Java----IO详解
2016-11-23 09:50
453 查看
IO是java中很重要的一块,包含了对文件,文件目录,二进制流文件等各种资源的操作,同时IO操作复杂多变,用得好会提高性能,用的不好导致效率低下,所以详细了解并掌握IO相关知识是很有必要的。
IO主要分为字节流和字符流,然后每一种又分为输入流和输出流,涉及到的类很多,下面一一分析。
说明:FileInputStream是没有缓冲功能的,但是上面的程序里fis将读出的字节放到了字节数组bytes中实现了缓存功能。
输出结果如下:
从结果可以看出,我们写入了两个对象,但是只读出了一个,那么应该怎样读出所有的对象呢?方法是循环读取,用EOFException作为边界结束,像这样:
如果你觉得上面的方式不那么优雅的话,还可以这样:
这个类我不知道存在的意义是什么?在知乎上找到一个回答是说将byte数组转换为InputStream,从而可以使用一些InputStream的API,但是我个人觉得直接操作byte数组更方便啊。欢迎留言讨论。
输出结果是:hello,i am contents
第一:BufferedInputStream的read()方法会使用默认的byte[]来缓存,虽然还是一个字节一个字节的读,但是是从缓存的byte[]里面读取了,而FileInputStream一个字节一个字节的直接从数据源读取,IO操作增加了很多。
第二:BufferedInputStream存在的意义是封装了mark和reset方法,如果有mark和reset的操作,用这个流比较好。
结果可以看到,读取完了以后,从我们mark的位置开始从新读取(这里的从新读取不是又进行一次IO操作,而是用之前缓存的那个byte[],这样就提高了效率):
关于mark(int readlimit)的参数是表明读取多少字节标记才失效,但是实际中是取readlimit和BufferedInputStream类的缓冲区(默认缓存大小byte[1024*8])大小两者中的最大值,而并非完全由readlimit确定。
还是先上类图:
IO主要分为字节流和字符流,然后每一种又分为输入流和输出流,涉及到的类很多,下面一一分析。
字节流—-InputStream和OutputStream
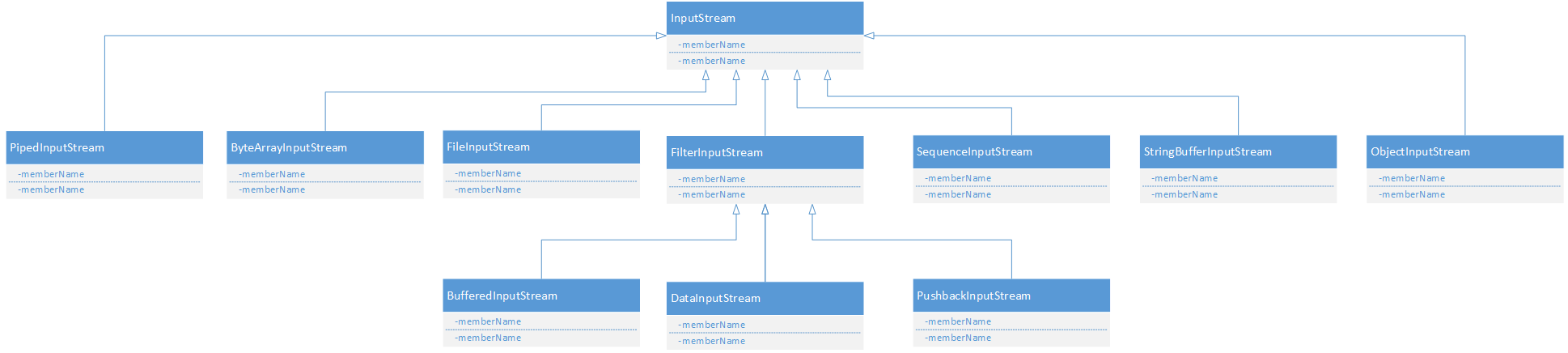
先上类图,InputStream这个大家庭的:(1)文件流:FileInputStream
public static void testStream(){
try {
byte [] bytes = new byte [12];
FileInputStream fis = new FileInputStream(new File("D:\\javaFile\\test/hah.txt"));
while(fis.read(bytes)!=-1){
System.out.println("Each:"+new String(bytes));
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}说明:FileInputStream是没有缓冲功能的,但是上面的程序里fis将读出的字节放到了字节数组bytes中实现了缓存功能。
while(fis.read()!=-1) //这样就没有缓存功能,一个一个字节读取
(2)对象流:ObjectInputStream
public static void testStream(){
try {
//为了读取,我们先写一个文件,注意这个文件是二进制的,所以打开看是乱码
FileOutputStream fos = new FileOutputStream("D:\\javaFile\\test\\student.txt");
ObjectOutputStream oop = new ObjectOutputStream(fos);
oop.writeObject(new Student(001 , "wangliang" , true , 22));
oop.writeObject(new Student(002 , "lisi" , false , 22));
//开始读取
FileInputStream fis = new FileInputStream("D:\\javaFile\\test\\student.txt");
ObjectInputStream ons = new ObjectInputStream(fis);
//一次只能读取一个Object对象出来
Student stu = (Student) ons.readObject();
System.out.println("age:"+stu.stuAge);
System.out.println("No:"+stu.stuId);
System.out.println("name:"+stu.stuName);
System.out.println("sex:"+(stu.stuSex==true?"男":"女"));
