[转]分层编译对逃逸分析的影响
2016-11-16 20:25
225 查看
原始链接
client编译速度快,但是所使用的优化较为保守,而server编译速度慢一些,但是使用的优化较为激进。所以client有较好的启动性能,但是server有较好的巅峰性能。那么有没有可能将两者相结合呢?对,这就是分层编译。可以简单的理解为在开始的时候分层编译会使用client编译,当代码运行到一定次数后(可配置)会使用server编译(注意,这里只是便于理解,实际情况并不完全如此)。所以很多应用为了追求很快的启动速度和很高的巅峰性能会选择分层编译。分层编译开启开关是:-server -XX:+TieredCompilation。
在1.8(不包括)之前,分层编译默认是关闭的,所以需要使用上面的开关打开,1.8分层编译成为了默认选项。
那么逃逸分析是什么呢? 简单来说就是动态分析对象的作用域,看看对象是否『逃离』某个范围。比如下面的代码:
这里的User的作用域只局限在test方法内,并没有逃出方法外面。那么如果我们分析出来这点,User对象是没有必要在堆上分配的,在test方法的栈上分配就行了(其实目前Hotspot并没有实现意义上的栈上分配,实际上是标量替换,这里就不深究了),这样test方法执行完毕,User对象所占用的空间就回收了,这对GC简直是大利好。是不是感叹JVM太牛逼了?不过我在测试的时候发现,分层编译对逃逸分析有些影响,下面用例子说明:
从上面的代码看,getAge方法执行了20万次,所以堆中应该有20万个User对象,那么我们如果将堆设置较大,确保运行上面的程序都没有发生GC,是不是能在堆里看到20万个User对象呢? 理论上好像是这样的,那么我们来试试:

嗯,上面就是分层编译对逃逸分析的影响的一个小DEMO,下面附送一个DEMO是:逃逸分析真的这么牛逼? 那么我们关闭逃逸分析看看结果吧(逃逸分析默认是打开的):
看到结果,是不是觉得逃逸分析是有那么点用吧。
那么这个多热算热点呢? 这是通过几个参数来控制的:
-XX:CompileThreshold = 10000 默认是1万,也就是如果方法调用次数或方法内循环次数达到这个阈值就会进行标准编译
-XX:OnStackReplacePercentage = 140
-XX:InterpreterProfilePercentage = 33
InterpreterBackwardBranchLimit = (CompileThreshold * (OnStackReplacePercentage - InterpreterProfilePercentage)) / 100 = 10700
那么这个InterpreterBackwardBranchLimit是什么意思呢?也就是方法执行次数或循环次数超过这个阈值,会进行OSR(On Stack Replacement)形式的编译。OSR是什么意思呢?比如我这个例子中的main方法,这个main方法只执行了一次,这显然远远不够阈值的,但是它里面执行了次数非常多的循环,那OSR编译就是只编译这个循环,然后将其替换,那么下次循环迭代的时候就是执行编译好的代码了。
ok,那么既然这样我们还可以利用这个来验证一下这个CompileThreshold参数,比如我们将这个参数的值下降,那是不是就意味着会提前编译代码呢?那么是不是意味着优化会提前进行,然后堆里的User对象会进一步减少呢?好的,来实验一把。
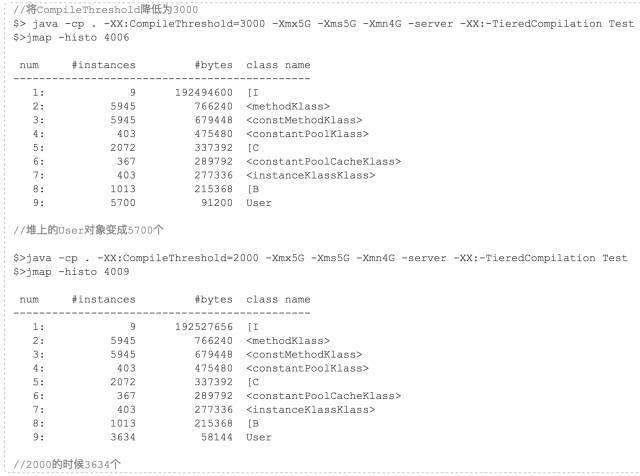
继续往下测试,在我机器中,直到User对象降低到2383个就再也无法降低了,不管如何调低CompileThreshold。我猜测,因为JIT编译是异步的,决定要编译某个代码的时候是先将其放入编译队列,然后由编译线程异步编译,编译完成之后才替换,而决定开始编译到编译完成这段时间怎么着这个循环也要执行2000多次,所以这个无法降低了。我们可以验证一下这个猜测,JVM提供了一个开关,可以关闭异步编译,转成同步编译: -XX:-BackgroundCompilation(默认打开)。

用同步编译,继续将这个参数往下调,我们会发现堆里的User越来越少了。可能有的同学兴奋起来了,这么牛逼,那我是不是可以将这个编译阈值调的很低很低呢?JIT设置这个参数是有道理的,不要随意的修改这个参数:
