centos下搭建hadoop2.6.5
2016-11-17 15:33
295 查看
一 、centos集群环境配置
1.创建一个namenode节点,5个datanode节点
主机名
2.关闭防火墙,设置selinux为disabled
#service iptables stop
#chkconfig iptables off
设置selinux为disabled,如下图所示
#vim /etc/selinux/config
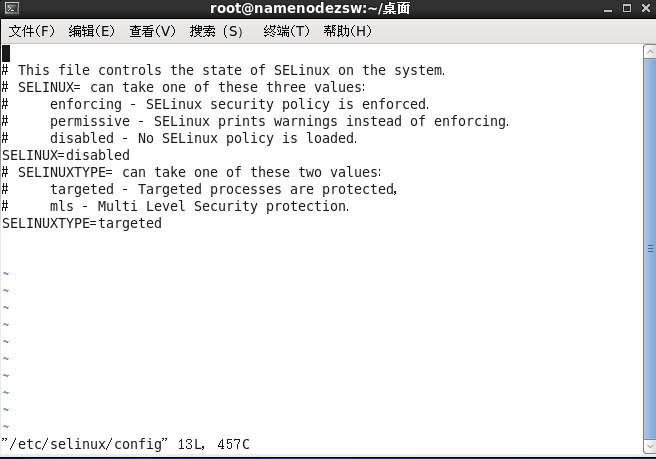
重启后生效,建议全部配置完成后再全部重启。
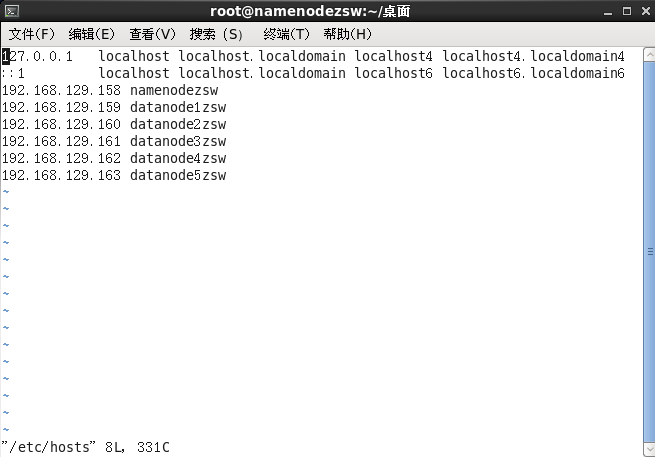
3.配置hosts文件
将各节点对应的主机名与IP地址记录在hosts文件中
vi /etc/hosts
本文所用java安装包为jdk-7u25-Linux-x64.tar.gz(百度上各种版本的都有)
解压到/opt目录下
修改环境变量:
#vi /etc/profile
在文件末尾添加以下内容
export JAVA_HOME=/opt/jdk1.7.0_25
export JAR_HOME=/opt/jdk1.7.0_25/jre
export ClASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAR_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
保存后退出,执行
#source /etc/profile
查看java版本:
#java -version
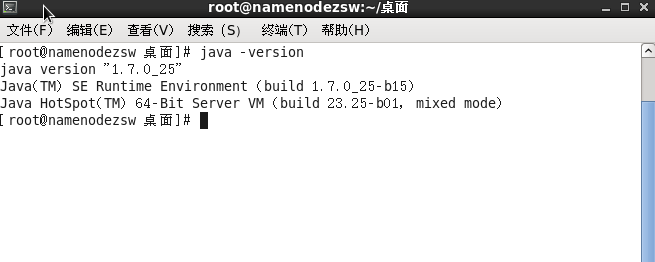
显示上图结果说明配置成功
注意:使用source \etc\profile命令尽在本终端有效,重启后才全部生效
提示:namenode节点和datanode节点上述配置都相同
二、设置各节点间SSH无密码通信
在一个节点namenodezsw上操作
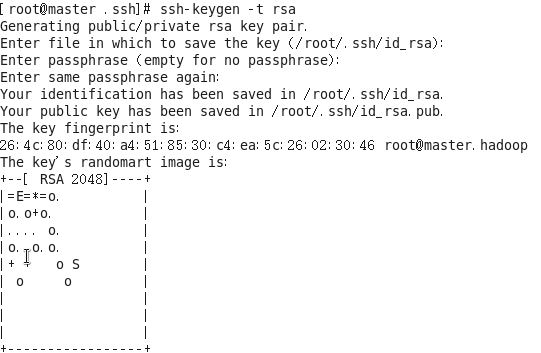
1.生成密钥对
#ssh-keygen -t rsa
按三次回车,结果如下图
2.将各个节点生成的公有密钥添加到authorized_keys
#cat .ssh/id_rsa.pub > .ssh/authorized_keys
#ssh 192.168.129.159 ssh-keygen -t rsa
#ssh 192.168.129.159 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
#ssh 192.168.129.160 ssh-keygen -t rsa
#ssh 192.168.129.160 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
#ssh 192.168.129.161 ssh-keygen -t rsa
#ssh 192.168.129.161 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
#ssh 192.168.129.162 ssh-keygen -t rsa
#ssh 192.168.129.162 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
#ssh 192.168.129.163 ssh-keygen -t rsa
