完数的MPI并行程序设计-并行计算
2016-11-19 15:22
197 查看
目录
1.问题描述...
2
2.算法设计...
2
2.1
串行算法设计... 2
2.2
MPI消息传递并行算法设计... 3
2.3
理论加速比分析... 3
3.基于MPI的并行算法实现...
3
3.1
代码及注释... 3
3.2
单机运行... 6
3.2.1
执行结果截图... 6
3.2.2
实验加速比分析... 7
3.3
多机运行... 7
3.3.1
程序执行说明... 7
3.3.2
执行结果截图... 8
3.3.3
实验加速比分析... 9
3.4
遇到的问题及解决方案... 9
3.4.1错误代码...
9
3.4.2后果...
10
3.4.3正确代码...
10
3.4.4分析...
10
①因为1不算入一个完数,所以令数i=2,初始化答案值ans=0;
②因为1是任何数的一个因数,所以可初始化因数之和sum=1;
③令数k=2;
④如果数i能整除数k,说明k是i的一个因数,则sum += k;
⑤若k<=i/2(控制范围保证i%k能进行计算),++k,转到④,否则转到⑥;
⑥若sum = i,++ans;
⑦若i <=n,++i,转到②,否则转到⑧;
⑧函数返回答案值ans。
①初始化MPI执行环境,进程号为零时输入n,随后将 n 值广播出去;②中间计算步骤与串行计算步骤相同;
③暂存各个进程并行计算得到的部分和,通过MPI_SUM函数来汇总数据,各个进程全部执行完毕即得最终计算答案。
本机测试中,p=2:若n=10000,则S=1.99976;若n=100000,则S=1.99998。
*/
//test.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include "mpi.h"
#include <cstdlib>
#include <iostream>
#include <cmath>
#include <ctime>
#include <omp.h>
#include <windows.h>
using namespacestd;
int Perfect(long long n) //普通的串行算法
{
