在Python里安装Jieba中文分词组件
2016-11-23 21:05
639 查看
Jieba是一个中文分词组件,可用于中文句子/词性分割、词性标注、未登录词识别,支持用户词典等功能。该组件的分词精度达到了97%以上。下载介绍在Python里安装Jieba。
1)下载Jieba
官网地址:http://pypi.python.org/pypi/jieba/
个人地址:http://download.csdn.net/detail/sanqima/9470715
2)将其解压到D:\TDDownload,如图(1)所示:
图(1)将Jieba-0.35.zip解压
3)点击电脑桌面的左下角的【开始】—》运行 —》输入: cmd —》切换到Jieba所在的目录,比如,D:\TDDownload\Jieba,依次使用如下命令:
如图(2)所示:
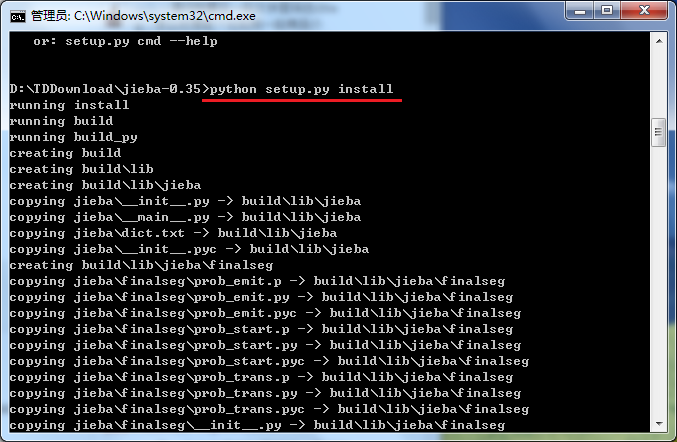
图(2) 切换到Jieba目录,使用命令:python setup.py install 进行安装
3)在PyCharm里写一个中文分词的小程序: fenCi.py
## fenCi.py
效果如下:
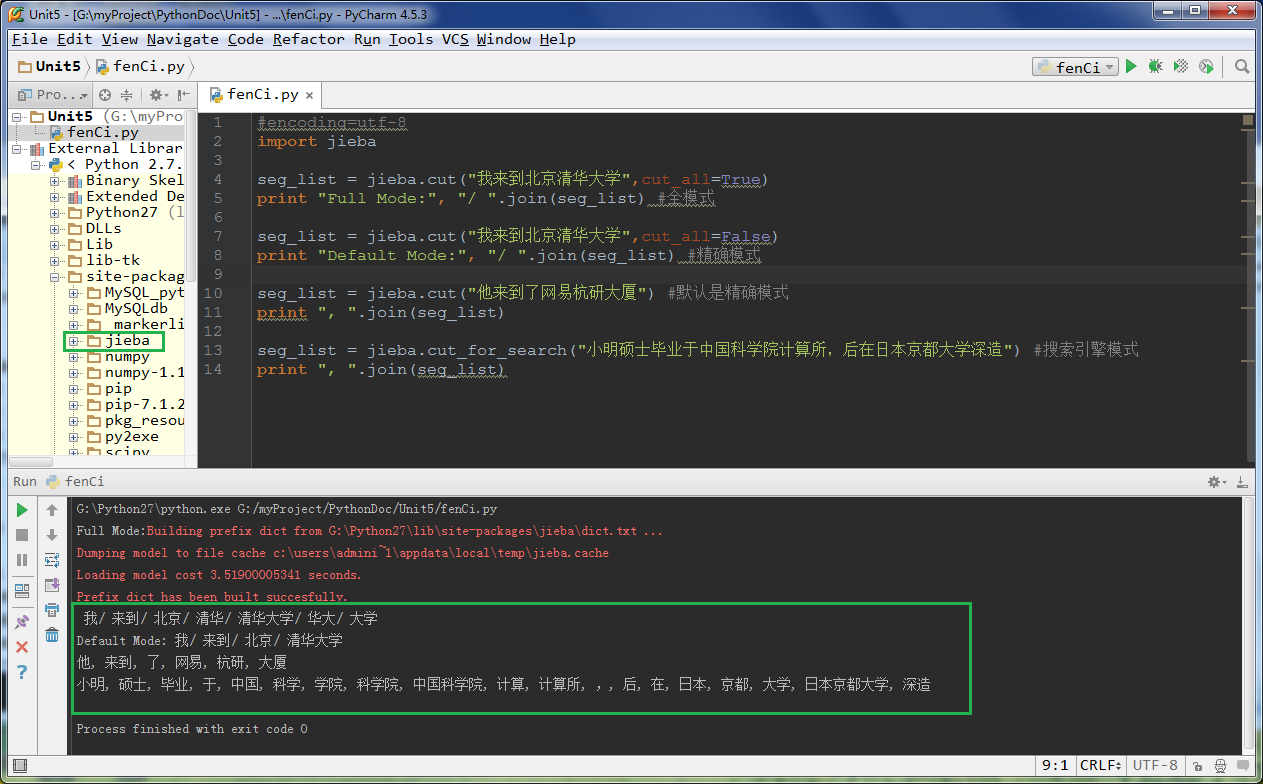
图(3) Jieba进行中文分词的效果
原文出处:http://blog.csdn.net/sanqima/article/details/50965439
1)下载Jieba
官网地址:http://pypi.python.org/pypi/jieba/
个人地址:http://download.csdn.net/detail/sanqima/9470715
2)将其解压到D:\TDDownload,如图(1)所示:
图(1)将Jieba-0.35.zip解压
3)点击电脑桌面的左下角的【开始】—》运行 —》输入: cmd —》切换到Jieba所在的目录,比如,D:\TDDownload\Jieba,依次使用如下命令:
C:\Users\Administrator>D: D:\>cd D:\TDDownload\jieba-0.35 D:\TDDownload\jieba-0.35>python setup.py install
如图(2)所示:
图(2) 切换到Jieba目录,使用命令:python setup.py install 进行安装
3)在PyCharm里写一个中文分词的小程序: fenCi.py