#ssh 192.168.129.163 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
3.将authorized_keys文件传到各个节点
#scp /root/.ssh/authorized_keys root@192.168.129.159:/root/.ssh/authorized_keys
#scp /root/.ssh/authorized_keys root@192.168.129.160:/root/.ssh/authorized_keys
#scp /root/.ssh/authorized_keys root@192.168.129.161:/root/.ssh/authorized_keys
#scp /root/.ssh/authorized_keys root@192.168.129.162:/root/.ssh/authorized_keys
#scp /root/.ssh/authorized_keys root@192.168.129.163:/root/.ssh/authorized_keys
4.测试
#ssh 192.168.129.159 date
#ssh datanode1zsw date
1个namenode节点,5个datanode节点以此类推
两次ssh命令:
第一遍都需要输入yes,然后显示时间
第二遍则直接显示时间,说明配置成功
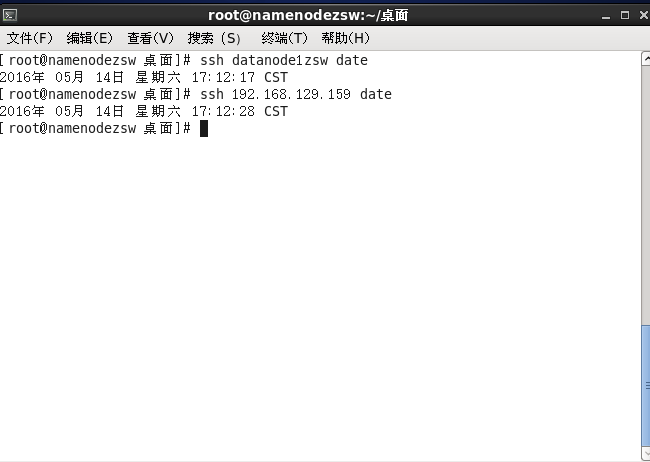
说明:每个节点上都要ssh命令其他的节点主机名和IP一下,检测是否可以
三、Hadoop集群搭建
1.去hadoop官网或者百度下载hadoop-2.6.0-tar.gz,然后解压到namenode的/opt目录下
2.修改配置文件
#cd /opt/hadoop-2.6.0/etc/hadoop
①修改 hadoop-env.sh和yarn-env.sh
export JAVA_HOME=/opt/jdk1.7.0_25
②修改core-site.xml
③修改hdfs-site.xml文件
④修改mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
⑤修改yarn-site.xml
⑥修改slaves文件
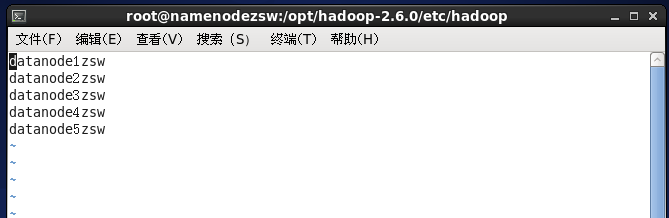
⑦配置环境变量
# vi /etc/profile
export JAVA_HOME=/opt/jdk1.7.0_25
export HADOOP_HOME=/opt/hadoop-2.6.0
export JAR_HOME=/opt/jdk1.7.0_25/jre
export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAR_HOME/lib
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
环境变量配置同样source /etc/profile命令本终端有效,重启后都有效
至此,修改完成
3.启动hadoop
使用scp -r /opt/hadoop-2.6.0/ hostname:/opt/命令将hadoop文件依次拷贝到5个datanode节点上。
在namenode上操作:
首先格式化
#hadoop namenode -format
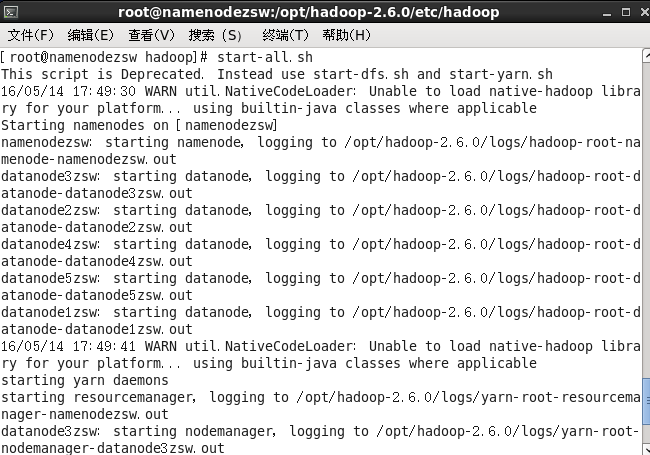
启动所有服务
#start-all.sh
4.验证
namenode上:
#jps