} catch (IOException | ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}输出结果如下:
age:22 No:1 name:wangliang sex:男
从结果可以看出,我们写入了两个对象,但是只读出了一个,那么应该怎样读出所有的对象呢?方法是循环读取,用EOFException作为边界结束,像这样:
try{
while(true){
Student stu = (Student) ons.readObject();
System.out.println("age:"+stu.stuAge);
System.out.println("No:"+stu.stuId);
System.out.println("name:"+stu.stuName);
System.out.println("sex:"+(stu.stuSex==true?"男":"女"));
}
}catch(EOFException e){}如果你觉得上面的方式不那么优雅的话,还可以这样:
//如果插入是可控的,那么可以在结尾插入一个结束标记符,一般为null.但是如果还要追加数据的话就比较麻烦了。
oop.writeObject(null);
//然后在读取的时候读到这个结束符就判定结束了
while(true){
Student stu = (Student) ons.readObject();
if(stu == null) break;
System.out.println("age:"+stu.stuAge);
System.out.println("No:"+stu.stuId);
System.out.println("name:"+stu.stuName);
System.out.println("sex:"+(stu.stuSex==true?"男":"女"));
}(3)字节数组流:ByteArrayInputStream
ByteArrayInputStream的两个构造函数都需要接受一个byte数组,不同于其他流接受文件或者流。//ByteArrayInputStream
byte[] byteArray = {'a','b',8,'c','d','e',-128,127,0,-1,2,'i'};
ByteArrayInputStream bais = new ByteArrayInputStream(byteArray);
int tem;
while((tem = bais.read())!=-1){
//在读取到8后,跳过后面的c,d,e三个字节
if(tem==8)
bais.skip(3);
System.out.println("byte:"+tem);
}这个类我不知道存在的意义是什么?在知乎上找到一个回答是说将byte数组转换为InputStream,从而可以使用一些InputStream的API,但是我个人觉得直接操作byte数组更方便啊。欢迎留言讨论。
(4)字符流:StringBufferInputStream
这个用作将一个字符串转换为流对象,现在早已被标记out了,可以用 StringReader或者ByteArrayInputStream代替。(5)顺序合并流:SequenceInputStream
这个流的作用呢,就是将几个流按照顺序一个一个去读取出来,可以保证顺序。//第一种写法
FileInputStream fis = new FileInputStream("D:\\javaFile\\test\\hah.txt");
FileInputStream fis1 = new FileInputStream("D:\\javaFile\\test\\hah1.txt");
SequenceInputStream sis = new SequenceInputStream(fis , fis1);
byte[] temp = new byte [1024];
while(sis.read(temp)!=-1){
System.out.println("Sequence:"+new String(temp));
}
//第二种写法
Enumeration en;
Vector<FileInputStream> vectors = new Vector<FileInputStream>();
vectors.addElement(fis1);
vectors.addElement(fis);
en = vectors.elements();
SequenceInputStream sis2 = new SequenceInputStream(en);
byte[] temp2 = new byte [1024];
while(sis2.read(temp2)!=-1){
System.out.println("Sequence2:"+new String(temp2));
}(6)管道流:PipedInputStream和PipedOutputStream
