Python爬虫爬取网站新闻
2016-11-19 22:02
495 查看
网站分析
为了方便爬取,所以选择了手机版的简版网易新闻网址。获取新闻链接列表的网址为http://3g.163.com/touch/article/list/BA8J7DG9wangning/1-40.html
其中1-40表示获取列表的当前页数,爬取列表时只需修改页数即可。
爬取过程
获取新闻链接地址
使用requests包读取新闻列表页面,然后使用正则表达式提取出其中的新闻页面链接,返回urls列表def getList(url): li = requests.get(url) res = r'url":"http:.*?.html' urls = re.findall(res,li.text) for i in range(len(urls)): urls[i] = urls[i][6:] return urls
获取新闻内容
使用requests获取到新闻页面的内容,然后使用BeautifulSoup包解析web内容。def getNews(url):
url = url[:-5]+"_0.html"
ss = requests.get(url)
soup = BeautifulSoup(ss.text,"html.parser")
title = soup.title.string[:-6].encode('utf-8')
time = soup.find("div","about").contents[0][9:].encode('utf-8')
type = soup.find("div","position lBlue").contents[3].string.encode('utf-8')
content = soup.find("div","content").get_text()[1:-1].encode('utf-8')
news = News(title,time,type,content)
return news手机简版新闻通常把一个新闻分成几个页面显示,导致爬取内容很麻烦。经过分析发现,在新闻链接地址后加_0即可显示全部新闻内容,所以先处理一下链接地址。然后使用requests获取web页面,再用BeautifulSoup提取新闻的标题,时间,类别和内容。
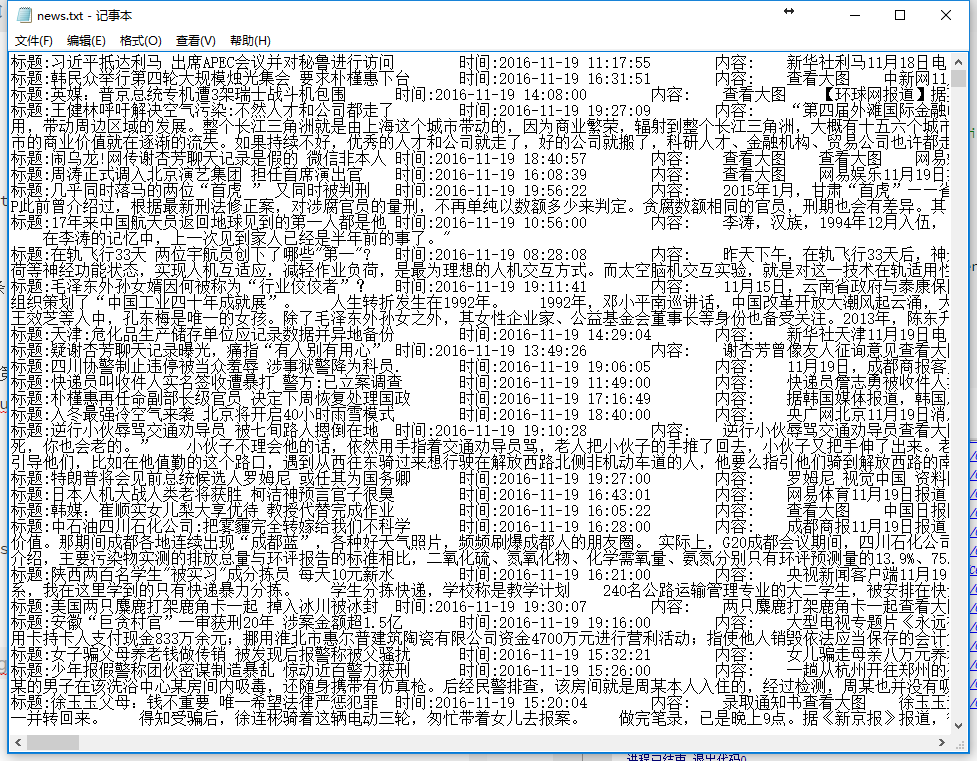
将结果保存
def saveAsTxt(news):
file = open('E:/news.txt','a')
file.write("标题:" + news.title +
"\t时间:" + news.time +
"\t类型:"+ news.type +
"\t内容:"+ news.content +
"\"\n")运行程序
程序代码
# encoding: utf-8
import requests
import re
from bs4 import BeautifulSoup
import time
class News:
def __init__(self,title,time,type,content):
self.title = title #新闻标题
self.time = time #新闻时间
self.type = type #新闻类别
self.content = content #新闻内容
def getList(url): #获取新闻链接地址
li = requests.get(url)
res = r'url":"http:.*?.html' #正则表达式获取链接地址
urls = re.findall(res,li.text)
for i in range(len(urls)):
urls[i] = urls[i][6:]
return urls
def getNews(url): #获取新闻内容
url = url[:-5]+"_0.html" #处理链接获取全文
ss = requests.get(url)
soup = BeautifulSoup(ss.text,"html.parser") #获取新闻内容,注意编码