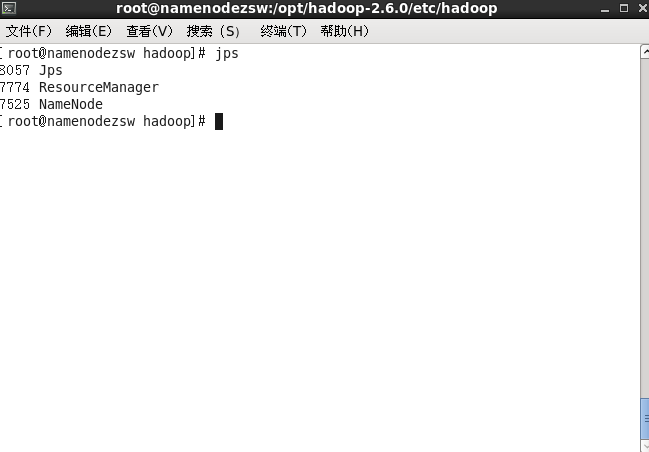
datanode上:
#jps
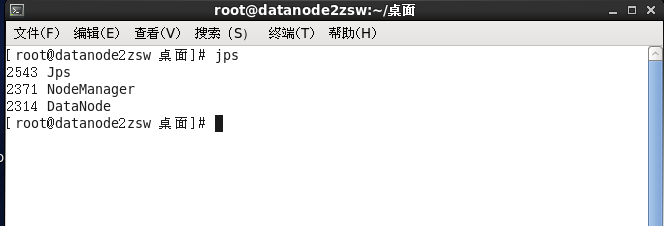
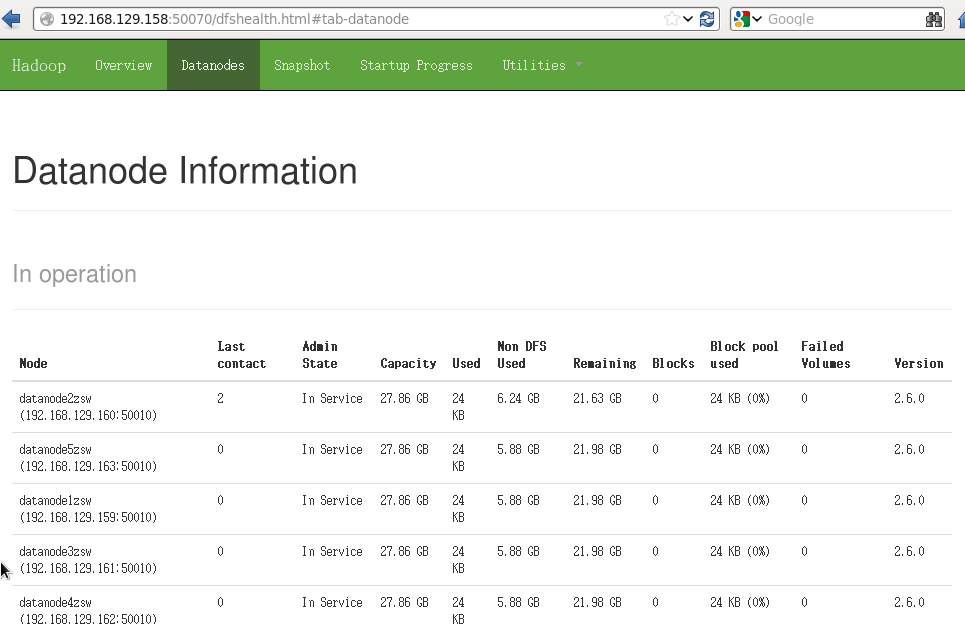
也可以使用 hadoop dfsadmin -report命令查看总体情况
至此集群搭建全部完成
遇到的问题
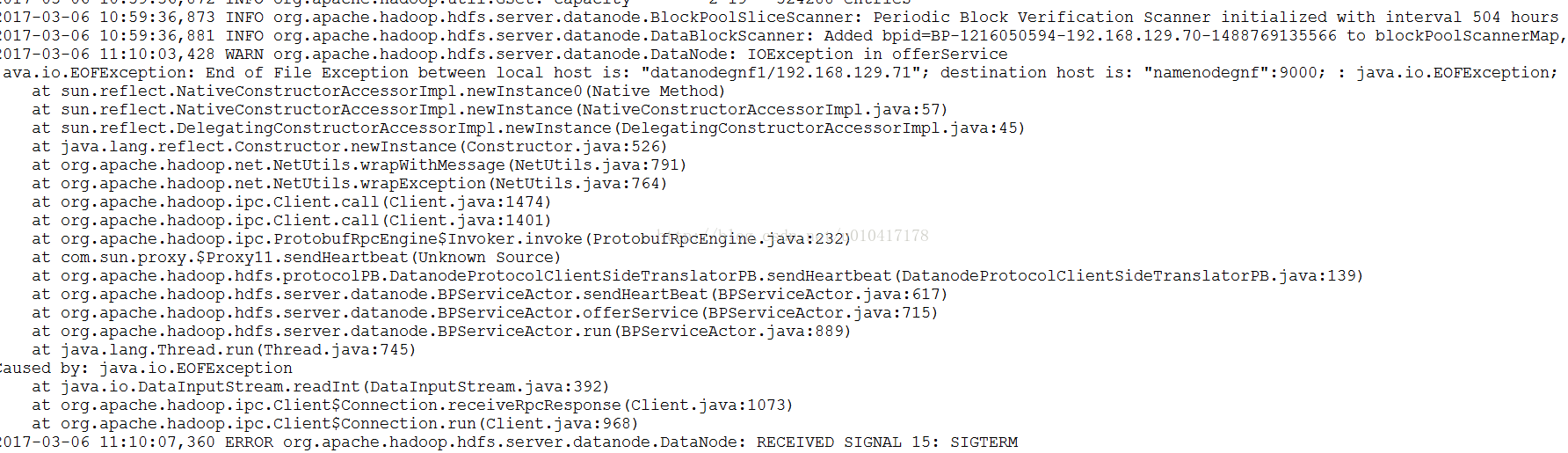

原因是hadoop格式化多次,导致namenode和datanode的clusterid不一样
解决方法:在hdfs-site.xml中有如下配置
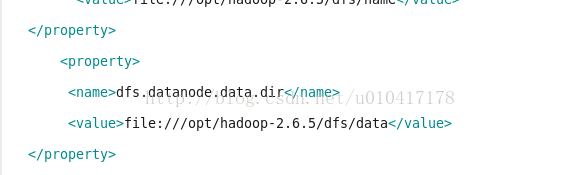
在hadoop-2.6.5/dfs/data下有current/version,打开version,找到里面的clusterId
找到log文件(在hadoop-2.6.5中的logs下),找到clusterId,并用该clusterId替换掉version中的clusterId
注意:改完后注意重启所有节点,改完后如果直接start-all.sh,可能又会生成不一样的clusterId
转载自:http://blog.csdn.net/zsw_2015/article/details/51406644
1.创建一个namenode节点,5个datanode节点
主机名
| IP | |
| namenodezsw | 192.168.129.158 |
| datanode1zsw | 192.168.129.159 |
| datanode2zsw | 192.168.129.160 |
| datanode3zsw | 192.168.129.161 |
| datanode4zsw | 192.168.129.162 |
| datanode5zsw | 192.168.129.163 |
#service iptables stop
#chkconfig iptables off
设置selinux为disabled,如下图所示
#vim /etc/selinux/config
重启后生效,建议全部配置完成后再全部重启。
3.配置hosts文件
将各节点对应的主机名与IP地址记录在hosts文件中
vi /etc/hosts
本文所用java安装包为jdk-7u25-Linux-x64.tar.gz(百度上各种版本的都有)
解压到/opt目录下
修改环境变量:
#vi /etc/profile
在文件末尾添加以下内容
export JAVA_HOME=/opt/jdk1.7.0_25
export JAR_HOME=/opt/jdk1.7.0_25/jre
export ClASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAR_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
保存后退出,执行
#source /etc/profile
查看java版本:
#java -version
显示上图结果说明配置成功
注意:使用source \etc\profile命令尽在本终端有效,重启后才全部生效
提示:namenode节点和datanode节点上述配置都相同
二、设置各节点间SSH无密码通信
在一个节点namenodezsw上操作
1.生成密钥对
#ssh-keygen -t rsa
按三次回车,结果如下图
2.将各个节点生成的公有密钥添加到authorized_keys