编译是有成本的,通过前面的例子我们也可以看到差不多2000多次循环的时间和编译这个循环的代码相等,如果代码更复杂,消耗的时间将更多
我们系统中有些代码是频繁执行的,但是有些代码并不频繁执行,对他们进行编译可能不值得,而JIT的参数是通过很多实验得出一个较合理的值。随意降低这个值,会导致大量执行不频繁的代码被编译
编译后的代码要放在CodeCache里,CodeCache的大小也是有限的,如果将一堆执行不频繁的代码放进去了,而最后导致执行频繁的代码不能放进去那就得不偿失了。
JIT简介
JVM JIT有多种选择:client(C1), server(C2), 和两者相结合(C1+C2)。client编译速度快,但是所使用的优化较为保守,而server编译速度慢一些,但是使用的优化较为激进。所以client有较好的启动性能,但是server有较好的巅峰性能。那么有没有可能将两者相结合呢?对,这就是分层编译。可以简单的理解为在开始的时候分层编译会使用client编译,当代码运行到一定次数后(可配置)会使用server编译(注意,这里只是便于理解,实际情况并不完全如此)。所以很多应用为了追求很快的启动速度和很高的巅峰性能会选择分层编译。分层编译开启开关是:-server -XX:+TieredCompilation。
在1.8(不包括)之前,分层编译默认是关闭的,所以需要使用上面的开关打开,1.8分层编译成为了默认选项。
逃逸分析
前面JIT简介里也介绍了JIT会做优化,那么有哪些优化呢? 其中一个就是逃逸分析(准确的说逃逸分析不是优化,只是一个代码分析,不过基于逃逸分析的结果可以做一系列优化,比如:栈上分配,标量替换,锁消除等)。那么逃逸分析是什么呢? 简单来说就是动态分析对象的作用域,看看对象是否『逃离』某个范围。比如下面的代码:
public int test(){
User user = new User();
int age = user.getAge();
return age;
}这里的User的作用域只局限在test方法内,并没有逃出方法外面。那么如果我们分析出来这点,User对象是没有必要在堆上分配的,在test方法的栈上分配就行了(其实目前Hotspot并没有实现意义上的栈上分配,实际上是标量替换,这里就不深究了),这样test方法执行完毕,User对象所占用的空间就回收了,这对GC简直是大利好。是不是感叹JVM太牛逼了?不过我在测试的时候发现,分层编译对逃逸分析有些影响,下面用例子说明:
分层编译对逃逸分析的影响
user.java
public class User{
private final int age;
public User(int age){
this.age = age;
}
public int getAge(){
return this.age;
}
Test.java
public class Test{
private static int getAge(int age){
User u = new User(age);
int i = u.getAge();
return i;
}
public static void main(String[] args)throws Exception{
System.in.read();
int sum = 0;
//先跑10w次,预热
for(int i = 0; i < 100000; i++){
sum += getAge(i);
}
System.out.println(sum);
//等待, 等jit优化
Thread.sleep(3000);
for(int n = 0; i < 100000; n++){
sum += getAge(n);
}
System.out.println(sum);
System.in.read();
}从上面的代码看,getAge方法执行了20万次,所以堆中应该有20万个User对象,那么我们如果将堆设置较大,确保运行上面的程序都没有发生GC,是不是能在堆里看到20万个User对象呢? 理论上好像是这样的,那么我们来试试:
嗯,上面就是分层编译对逃逸分析的影响的一个小DEMO,下面附送一个DEMO是:逃逸分析真的这么牛逼? 那么我们关闭逃逸分析看看结果吧(逃逸分析默认是打开的):