这两个必须配套使用,管道流用于跨线程数据交互。首先将PipedInputStream和PipedOutputStream通过connect方法绑定,然后在A线程中通过PipedOutputStream写数据,此时,写入的数据会发送到与之关联的PipedInputStream中,在线程B中就可以读取数据了。//管道流测试
//创建输入输出流
final PipedOutputStream pos = new PipedOutputStream();
final PipedInputStream pis = new PipedInputStream();
try {
//关联起来
pos.connect(pis);
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
//线程A发数据
new Thread(){
@Override
public void run(){
try {
pos.write("hello,i come from thread A!".getBytes());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}.start();
//线程B接受数据
new Thread(){
@Override
public void run(){
byte [] temp = new byte[27];
try {
pis.read(temp);
System.out.println("来自线程A的消息:"+new String(temp));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}.start();(7)回退流:PushbackInputStream
在读取下一个字节(或者下一个字节数组)前用unread推回流的前端,注意这个会影响流的mark和reset方法,使用者两个方法前一定要先判断。//PushbackInputStream测试
try {
FileInputStream fis = new FileInputStream("D:\\javaFile\\test\\hah.txt");
//最多可以插入512个字节,是总共的字节数,不是一次的
PushbackInputStream pbis = new PushbackInputStream(fis ,30 );
byte [] temp3 = new byte[5];
while(pbis.read(temp3)!=-1){
if(new String(temp3).equals("hello")){
pbis.unread("i am contents".getBytes());
//continue;
}
System.out.println("PushbackInputStream:"+new String(temp3));
}
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}输出结果是:hello,i am contents
(8)缓存流:BufferedInputStream
关于这个流需要好好说道说道;首先,看到这个流,再联想到上面讲FileInputStream时使用缓存时的场景,你可能会疑问有什么区别呢?FileInputStream用read(byte [])也可以缓存啊。第一:BufferedInputStream的read()方法会使用默认的byte[]来缓存,虽然还是一个字节一个字节的读,但是是从缓存的byte[]里面读取了,而FileInputStream一个字节一个字节的直接从数据源读取,IO操作增加了很多。
第二:BufferedInputStream存在的意义是封装了mark和reset方法,如果有mark和reset的操作,用这个流比较好。
mark和reset
mark()是标记当前位置,reset可以回到标记的位置。光说不练假把式,上代码://mark,reset测试
byte[] samplebyte = {'a','b','c','d','e','f','h','i','j','k'};
//将byte[]读入ByteArrayInputStream
ByteArrayInputStream bis = new ByteArrayInputStream(samplebyte);
//用BufferedInputStream封装ByteArrayInputStream
BufferedInputStream buffer = new BufferedInputStream(bis);
//开始读取
try {
int curbyte;
//标记只回退一次
boolean haveMarked = false;
while((curbyte=buffer.read())!=-1){
//在读取到c的时候mark,参数是限制最多字节数
if(curbyte == 'c' && !haveMarked){
if(buffer.markSupported()){
buffer.mark(5);
haveMarked = true;
}
}
System.out.print(curbyte+",");
}
//在读取到h的时候回到标记的位置