int ans = 0; // n以内的完数个数
long long i,k; //循环变量
for (i = 2; i <= n; i++) //1不算入一个完数。
{
long long sum = 1; //数的因数之和,1是任何数的一个因数。
for (k= 2; k <= i / 2; k++) //k<=i/2是要保证i%k能进行计算。
if(i%k == 0)
sum += k; //因数之和
if(sum == i) //找到一个完数
{
++ans;
printf("%lld\n", sum);
} //函数返回答案值ans
}
return ans;
}
int main(int argc, char *argv[])
{
long long n,temp;
long long i,k; //循环变量
int done = 0, myid, numprocs;
long longmypi, pi, ans;// n以内的完数个数
double startwtime, endwtime;
int namelen;
charprocessor_name[MPI_MAX_PROCESSOR_NAME];
MPI_Init(&argc,&argv);//初始化
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);//标示相应进程组中有多少个进程
printf("numprocs= %d\n", numprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);//标示各个MPI进程,告诉调用该函数进程的当前进程号
MPI_Get_processor_name(processor_name,&namelen);//获取当前进程执行的机器名称
fprintf(stderr, "Process %d on %s\n", myid, processor_name);
fflush(stderr);
while (!done)
{
if(myid == 0)
{
printf("输入一个数字不超过: (0 退出) ");
fflush(stdout);
scanf_s("%lld",&n);
