Hadoop首字母统计程序的编译运行
2016-11-19 14:51
162 查看
这里假定已经安装好了hadoop的环境,在Linux下运行hadoop命令能够正常执行。
首字母统计程序为InitialCount.java,首字母出现的次数用加号表示,若出现次数少于3次则不显示
使用了ubunt16.04系统, hadoop版本1.0.4
1.格式化HDFS
若是首次安装Hadoop,先启动Hadoop到相关服务,格式化namenode,secondarynamenode,tasktracker
~$ source /usr/local/hadoop/conf/hadoop-env.sh
~$ hadoop namenode -format
(注意:第一次安装hadoop集群的时候,需要运行hadoopnamenode -format格式化文件系统,初始化一些目录和文件。后面每次启动hadoop集群的时候,就不需要每次运行hadoopnamenode
-format。除非不得已,否则不要轻易格式化文件系统,格式化文件系统会建立新的dfs name dir目录,造成该目录下之前数据的丢失。)
2.启动Hadoop
执行start-all.sh来启动所有服务,包括namenode,datanode,start-all.sh脚本用来装载守护进程。也可以单独启动与关闭。
sean@ubuntu:~$ cd /usr/local/hadoop/bin
sean@ubuntu:/usr/local/hadoop/bin$ start-all.sh

在hadoop目录下用Java的jps命令列出所有的守护进程来验证安装成功
sean@ubuntu:/usr/local/hadoop/bin$ cd ..
sean@ubuntu:/usr/local/hadoop$ jps
出现如下列表,表明成功
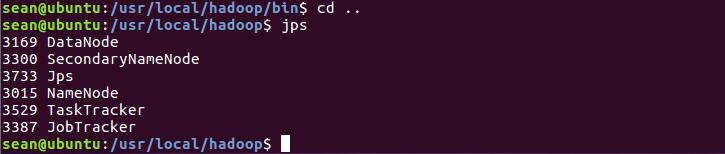
注:如果DataNode没有出现,可能有两种情况:
(1):访问http://localhost:50070,点击页面中的Namenode
logs链接,在logs页面点击hadoop-hadoop-datanode-ubuntu.log 链接,发现在日志中有此提示:Invalid directory in dfs.data.dir: Incorrect permission for /usr/local/hadoop/hdfs/data, expected:
rwxr-xr-x, while actual: rwxr-xrwx 。原因是data文件夹权限问题,执行:chmod g-w /usr/local/hadoop/hdfs/data,修改文件夹权限后,再次启动Hadoop,问题解决。
(2).多次格式化导致NameNode和DataNode的namespaceID不一致。有两种方法可以解决,(推荐)第一种方法是删除DataNode的所有资料(将集群中每个datanode的/hdfs/data/current中的VERSION删掉,然后执行hadoop
namenode -format重启集群,错误消失;第二种方法是修改每个DataNode的namespaceID(位于/hdfs/data/current/VERSION文件中)或修改NameNode的namespaceID(位于/hdfs/name/current/VERSION文件中),使其一致。
3.将InitialCount.java复制到ubuntu下的一个目录,这里我复制到/home/Hadoop_Test/Hadoop_Initialcount
4.在该目录(/home/Hadoop_Test/Hadoop_Initialcount)下创建initialcount_classes目录,用于存放编译InitialCount.java生成的class文件
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ mkdir initialcount_classes
5.编译InitialCount.java文件,其中-classpath选项表示要引用hadoop官方的包,-d选项表示要将编译后
的class文件生成的目标目录。
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ javac -classpath /usr/local/hadoop/hadoop-core-1.0.4.jar -d initialcount_classes InitialCount.java
(hadoop-core-1.0.4.jar 请替换为你目录下对应的文件,否则会报错)
6.将编译后的class文件打包
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ jar -cvf initialcount.jar -C initialcount_classes/ .