#cat .ssh/id_rsa.pub > .ssh/authorized_keys
#ssh 192.168.129.159 ssh-keygen -t rsa
#ssh 192.168.129.159 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
#ssh 192.168.129.160 ssh-keygen -t rsa
#ssh 192.168.129.160 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
#ssh 192.168.129.161 ssh-keygen -t rsa
#ssh 192.168.129.161 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
#ssh 192.168.129.162 ssh-keygen -t rsa
#ssh 192.168.129.162 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
#ssh 192.168.129.163 ssh-keygen -t rsa
#ssh 192.168.129.163 cat ~/.ssh/id_rsa.pub >>.ssh/authorized_keys
3.将authorized_keys文件传到各个节点
#scp /root/.ssh/authorized_keys root@192.168.129.159:/root/.ssh/authorized_keys
#scp /root/.ssh/authorized_keys root@192.168.129.160:/root/.ssh/authorized_keys
#scp /root/.ssh/authorized_keys root@192.168.129.161:/root/.ssh/authorized_keys
#scp /root/.ssh/authorized_keys root@192.168.129.162:/root/.ssh/authorized_keys
#scp /root/.ssh/authorized_keys root@192.168.129.163:/root/.ssh/authorized_keys
4.测试
#ssh 192.168.129.159 date
#ssh datanode1zsw date
1个namenode节点,5个datanode节点以此类推
两次ssh命令:
第一遍都需要输入yes,然后显示时间
第二遍则直接显示时间,说明配置成功
说明:每个节点上都要ssh命令其他的节点主机名和IP一下,检测是否可以
三、Hadoop集群搭建
1.去hadoop官网或者百度下载hadoop-2.6.0-tar.gz,然后解压到namenode的/opt目录下
2.修改配置文件
#cd /opt/hadoop-2.6.0/etc/hadoop
①修改 hadoop-env.sh和yarn-env.sh
export JAVA_HOME=/opt/jdk1.7.0_25
②修改core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-2.6.0/tmp</value> <description>Abase for other temporarydirectories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://namenodezsw:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>4096</value> </property> </configuration>