temp = n;
startwtime = MPI_Wtime();
printf("%lld以内的完数有:\n",n);
}
/***************MPI并行计算n以内的完数个数*********************/
MPI_Bcast(&n, 1, MPI_LONG, 0,MPI_COMM_WORLD);//将 n 值广播出去
if (n== 0) done = 1;
else
{
ans = 0;
for (i= myid + 2; i <= n; i += numprocs) //1不算入一个完数。
{
long long sum = 1; //数的因数之和,1是任何数的一个因数。
for (k= 2; k <= i / 2; k++) //k<=i/2是要保证i%k能进行计算。
if(i%k == 0)
sum += k; //因数之和
if(sum == i) //找到一个完数
{
++ans; //函数返回答案值ans
printf("%lld\n", sum);
}
}
mypi = ans;//各个进程并行计算得到的部分和
MPI_Reduce(&mypi, &pi, 1,MPI_LONG, MPI_SUM, 0, MPI_COMM_WORLD);//每个进程从sendBuf向root进程的receiveBuf发数据,通过opration函数(例如MPI_SUM)来汇总数据
if(myid == 0)
{
//执行累加的号进程将近似值打印出来
printf("Sum= %d\n", pi);
endwtime = MPI_Wtime();//返回自过去某一时刻调用时的时间间隔,以秒为单位
printf("MPI时间= %f\n",endwtime - startwtime);
/*****************串行计算时间***********************/
startwtime = MPI_Wtime();
printf("Sum= %d\n", Perfect(temp)); //输出串行计算出的n以内的完数个数
endwtime = MPI_Wtime();
printf("Serail时间= %f\n",endwtime - startwtime);//输出串行计算时间