title = soup.title.string[:-6].encode('utf-8')
time = soup.find("div","about").contents[0][9:].encode('utf-8')
# type = soup.find("div","position lBlue").contents[3].string.encode('utf-8')
content = soup.find("div","content").get_text()[1:-1].encode('utf-8')
news = News(title,time,type,content)
return news
def saveAsTxt(news): #保存新闻内容
file = open('E:/news.txt','a')
file.write("标题:" + news.title +
"\t时间:" + news.time +
# "\t类型:"+ news.type +
"\t内容:"+ news.content +
"\"\n")
start = time.clock()
sum = 0
for i in range(1,40):
wangzhi = "http://3g.163.com/touch/article/list/BA8J7DG9wangning/%s-40.html" %i
urls = getList(wangzhi)
sum = sum + len(urls)
# print "当前页解析出 %s 条" %len(urls)
j = 1
for url in urls:
print "正在读取第%s页第%s/%s条:%s" %(i,j,len(urls),url.encode('utf-8'))
news = getNews(url)
saveAsTxt(news)
j = j + 1
end = time.clock()
print "共爬取%s条新闻,耗时%f s" %(sum,end - start)执行结果
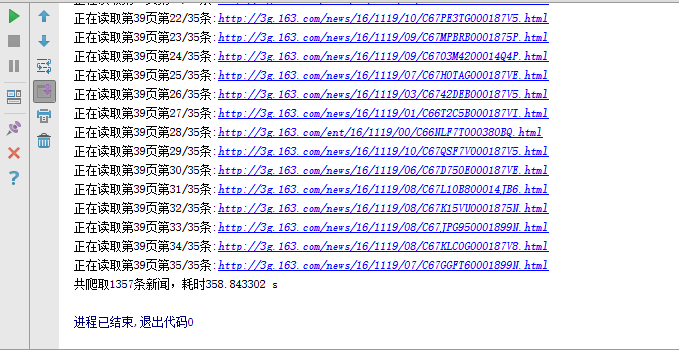
程序运行的时间主要和页面打开的速度有关,若网速理想的话程序运行还是挺快的。
注
该程序还属于入门级的爬虫,代理ip池以及多线程效率问题都没有涉及到。但是如果附加上你需要这些后续处理,比如有效地存储(数据库应该怎样安排)
有效地判重(这里指网页判重,咱可不想把人民日报和抄袭它的大民日报都爬一遍)
有效地信息抽取(比如怎么样抽取出网页上所有的地址抽取出来,“朝阳区奋进路中华道”),搜索引擎通常不需要存储所有的信息,比如图片我存来干嘛…
及时更新(预测这个网页多久会更新一次)
如你所想,这里每一个点都可以供很多研究者十数年的研究。(知乎:谢科)
附录
requests文档Beautiful Soup 4.4.0 文档

相关文章推荐
- python3爬虫 爬取图片,爬取新闻网站文章并保存到数据库
- 基于python Scrapy的爬虫——爬取某网站新闻内容
- Python爬虫项目,获取所有网站上的新闻,并保存到数据库中,解析html网页等(未完待续)
- python爬虫 根据关键字在新浪网站查询跟关键字有关的新闻条数(按照时间查询)
- 【Python】爬虫爬取各大网站新闻(一)
- python爬虫实战,多线程爬取京东jd html页面:无需登录的网站的爬虫实战 推荐
- 【python爬虫】根据查询词爬取网站返回结果
- Python爬虫获取JSESSIONID登录网站
- Python爬虫抓取某音乐网站MP3(下载歌曲、存入Sqlite)
- python实现虎扑网站图片爬虫
- python3简单爬虫 (爬取各个网站上的图片)
- python 爬虫获取网站信息(一)
- python 爬虫获取网站信息(二)
- Python写爬虫-爬甘农大学校新闻
- 在IDLE 中用python 写新闻爬虫
- Python爬虫模拟登录带验证码网站
- python爬虫抓取新华网新闻并自动生成word文档
- Python爬虫——爬取网站的图片
- 【Python】爬虫入门--抓取网站图片
- python 实现网站图片抓取小爬虫