③修改hdfs-site.xml文件
configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:///opt/hadoop-2.6.0/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///opt/hadoop-2.6.0/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.nameservices</name> <value>h1</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>namenodezsw:50090</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
④修改mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <final>true</final> </property> <property> <name>mapreduce.jobtracker.http.address</name> <value>namenodezsw:50030</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>namenodezsw:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>namenodezsw:19888</value> </property> <property> <name>mapred.job.tracker</name> <value>http://namenodezsw:9001</value> </property> </configuration>
⑤修改yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties--> <property> <name>yarn.resourcemanager.hostname</name> <value>namenodezsw</value> </property> <property> <name>yarn.nodemanager.aux-servic c01e es</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>namenodezsw:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>namenodezsw:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>namenodezsw:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>namenodezsw:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>namenodezsw:8088</value> </property> </configuration>
⑥修改slaves文件
⑦配置环境变量
# vi /etc/profile
export JAVA_HOME=/opt/jdk1.7.0_25
export HADOOP_HOME=/opt/hadoop-2.6.0
export JAR_HOME=/opt/jdk1.7.0_25/jre
export CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAR_HOME/lib
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
环境变量配置同样source /etc/profile命令本终端有效,重启后都有效
至此,修改完成
3.启动hadoop
使用scp -r /opt/hadoop-2.6.0/ hostname:/opt/命令将hadoop文件依次拷贝到5个datanode节点上。
在namenode上操作:
首先格式化
#hadoop namenode -format
启动所有服务
#start-all.sh
4.验证
namenode上:
#jps
datanode上:
#jps
也可以使用 hadoop dfsadmin -report命令查看总体情况
至此集群搭建全部完成
遇到的问题
原因是hadoop格式化多次,导致namenode和datanode的clusterid不一样
解决方法:在hdfs-site.xml中有如下配置
在hadoop-2.6.5/dfs/data下有current/version,打开version,找到里面的clusterId
找到log文件(在hadoop-2.6.5中的logs下),找到clusterId,并用该clusterId替换掉version中的clusterId
注意:改完后注意重启所有节点,改完后如果直接start-all.sh,可能又会生成不一样的clusterId
转载自:http://blog.csdn.net/zsw_2015/article/details/51406644

相关文章推荐
- centos搭建hadoop2.6.5
- VBox下CentOS的hadoop伪分布环境的搭建(二)
- VBox下CentOS的hadoop伪分布环境的搭建(四)
- Hadoop2.X/YARN环境搭建--CentOS7.0系统配置
- 搭建Hadoop环境----CentOs安装和配置(二)
- 搭建Hadoop环境----CentOs安装和配置(一)
- centos hadoop 单机部署环境搭建
- CentOS6.6上hadoop2.2.0集群搭建
- (1)Centos6.5下hadoop1.1.2环境搭建(单机版)
- CentOS6.4上搭建hadoop-2.4.0集群
- WMware 中CentOS系统Hadoop 分布式环境搭建(一)——Hadoop安装环境准备
- hadoop-1.1.0 rpm + centos 6.3 64 + JDK7 搭建全分布式集群的方法
- 用虚拟机在centOS系统搭建hadoop分布式集群(updating...)
- hadoop-1.1.0 rpm + centos 6.3 64虚拟机 + JDK7 搭建分布式集群
- centos x64搭建 hadoop2.4.1 HA
- VBox下CentOS的hadoop伪分布环境的搭建(三)
- hadoop-1.1.0 rpm + centos 6.3 64虚拟机 + JDK7 搭建分布式集群
- centOS下搭建hadoop集群平台。
- hadoop-2.3.0-cdh5.1.0完全分布式搭建(基于centos)
- centos下用exlipse搭建hadoop-2.5.1源码编译环境