/****************************************/
}
}
}
MPI_Finalize();
system("pause");
return 0;
}
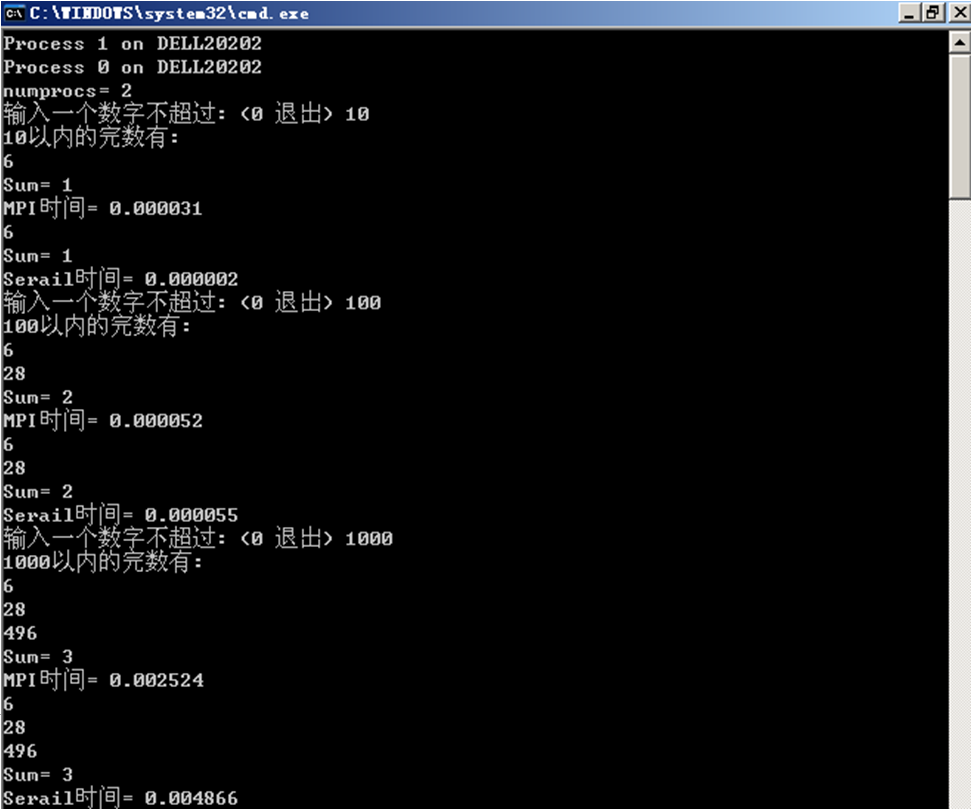
(2)大数据量获得较好加速比的执行结果截图
(体现串行时间、并行时间和好的加速比)
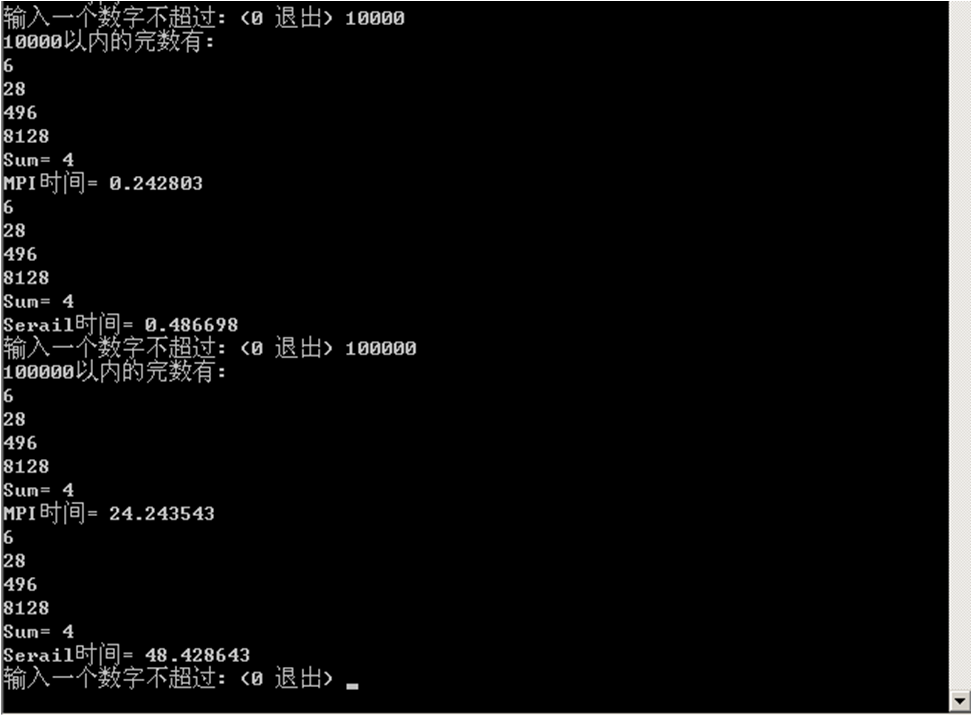
实验加速比与理论加速比相差不大,在误差允许范围内可认为结果正确。
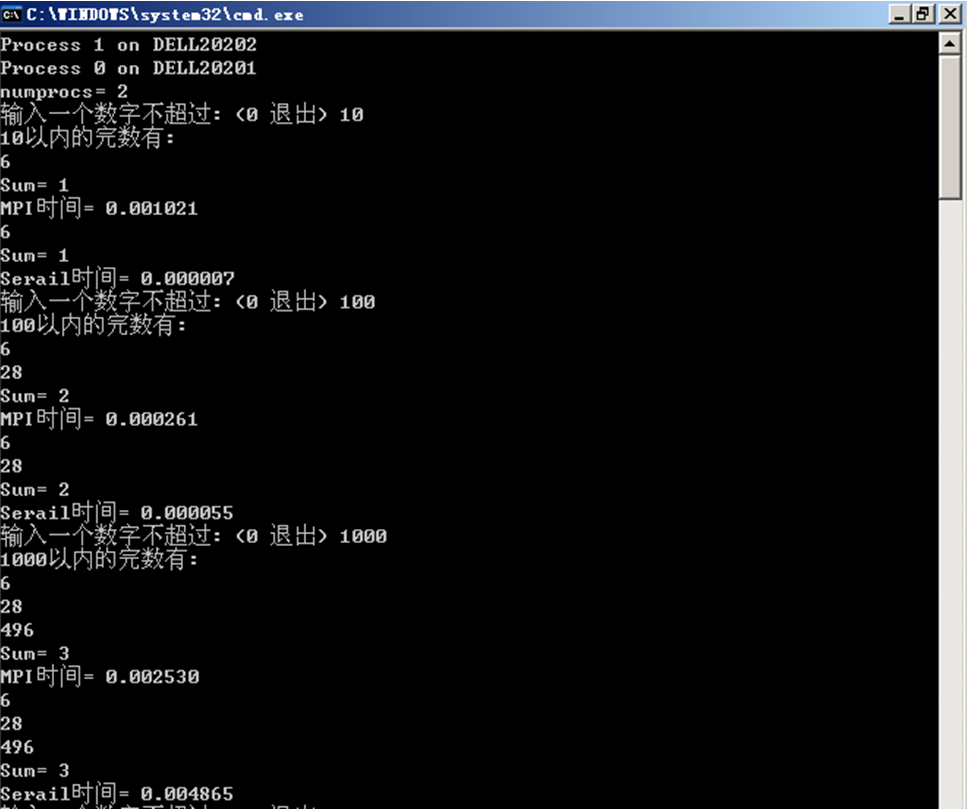
(2)大数据量获得较好加速比的执行结果截图
(体现串行时间、并行时间和好的加速比)
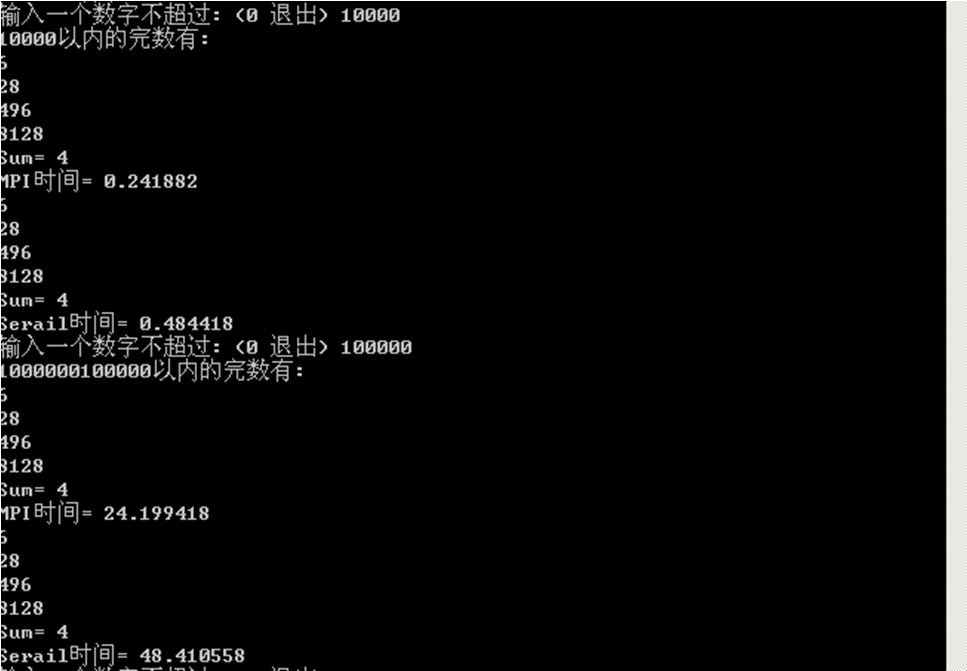
实验加速比与理论加速比相差不大,在误差允许范围内可认为结果正确。
double mypi, pi;
(此处略中间代码)
mypi =ans;//各个进程并行计算得到的部分和
MPI_Reduce(&mypi,&pi, 1, MPI_LONG, MPI_SUM, 0, MPI_COMM_WORLD);
(此处略中间代码)
mypi =ans;//各个进程并行计算得到的部分和
MPI_Reduce(&mypi,&pi, 1, MPI_LONG, MPI_SUM, 0, MPI_COMM_WORLD);
1.问题描述...
2
2.算法设计...
2
2.1
串行算法设计... 2
2.2
MPI消息传递并行算法设计... 3
2.3
理论加速比分析... 3
3.基于MPI的并行算法实现...
3
3.1
代码及注释... 3
3.2
单机运行... 6
3.2.1
执行结果截图... 6
3.2.2
实验加速比分析... 7
3.3
多机运行... 7
3.3.1
程序执行说明... 7
3.3.2
执行结果截图... 8
3.3.3
实验加速比分析... 9
3.4
遇到的问题及解决方案... 9
3.4.1错误代码...
9
3.4.2后果...
10
3.4.3正确代码...
10
3.4.4分析...
