python 老司机开车之二爬取福利妹纸图片
2016-11-23 00:00
309 查看
摘要: python 爬虫 福利
在进行老司机开车之一时(即微信开车公众号)无意中发现这样一个福利妹纸图地址,妹纸图都还挺不错的,但是每次翻页的时候各种弹出式广告,非常烦,于是想着把图片都down下来,然后放到路由器的samb服务上,这样可以用手机轻松访问了!!
效果图:
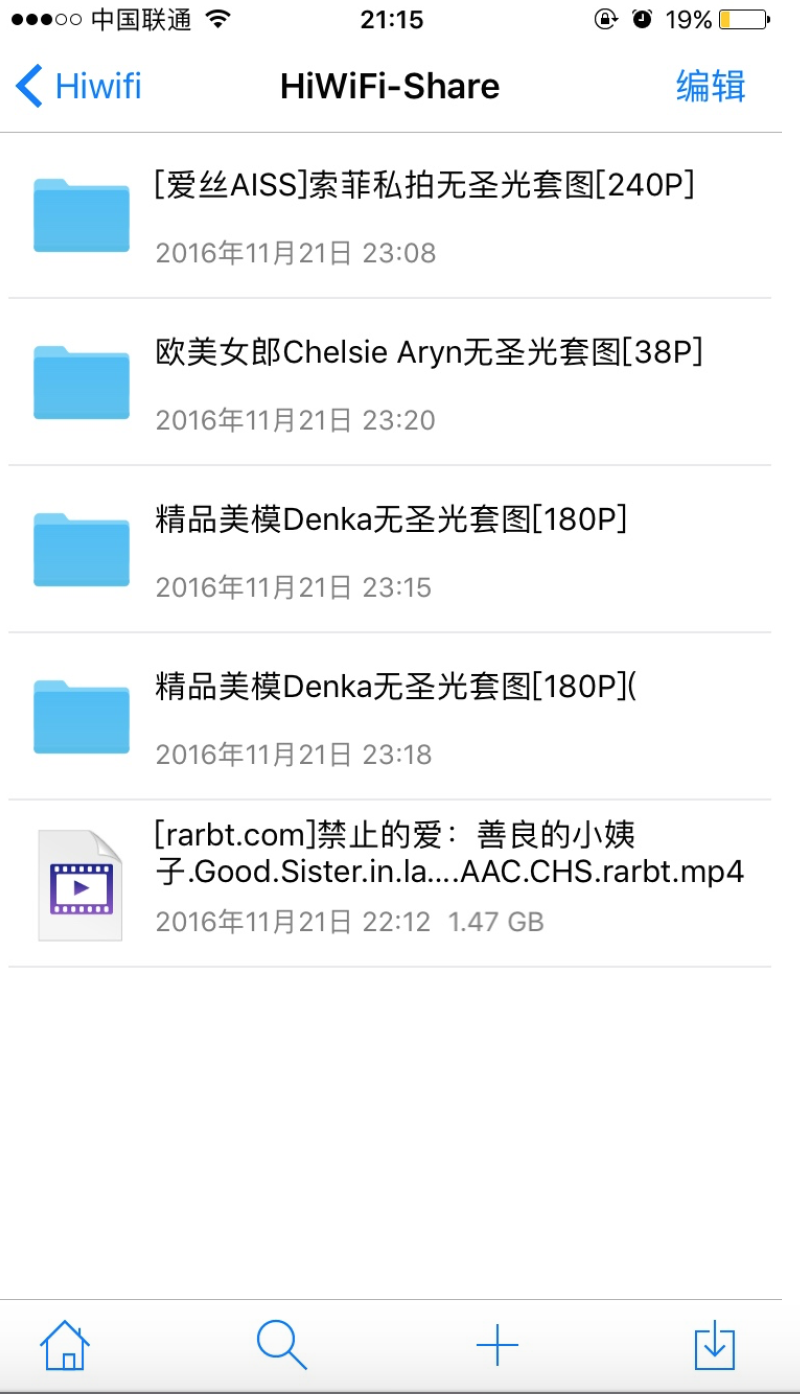
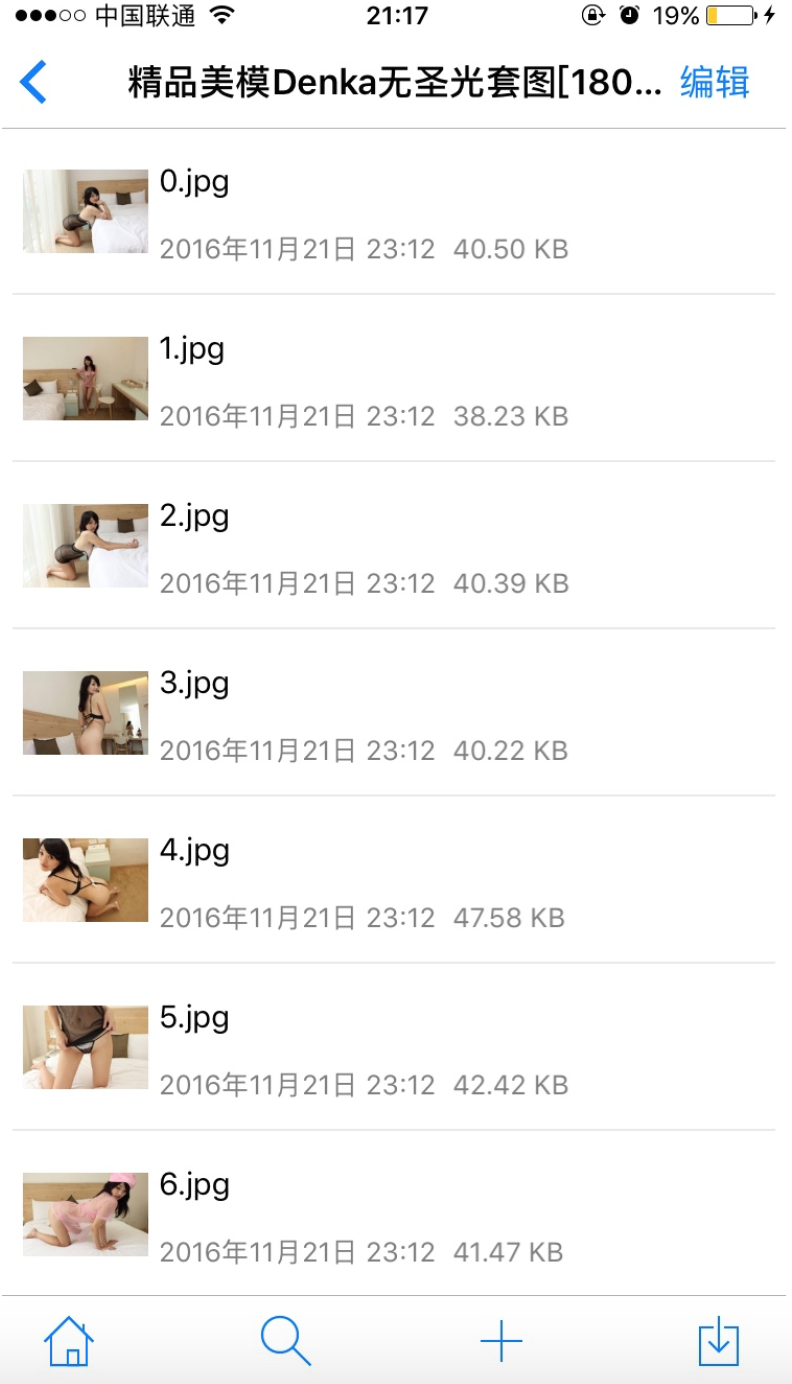
先上源码:注意修改下载路径
在进行老司机开车之一时(即微信开车公众号)无意中发现这样一个福利妹纸图地址,妹纸图都还挺不错的,但是每次翻页的时候各种弹出式广告,非常烦,于是想着把图片都down下来,然后放到路由器的samb服务上,这样可以用手机轻松访问了!!
