一次linux服务器load高达600多的异常处理过程
2016-11-22 17:38
357 查看
#一次服务器load值狂飙的处理过程以及思路 处理时间:2016_11_22:17:00
#收到报警78服务器load值报警,登录机器uptime查看load值

#load值超高,第一反应top一下,想找出来是哪个程序消耗了大量的cpu
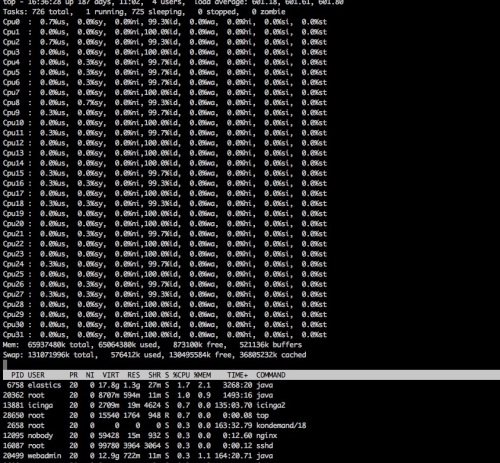
#没有发现,接着就是vmstat查看正常,iostat,free -m,一切正常,有几个操作未截图
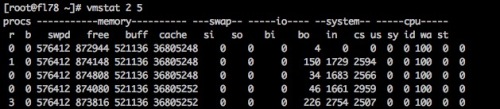
#当这一切都正常的时候人有点懵逼,甚至都准备去看看源码uptime 的load值是怎么计算出来的
然而找到了代码块并看不懂,继续查看问题,执行了netstat查看到有syn_recv这就证明有服务建立
连接失败,于是找到这个程序,然后netstat -tnlp|grep 看了一下。
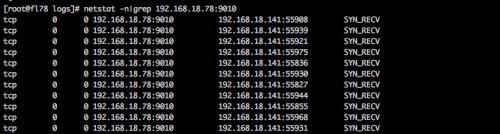
#开始怀疑这个java程序有问题,于是查看日志,当天是11月22号,而程序日志在11月20号5点32分就停了,于是确定程序问题。

#执行重启tomcat命令,这个就不用讲了,进入bin目录shutdown.sh 发现进程没了之后startup.sh
然后等了几分钟load就降下来了

纪录一下处理故障的思路和经历,说起来比较轻松,但是实际还是花了一定的时间,在执行netstat之前毫无思路,卡了一段时间,都准备翻阅源码,比较尴尬,而且也没找到更深层次的原因。
#收到报警78服务器load值报警,登录机器uptime查看load值
#load值超高,第一反应top一下,想找出来是哪个程序消耗了大量的cpu
#没有发现,接着就是vmstat查看正常,iostat,free -m,一切正常,有几个操作未截图
#当这一切都正常的时候人有点懵逼,甚至都准备去看看源码uptime 的load值是怎么计算出来的
然而找到了代码块并看不懂,继续查看问题,执行了netstat查看到有syn_recv这就证明有服务建立
连接失败,于是找到这个程序,然后netstat -tnlp|grep 看了一下。
#开始怀疑这个java程序有问题,于是查看日志,当天是11月22号,而程序日志在11月20号5点32分就停了,于是确定程序问题。
#执行重启tomcat命令,这个就不用讲了,进入bin目录shutdown.sh 发现进程没了之后startup.sh
然后等了几分钟load就降下来了
纪录一下处理故障的思路和经历,说起来比较轻松,但是实际还是花了一定的时间,在执行netstat之前毫无思路,卡了一段时间,都准备翻阅源码,比较尴尬,而且也没找到更深层次的原因。

相关文章推荐
- linux服务器一次内存异常的处理
- 一次delete速度异常慢的处理过程
- 一次RAC共享磁盘映射问题导致RAC异常重启的故障处理过程
- 一次delete速度异常慢的处理过程
- 记一次linux服务器问题处理过程
- 一次delete速度异常慢的处理过程
- 记一次RabbitMQ服务器异常断电之后,服务重启异常的处理过程
- 存储过程中异常处理
- 一次挂死(hang)的处理过程及经验
- oracle 在存储过程自定义异常的处理方法
- PQ8分区故障的一次处理过程
- SQL Server中使用异常处理调试存储过程(转)
- 一次VMware虚拟XP系统登录密码忘记的处理过程
- 使用Biztalk的异常处理解决交换过程中的出错问题
- db2 存储过程异常处理
- 对Linux服务器的一次渗透测试过程
- 精通COBOL--16.3.3 输入过程中的异常处理
- 一次TempDB损毁的处理过程
- Oracle中函数,过程和触发器等的错误异常处理
- 一次网站故障处理过程