10
1.问题描述
一个数如果恰好等于它的因子之和,这个数就称为“完数”。例如6=1+2+3,再如8的因子和是7(即1+2+4),8不是完数。输入一个数n,编程找出n以内的所有完数及其个数。2.算法设计
2.1 串行算法设计
串行算法步骤如下:①因为1不算入一个完数,所以令数i=2,初始化答案值ans=0;
②因为1是任何数的一个因数,所以可初始化因数之和sum=1;
③令数k=2;
④如果数i能整除数k,说明k是i的一个因数,则sum += k;
⑤若k<=i/2(控制范围保证i%k能进行计算),++k,转到④,否则转到⑥;
⑥若sum = i,++ans;
⑦若i <=n,++i,转到②,否则转到⑧;
⑧函数返回答案值ans。
2.2 MPI消息传递并行算法设计
并行算法步骤如下:①初始化MPI执行环境,进程号为零时输入n,随后将 n 值广播出去;②中间计算步骤与串行计算步骤相同;
③暂存各个进程并行计算得到的部分和,通过MPI_SUM函数来汇总数据,各个进程全部执行完毕即得最终计算答案。
2.3 理论加速比分析
若p个处理器上数据量为n,则S=np/(n+2plogp)。本机测试中,p=2:若n=10000,则S=1.99976;若n=100000,则S=1.99998。
3.基于MPI的并行算法实现
3.1 代码及注释(变量名 名字首字母 开头)
/*问题描述:一个数如果恰好等于它的因子之和,这个数就称为“完数”。例如6=1+2+3,再如8的因子和是7(即1+2+4),8不是完数。编程找出1000以内的所有完数。*/
//test.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include "mpi.h"
#include <cstdlib>
#include <iostream>
#include <cmath>
#include <ctime>
#include <omp.h>
#include <windows.h>
using namespacestd;
int Perfect(long long n) //普通的串行算法
{
int ans = 0; // n以内的完数个数
long long i,k; //循环变量
for (i = 2; i <= n; i++) //1不算入一个完数。
{
long long sum = 1; //数的因数之和,1是任何数的一个因数。
for (k= 2; k <= i / 2; k++) //k<=i/2是要保证i%k能进行计算。
if(i%k == 0)
sum += k; //因数之和
if(sum == i) //找到一个完数
{
++ans;
printf("%lld\n", sum);
} //函数返回答案值ans
}
return ans;
}
int main(int argc, char *argv[])
{
long long n,temp;
long long i,k; //循环变量
int done = 0, myid, numprocs;
long longmypi, pi, ans;// n以内的完数个数
double startwtime, endwtime;
int namelen;
charprocessor_name[MPI_MAX_PROCESSOR_NAME];
MPI_Init(&argc,&argv);//初始化
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);//标示相应进程组中有多少个进程
printf("numprocs= %d\n", numprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);//标示各个MPI进程,告诉调用该函数进程的当前进程号
MPI_Get_processor_name(processor_name,&namelen);//获取当前进程执行的机器名称
fprintf(stderr, "Process %d on %s\n", myid, processor_name);
fflush(stderr);
while (!done)
{
if(myid == 0)
{
printf("输入一个数字不超过: (0 退出) ");
fflush(stdout);
scanf_s("%lld",&n);
temp = n;
startwtime = MPI_Wtime();
printf("%lld以内的完数有:\n",n);
}
/***************MPI并行计算n以内的完数个数*********************/
MPI_Bcast(&n, 1, MPI_LONG, 0,MPI_COMM_WORLD);//将 n 值广播出去
if (n== 0) done = 1;
else
{
ans = 0;
for (i= myid + 2; i <= n; i += numprocs) //1不算入一个完数。
{