7.测试可在本地用echo生成一个文件,用于输入数据(省略号为你想统计的文本),也可以直接将一个文本文件放进当前文件夹
4000
$ echo “.......” > inputfile
8.在hadoop上建立一个目录,里面建立输入文件的目录
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ hadoop fs -ls /initial_count

9.将本地刚刚写的的inputfile上传到hadoop上的input目录
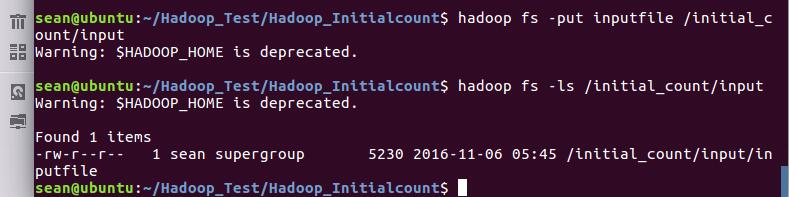
10.运行jar,以建立的input目录作为输入参数
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ hadoop jar initialcount.jar InitialCount /initial_count/input /initial_count/output
11.查看output目录是否有结果
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ hadoop fs -getmerge /initial_count/output initialcount_result
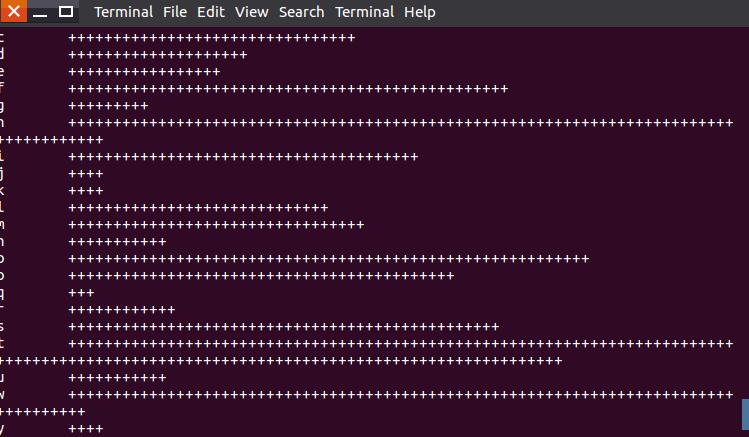
13.查看下载下来的计算结果
附:InitialCount.java
ubuntu上搭建hadoop环境参考此文章:http://blog.csdn.net/hitwengqi/article/details/8008203
<>
首字母统计程序为InitialCount.java,首字母出现的次数用加号表示,若出现次数少于3次则不显示
使用了ubunt16.04系统, hadoop版本1.0.4
1.格式化HDFS
若是首次安装Hadoop,先启动Hadoop到相关服务,格式化namenode,secondarynamenode,tasktracker
~$ source /usr/local/hadoop/conf/hadoop-env.sh
~$ hadoop namenode -format
(注意:第一次安装hadoop集群的时候,需要运行hadoopnamenode -format格式化文件系统,初始化一些目录和文件。后面每次启动hadoop集群的时候,就不需要每次运行hadoopnamenode
-format。除非不得已,否则不要轻易格式化文件系统,格式化文件系统会建立新的dfs name dir目录,造成该目录下之前数据的丢失。)
2.启动Hadoop
执行start-all.sh来启动所有服务,包括namenode,datanode,start-all.sh脚本用来装载守护进程。也可以单独启动与关闭。
sean@ubuntu:~$ cd /usr/local/hadoop/bin
sean@ubuntu:/usr/local/hadoop/bin$ start-all.sh
在hadoop目录下用Java的jps命令列出所有的守护进程来验证安装成功
sean@ubuntu:/usr/local/hadoop/bin$ cd ..
sean@ubuntu:/usr/local/hadoop$ jps
出现如下列表,表明成功
注:如果DataNode没有出现,可能有两种情况:
(1):访问http://localhost:50070,点击页面中的Namenode
logs链接,在logs页面点击hadoop-hadoop-datanode-ubuntu.log 链接,发现在日志中有此提示:Invalid directory in dfs.data.dir: Incorrect permission for /usr/local/hadoop/hdfs/data, expected:
rwxr-xr-x, while actual: rwxr-xrwx 。原因是data文件夹权限问题,执行:chmod g-w /usr/local/hadoop/hdfs/data,修改文件夹权限后,再次启动Hadoop,问题解决。
(2).多次格式化导致NameNode和DataNode的namespaceID不一致。有两种方法可以解决,(推荐)第一种方法是删除DataNode的所有资料(将集群中每个datanode的/hdfs/data/current中的VERSION删掉,然后执行hadoop
namenode -format重启集群,错误消失;第二种方法是修改每个DataNode的namespaceID(位于/hdfs/data/current/VERSION文件中)或修改NameNode的namespaceID(位于/hdfs/name/current/VERSION文件中),使其一致。
3.将InitialCount.java复制到ubuntu下的一个目录,这里我复制到/home/Hadoop_Test/Hadoop_Initialcount
4.在该目录(/home/Hadoop_Test/Hadoop_Initialcount)下创建initialcount_classes目录,用于存放编译InitialCount.java生成的class文件
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ mkdir initialcount_classes
5.编译InitialCount.java文件,其中-classpath选项表示要引用hadoop官方的包,-d选项表示要将编译后
的class文件生成的目标目录。
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ javac -classpath /usr/local/hadoop/hadoop-core-1.0.4.jar -d initialcount_classes InitialCount.java
(hadoop-core-1.0.4.jar 请替换为你目录下对应的文件,否则会报错)
6.将编译后的class文件打包
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ jar -cvf initialcount.jar -C initialcount_classes/ .