效果图:
先上源码:注意修改下载路径
#-*- coding:utf-8 -*-
import urllib
import urllib2
import re
import os
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
class BeatifulGirl:
#初始化基本链接地址以及下载路径地址
def __init__(self):
self.baseurl = 'http://zhaofuli.xyz/luyilu/'
self.basepath = '/Volumes/Python/'
#获取目录内容,读取链接
def get_content(self,url):
res = requests.get(url)
html = BeautifulSoup(res.text,'lxml')
content = html.find_all("a",class_="thumbnail")
#查询对应的标签并把href值加入到list里
content_list = []
for i in content:
content_list.append(i.get('href'))
return content_list
#读取目录链接里的图片
def get_img(self,url):
#构造头文件,获取所有图片地址
headers = { #'Host': 'images.126176.com:8818',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'DNT': '1',
'Referer':'http://zhaofuli.xyz/luyilu/2016/1031/2571.html',
#'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
#'If-Modified-Since': 'Mon, 31 Oct 2016 11:43:36 GMT'
}
data = None
#获取html编码格式为gbk
html = urllib.urlopen(url).read().decode('gbk')
#获取图片地址
imgre = re.compile(r'<p>.*?<img src="(.*?)"')
imglist = re.findall(imgre, html)
#获取文件夹名称
pathre = re.findall(re.compile(r'<h1 class="article-title">(.*?)</h1>'),html)
path = pathre[0]
#判断title里是否包含括号,若包含则去掉括号,将同一主题的图片放在一个目录中
if path.find('(') != -1:
pathname = self.basepath+path[:-3]
else:
pathname = self.basepath+path
print pathname
self.mkdir(pathname)
x=0
for imgurl in imglist:
print imgurl
n = imgurl.rfind('-')
jpg_name = imgurl[n+1:].encode('utf8')
#使用header模拟浏览器登陆,避免重定向
req = urllib2.Request(imgurl,None,headers)
rt = urllib2.urlopen(req)
fw = open(pathname+'/%s'%jpg_name,'wb')
fw.write(rt.read())
fw.close()
x += 1
print("正在下载第%s张图片"%x)
def get_page(self,url):
#这里由于页面上无法获取总页数,于是采用固定页面遍历,不过一般不会超过20页,所以够了
num = 1
for num in range(1,20):
#循环读取页面
print("正在读取页面:" + url)
self.get_img(url)
print("第%s页读取完成"%num)
#获取下页地址
res = requests.get(url)
html = BeautifulSoup(res.text,'lxml')
next_page = html.find("li",class_="next-page")
if next_page:
for i in next_page:
next_url = i.get('href')
#判断下页地址是否存在,若存在则拼接出新的url,若不存在则跳出循环
#截取当前url,拼接获取到的下页地址
n = url.rfind('/')
url = url[:n+1]+next_url
else:
break
def mkdir(self,path):
path = path.strip()
#判断路径是否存在
isExist = os.path.exists(path)
print path
if not isExist:
os.mkdir(path)
return True
else:
print u'目录已存在'
return False
def main(self):
#构造首页链接地址
num = 1
#这里只爬取前2页数据,可根据需要修改,图片较多,建议每次读取3页以内
for num in range(1,2):
url_list = 'http://zhaofuli.xyz/luyilu/list_5_%s.html'%num
content_list = self.get_content(url_list)
print("加载目录第%s页。。。"%num)
#读取首页中各链接内容,调用get_page获取所有页面内容
i = 0
for url in content_list:
url = content_list[i]
print url
page_url = 'http://zhaofuli.xyz' + url
self.get_page(page_url)
i+=1
num+=1
test = BeatifulGirl()
test.main()

相关文章推荐
- Python 老司机开车之三爬取福利妹纸图片(多线程学习)
- (已加马赛克)10 行代码判定色*情*图片——Python 也可以系列之二
- 手把手教你用Python爬虫煎蛋妹纸海量图片
- python实现顺序结构基本爬虫,爬取福利图片
- (已加马赛克)10 行代码判定色*情*图片——Python 也可以系列之二
- (已加马赛克)10 行代码判定色*情*图片——Python 也可以系列之二
- 手把手教你用Python爬虫煎蛋妹纸海量图片
- 用Python批量爬取妹纸图片
- (已加马赛克)10 行代码判定色*情*图片——Python 也可以系列之二
- 手把手教你用 Python 爬虫煎蛋妹纸海量图片
- 用Python开车的老司机
- python 3 网络爬取图片之二
- Python爬煎蛋网的图片——老司机的第一步
- 昨天晚上写了个 Python 程序,下载了一个福利网站 5000 来张妹子图片
- 【python爬虫】游民星空福利和壁纸帖图片爬虫
- 【教程】记录:python基础爬虫代码(下载妹子福利图片)
- python爬取妹纸图片
- python pil 第三方库实战之二:图片叠加
- Python练手爬虫系列No.1 知乎福利收藏夹图片批量下载