long long sum = 1; //数的因数之和,1是任何数的一个因数。
for (k= 2; k <= i / 2; k++) //k<=i/2是要保证i%k能进行计算。
if(i%k == 0)
sum += k; //因数之和
if(sum == i) //找到一个完数
{
++ans; //函数返回答案值ans
printf("%lld\n", sum);
}
}
mypi = ans;//各个进程并行计算得到的部分和
MPI_Reduce(&mypi, &pi, 1,MPI_LONG, MPI_SUM, 0, MPI_COMM_WORLD);//每个进程从sendBuf向root进程的receiveBuf发数据,通过opration函数(例如MPI_SUM)来汇总数据
if(myid == 0)
{
//执行累加的号进程将近似值打印出来
printf("Sum= %d\n", pi);
endwtime = MPI_Wtime();//返回自过去某一时刻调用时的时间间隔,以秒为单位
printf("MPI时间= %f\n",endwtime - startwtime);
/*****************串行计算时间***********************/
startwtime = MPI_Wtime();
printf("Sum= %d\n", Perfect(temp)); //输出串行计算出的n以内的完数个数
endwtime = MPI_Wtime();
printf("Serail时间= %f\n",endwtime - startwtime);//输出串行计算时间
/****************************************/
}
}
}
MPI_Finalize();
system("pause");
return 0;
}
3.2 单机运行
3.2.1 执行结果截图
(1)小数据量验证正确性的执行结果截图(不考虑加速比)(2)大数据量获得较好加速比的执行结果截图
(体现串行时间、并行时间和好的加速比)
3.2.2 实验加速比分析
若n=10000,S=Ts/Tp=2.0045;若n=100000,S=Ts/Tp=1.9976。实验加速比与理论加速比相差不大,在误差允许范围内可认为结果正确。
3.3 多机运行
3.3.1 程序执行说明
使用Dell20201与Dell20202两台机器组成双核运行平台,进程分配如图所示。3.3.2 执行结果截图
(1)小数据量验证正确性的执行结果截图(不考虑加速比)(2)大数据量获得较好加速比的执行结果截图
(体现串行时间、并行时间和好的加速比)
3.3.3 实验加速比分析
若n=10000,S=Ts/Tp=2.0027;若n=100000,S=Ts/Tp=2.000484。实验加速比与理论加速比相差不大,在误差允许范围内可认为结果正确。
3.4 遇到的问题及解决方案
3.4.1错误代码
long long ans;double mypi, pi;
(此处略中间代码)
mypi =ans;//各个进程并行计算得到的部分和
MPI_Reduce(&mypi,&pi, 1, MPI_LONG, MPI_SUM, 0, MPI_COMM_WORLD);
3.4.2后果
通过MPI_SUM函数来汇总的数据pi错误,输出为零。3.4.3正确代码
long long mypi, pi, ans;//ans是n以内的完数个数(此处略中间代码)
mypi =ans;//各个进程并行计算得到的部分和
MPI_Reduce(&mypi,&pi, 1, MPI_LONG, MPI_SUM, 0, MPI_COMM_WORLD);
3.4.4分析
相互赋值的两个变量的数据类型必须相同,不然无法完成赋值,始终为默认值零。
相关文章推荐
- 完数的OpenMP并行程序设计-并行计算
- 完数的Java多线程并行程序设计-并行计算
- OpenMP并行计算程序设计-n以内的完数的个数
- MPI 学习 -- 高性能计算之并行编程技术 --- MPI并行程序设计 都志辉编著
- MPI 学习 -- 高性能计算之并行编程技术 --- MPI并行程序设计 都志辉编著
- Linux下安装配置MPI并行计算环境
- 不变的道——多核、并行程序设计、网格计算、超级计算机、云计算
- 并行计算大作业之多边形相交(OpenMP、MPI、Java、Windows)
- Windows 7系统下搭建MPI(并行计算)环境
- 并行计算MPI(一):MPI入门
- MPI并行程序设计之平行Rank
- 大数据并行计算利器之MPI/OpenMP
- MPI实现fft的迭代算法 源于并行计算——结构。算法。编程中伪码
- 并行计算MPI研究
- MPI并行计算环境的建立
- ubuntu下搭建MPI并行计算环境
- 方阵行列式并行化计算(OpenMP,MPI),并计算加速比
- 矩阵乘法的MPI并行计算
- MPI并行计算环境搭建以及集群测试
- Windows系统下搭建MPI(并行计算)环境