## fenCi.py
#encoding=utf-8
import jieba
seg_list = jieba.cut("我来到北京清华大学",cut_all=True)
print "Full Mode:", "/ ".join(seg_list) #全模式
seg_list = jieba.cut("我来到北京清华大学",cut_all=False)
print "Default Mode:", "/ ".join(seg_list) #精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") #默认是精确模式
print ", ".join(seg_list)
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") #搜索引擎模式
print ", ".join(seg_list)效果如下:
图(3) Jieba进行中文分词的效果
原文出处:http://blog.csdn.net/sanqima/article/details/50965439

相关文章推荐
- 在Python里安装Jieba中文分词组件
- 在Python里安装Jieba中文分词组件
- 在Python里安装Jieba中文分词组件
- 在Python里安装Jieba中文分词组件
- 基于Python3.6编写的jieba分词组件+Scikit-Learn库+朴素贝叶斯算法小型中文自动分类程序
- Python中文分词组件 jieba
- 在PyCharm(Python集成开发环境)中安装jieba中文分词工具包
- Python中文分词组件jieba
- Py之jieba:Python包之jieba包——中文分词最好的组件——Jason niu
- Python中文分词组件 jieba
- Python中文分词组件 jieba
- Python中文分词组件jieba
- python基础===jieba模块,Python 中文分词组件
- 中文分词:python-jieba-安装及使用样例
- Python 中文分词组件 jieba
- 结巴分词(Python中文分词组件)
- 使用python jieba库进行中文分词
- Python 文本挖掘:jieba中文分词和词性标注
- 使用python 的结巴(jieba)库进行中文分词
- Python中文分词实现方法(安装pymmseg)