis的内存消耗会降低,各个slaver从Redis拿种子的速度也会有所提高,从而整个分布式爬虫系统的抓取速度也会有所提高(效果视具体情况而定,要看爬虫主要阻塞在哪里)。
记录:
1、首先看调度器,即scrapy_redis模块下的scheduler.py文件,可以看到enqueue_request()方法和
next_request()方法就是种子入队列和出队列的地方,
self.queue指的是我们在setting.py里面设定的
SCHEDULER_QUEUE_CLASS值,常用的是
'scrapy_redis.queue.SpiderPriorityQueue'。
2、进入scrapy模块下的queue.py文件,SpiderPriorityQueue类的代码如下:
class SpiderPriorityQueue(Base):
"""Per-spider priority queue abstraction using redis' sorted set"""
def __len__(self):
"""Return the length of the queue"""
return self.server.zcard(self.key)
def push(self, request):
"""Push a request"""
data = self._encode_request(request)
pairs = {data: -request.priority}
self.server.zadd(self.key, **pairs)
def pop(self, timeout=0):
"""
Pop a request
timeout not support in this queue class
"""
pipe = self.server.pipeline()
pipe.multi()
pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0)
results, count = pipe.execute()
if results:
return self._decode_request(results[0])可以看到,上面用到了Redis的zset数据结构(它可以给种子加优先级),在进Redis之前用
_encode_request()方法将Request对象转成字符串,
_encode_request()和
_decode_request是Base类下面的两个方法:
def _encode_request(self, request): """Encode a request object""" return pickle.dumps(request_to_dict(request, self.spider), protocol=-1) def _decode_request(self, encoded_request): """Decode an request previously encoded""" return request_from_dict(pickle.loads(encoded_request), self.spider)
可以看到,这里先将Request对象转成一个字典,再将字典序列化成一个字符串。Request对象怎么转成一个字典呢?看下面的代码,一目了然。
def request_to_dict(request, spider=None):
"""Convert Request object to a dict.
If a spider is given, it will try to find out the name of the spider method
used in the callback and store that as the callback.
"""
cb = request.callback
if callable(cb):
cb = _find_method(spider, cb)
eb = request.errback
if callable(eb):
eb = _find_method(spider, eb)
d = {
'url': to_unicode(request.url), # urls should be safe (safe_string_url)
'callback': cb,
'errback': eb,
'method': request.method,
'headers': dict(request.headers),
'body': request.body,
'cookies': request.cookies,
'meta': request.meta,
'_encoding': request._encoding,
'priority': request.priority,
'dont_filter': request.dont_filter,
}
return d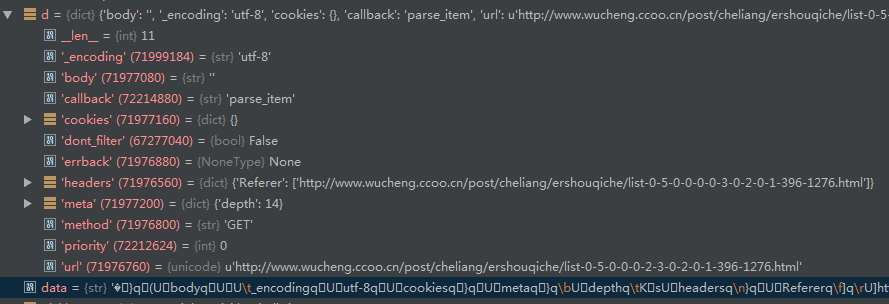
注:
d为Request对象转过来的字典,
data为字典序列化后的字符串。
3、了解完scrapy_redis默认的种子处理方式,现在针对自己的项目作一些调整。我的是一个全网爬虫,每个种子需要记录的信息主要有两个:url和callback函数名。此时我们选择不用序列化,直接用简单粗暴的方式,将callback函数名和url拼接成一条字符串作为一条种子,这样种子的长度至少会减少一半。另外我们的种子并不需要设优先级,所以也不用zset了,改用Redis的list。以下是我新建的SpiderSimpleQueue类,加在queue.py中。如果在settings.py里将
SCHEDULER_QUEUE_CLASS值设置成
'scrapy_redis.queue.SpiderSimpleQueue'即可使用我这种野蛮粗暴的种子。
from scrapy.utils.reqser import request_to_dict, request_from_dict, _find_method
class SpiderSimpleQueue(Base):
""" url + callback """
def __len__(self):
"""Return the length of the queue"""
return self.server.llen(self.key)
def push(self, request):
"""Push a request"""
url = request.url
cb = request.callback
if callable(cb):
cb = _find_method(self.spider, cb)
data = '%s--%s' % (cb, url)
self.server.lpush(self.key, data)
def pop(self, timeout=0):
"""Pop a request"""
if timeout > 0:
data = self.server.brpop(self.key, timeout=timeout)
if isinstance(data, tuple):
data = data[1]
else:
data = self.server.rpop(self.key)
if data:
cb, url = data.split('--', 1)
try:
cb = getattr(self.spider, str(cb))
return Request(url=url, callback=cb)
except AttributeError:
raise ValueError("Method %r not found in: %s" % (cb, self.spider))
__all__ = ['SpiderQueue', 'SpiderPriorityQueue', 'SpiderSimpleQueue', 'SpiderStack']4、另外需要提醒的是,如果scrapy中加了中间件
process_request(),当yield一个Request对象的时候,scrapy_redis会直接将它丢进Redis种子队列,未执行
process_requset();需要一个Request对象的时候,scrapy_redis会从Redis队列中取出种子,此时才会处理
process_request()方法,接着去抓取网页。
所以并不需要担心
process_request()里面添加的Cookie在Redis中放太久会失效,因为进Redis的时候它压根都还没执行
process_request()。事实上Request对象序列化的时候带上的字段很多都是没用的默认字段,很多爬虫都可以用 “callback+url” 的方式来优化种子。
5、最后,在Scrapy_Redis_Bloomfilter(Github传送门)这个demo中我已作了修改,大家可以试试效果。
结语:
经过以上优化,Redis的内存消耗从42G降到了27G!里面包含7亿多条种子的去重数据 和4000W+条种子。并且六台子爬虫的抓取速度都提升了一些。两次优化,内存消耗从160G+降到现在的27G,效果也是让人满意!
转载请注明出处,谢谢!(原文链接:http://blog.csdn.net/bone_ace/article/details/53306629)

相关文章推荐
- scrapy_redis去重优化(已有7亿条数据),附Demo福利
- 使用BloomFilter优化scrapy-redis去重
- 【转载】Redis内存使用优化与存储
- 使用scrapy-redis构建简单的分布式爬虫
- scrapy-redis实现爬虫分布式爬取分析与实现
- 一次线上redis实例cpu占用率过高问题优化
- Redis笔记八之内存设置及优化
- [scrapy]scrapy-redis快速上手/scrapy爬虫分布式改造
- TCMalloc优化MySQL、Nginx、Redis内存管理
- 第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
- java(优化18) 15天玩转redis之第十篇
- scrapy-redis 和 scrapy 有什么区别?
- 使用hashmap优化压缩Redis内存使用
- 阿里REDIS优化
- Scrapy-redis改造scrapy实现分布式多进程爬取
- Redis优化之CPU充分利用
- java架构师、集群、高可扩展、高性能、高并发、性能优化、Spring boot、Dubbo、Redis、ActiveMQ、Nginx、Mycat、Netty、Jvm大型分布式项目实战学习架构师之路
- Django缓存优化之redis
- Scrapy Redis源码 spider分析