if(buffer.markSupported())
buffer.reset();
int curbyte2 ;
while((curbyte2=buffer.read())!=-1){
System.out.print(curbyte2+":");
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}结果可以看到,读取完了以后,从我们mark的位置开始从新读取(这里的从新读取不是又进行一次IO操作,而是用之前缓存的那个byte[],这样就提高了效率):
97,98,99,100,101,102,104,105,106,107,100:101:102:104:105:106:107:
关于mark(int readlimit)的参数是表明读取多少字节标记才失效,但是实际中是取readlimit和BufferedInputStream类的缓冲区(默认缓存大小byte[1024*8])大小两者中的最大值,而并非完全由readlimit确定。
字符流
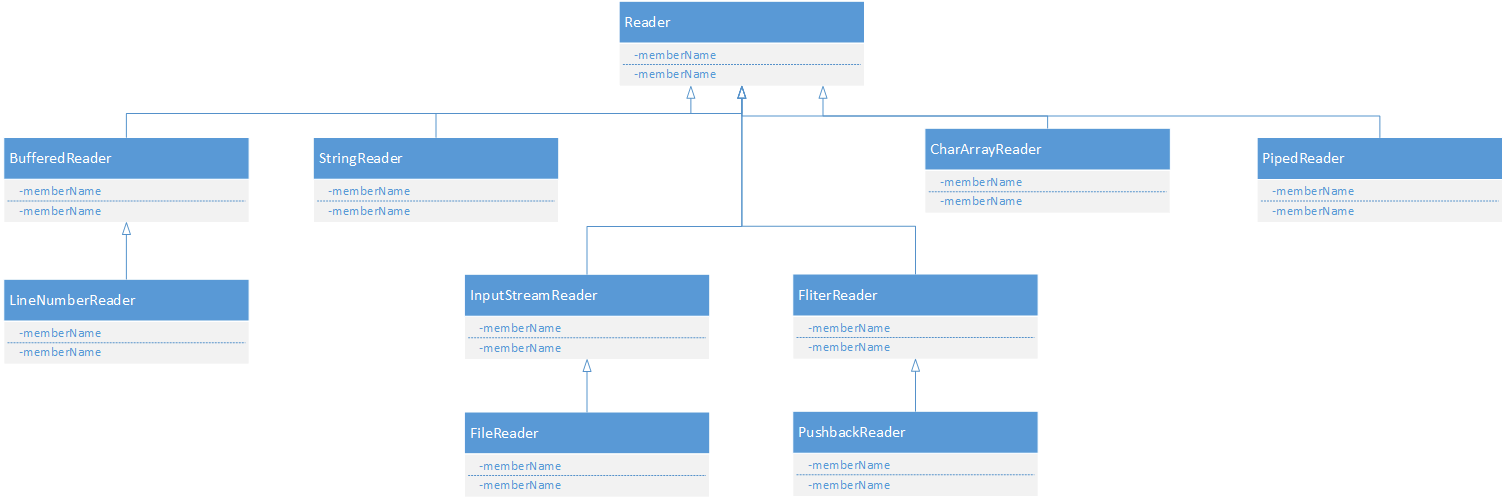
顾名思义了,字符流呢是以字符为操作单位了。还是先上类图:
大部分类的用法和字节流的用法差不多,就不一一赘述了,只有一个LineNumberReader多了一个按行读取的方法。
//LineNumberReader
try {
Reader fileReader2 = new FileReader("D:\\javaFile\\test\\hah.txt");
LineNumberReader lineNumberReader = new LineNumberReader(fileReader2);
String line;
while((line=lineNumberReader.readLine())!=null){
System.out.println("LineNumberReader:"+line);
}
} catch (IOException e2) {
// TODO Auto-generated catch block
e2.printStackTrace();
}
//CharArrayReader和BufferedReader
char[] char1 = {'a' ,1,'我',234,1234};
char[] tempchar;
BufferedReader bufferReader = new BufferedReader(new CharArrayReader(char1));
int temp;
try {
while((temp = bufferReader.read())!=-1){
System.out.println("char:"+temp);
}
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
//FileReader
try {
FileInputStream fileInputStream = new FileInputStream("D:\\javaFile\\test\\hah.txt");
int bytecount = 0;
while(fileInputStream.read()!=-1){
bytecount++;
}
System.out.println("字节数:"+bytecount);
Reader fileReader = new FileReader("D:\\javaFile\\test\\hah.txt");
int count = 0;
while(fileReader.read()!=-1){
count++;
}
System.out.println("字符数:"+count);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}基本上关于IO的知识点都梳理在这里了,不管是字符流还是字节流,都只讲解了输入流,输出流基本都和输入流是一一对应的。IO涉及到的类比较多,系统完整的学习一次大有裨益。

相关文章推荐
- Java IO最详解
- java IO详解
- java io详解及各输入输出类介绍
- Java IO最详解
- java io系列16之 PrintStream(打印输出流)详解
- Java IO最详解
- (九)java.io.FileSystem抽象类详解
- (九)java.io.FileSystem抽象类详解
- Java IO:BufferedInputStream使用详解及源码分析
- (十)java.io.File类详解
- JavaIO(01)File类详解
- Java IO最详解
- Java IO最详解
- java中的IO详解(下)
- java中的io系统详解
- Java IO详解(六)------序列化与反序列化(对象流)
- (一)java.io.DataInput接口及源码详解
- java IO最详解
- (五)java.io.ObjectInput接口详解
- (六)java.io.ObjectStreamConstants接口详解