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ jar -cvf initialcount.jar -C initialcount_classes/ .
7.测试可在本地用echo生成一个文件,用于输入数据(省略号为你想统计的文本),也可以直接将一个文本文件放进当前文件夹
4000
$ echo “.......” > inputfile
8.在hadoop上建立一个目录,里面建立输入文件的目录
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ hadoop fs -ls /initial_count
9.将本地刚刚写的的inputfile上传到hadoop上的input目录
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ hadoop fs -put inputfile /initial_count/input sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ hadoop fs -ls /initial_count/input
10.运行jar,以建立的input目录作为输入参数
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ hadoop jar initialcount.jar InitialCount /initial_count/input /initial_count/output
11.查看output目录是否有结果
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ hadoop fs -ls /initial_count/output12.将该目录下所有文本文件合并后下载到本地
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ hadoop fs -getmerge /initial_count/output initialcount_result
13.查看下载下来的计算结果
sean@ubuntu:~/Hadoop_Test/Hadoop_Initialcount$ more initialcount_result
附:InitialCount.java
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class InitialCount {
public static class InitialCountMap extends
Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken().substring(0,1));
context.write(word, one);
}
}
}
public static class InitialCountReduce extends
Reducer<Text, IntWritable, Text, Text> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
if(sum>2)
{
StringBuffer sb = new StringBuffer("");
for(int i = 1;i<=sum;i++)
{
sb.append("+");
}
context.write(key, new Text(sb.toString()));
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(InitialCount.class);
job.setJobName("initialcount");
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(InitialCountMap.class);
job.setReducerClass(InitialCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}ubuntu上搭建hadoop环境参考此文章:http://blog.csdn.net/hitwengqi/article/details/8008203
<>

相关文章推荐
- Hadoop MapReduce示例程序WordCount.java手动编译运行解析
- 用命令行运行hadoop程序WordCount,编译hadoop程序报错
- Hadoop — 使用Eclipse编译运行MapReduce程序(Hadoop2.6.0)
- 使用Eclipse编译运行MapReduce程序_Hadoop2.6.0_Ubuntu/CentOS
- 使用Eclipse编译运行MapReduce程序 Hadoop2.6.0_Ubuntu/CentOS
- C程序访问hadoop程序编译通过后在运行的时候出现:WARN util.NativeCodeLoader错误。
- 使用命令行编译打包运行自己的MapReduce程序 Hadoop2.4.1
- Ubuntu14.0.4下,shell编译-打包-运行Hadoop2.7.2的MapReduce程序
- windows下使用Eclipse编译运行MapReduce程序 Hadoop2.6.0/Ubuntu
- Ubuntu系统下的Hadoop集群(4)_使用Eclipse编译运行MapReduce程序
- 创建编译运行MapReduce程序(Eclipse+Ubuntu14.04+Hadoop2.7.2)
- C程序访问hadoop出现的各种编译错误和运行时各种类DefFound异常的解决方法
- 使用命令行编译打包运行自己的MapReduce程序 Hadoop2.4.1
- C程序访问hadoop出现的各种编译错误和运行时各种类DefFound异常的解决方法(makefile的书写和环境变量的配置)
- 运行hadoop的WordCount程序——编译,打包,运行
- Hadoop示例程序WordCount编译运行
- hadoop——在命令行下编译并运行map-reduce程序
- 使用Eclipse编译运行MapReduce程序 Hadoop2.6.0/Ubuntu
- 使用命令行编译打包运行自己的MapReduce程序 Hadoop2.7.2
- 使用Eclipse编译运行MapReduce程序 Hadoop2.4.1