看到结果,是不是觉得逃逸分析是有那么点用吧。
编译阈值
那么有同学问,不是有逃逸分析么,为啥还剩下一万多个对象啊。其实这从jvm的名字可以看出来(hotspot),也就是JIT是对跑热了的代码才会优化的,不是代码执行第一遍就开始编译的,那成本太高了,只有跑了一定次数之后才开始,而且jvm也需要依靠这个预热截断收集各种数据,作为优化的决策,所以还没有预热完成的时候还是会在堆上分配User对象的。那么这个多热算热点呢? 这是通过几个参数来控制的:
-XX:CompileThreshold = 10000 默认是1万,也就是如果方法调用次数或方法内循环次数达到这个阈值就会进行标准编译
-XX:OnStackReplacePercentage = 140
-XX:InterpreterProfilePercentage = 33
InterpreterBackwardBranchLimit = (CompileThreshold * (OnStackReplacePercentage - InterpreterProfilePercentage)) / 100 = 10700
那么这个InterpreterBackwardBranchLimit是什么意思呢?也就是方法执行次数或循环次数超过这个阈值,会进行OSR(On Stack Replacement)形式的编译。OSR是什么意思呢?比如我这个例子中的main方法,这个main方法只执行了一次,这显然远远不够阈值的,但是它里面执行了次数非常多的循环,那OSR编译就是只编译这个循环,然后将其替换,那么下次循环迭代的时候就是执行编译好的代码了。
ok,那么既然这样我们还可以利用这个来验证一下这个CompileThreshold参数,比如我们将这个参数的值下降,那是不是就意味着会提前编译代码呢?那么是不是意味着优化会提前进行,然后堆里的User对象会进一步减少呢?好的,来实验一把。
继续往下测试,在我机器中,直到User对象降低到2383个就再也无法降低了,不管如何调低CompileThreshold。我猜测,因为JIT编译是异步的,决定要编译某个代码的时候是先将其放入编译队列,然后由编译线程异步编译,编译完成之后才替换,而决定开始编译到编译完成这段时间怎么着这个循环也要执行2000多次,所以这个无法降低了。我们可以验证一下这个猜测,JVM提供了一个开关,可以关闭异步编译,转成同步编译: -XX:-BackgroundCompilation(默认打开)。
用同步编译,继续将这个参数往下调,我们会发现堆里的User越来越少了。可能有的同学兴奋起来了,这么牛逼,那我是不是可以将这个编译阈值调的很低很低呢?JIT设置这个参数是有道理的,不要随意的修改这个参数:
编译是有成本的,通过前面的例子我们也可以看到差不多2000多次循环的时间和编译这个循环的代码相等,如果代码更复杂,消耗的时间将更多
我们系统中有些代码是频繁执行的,但是有些代码并不频繁执行,对他们进行编译可能不值得,而JIT的参数是通过很多实验得出一个较合理的值。随意降低这个值,会导致大量执行不频繁的代码被编译
编译后的代码要放在CodeCache里,CodeCache的大小也是有限的,如果将一堆执行不频繁的代码放进去了,而最后导致执行频繁的代码不能放进去那就得不偿失了。

相关文章推荐
- Java即时编译和逃逸分析
- 深入分析JVM逃逸分析对性能的影响
- Android SQLiteStatement 编译、执行 分析
- JVM 之 逃逸分析和TLAB
- JVM中启用逃逸分析
- Android源代码编译命令m/mm/mmm/make分析
- Android_应用程序资源的编译和打包过程分析
- uboot编译过程完全分析
- Android7.0 编译系统流程分析
- Impala 编译测试脚本分析
- 第十四期 AOSP 编译系统分析《手机就是开发板》
- 我对目前金融危机的认识和影响分析(一)
- SPEC2000程序编译和性能热点分析
- java基础-finally块对return变量的影响分析
- 影响Email营销效果的因素分析
- Linux 学习笔记_13_2_LAMP环境编译(下) --编译过程及分析
- 内核编译init脚本调用mountroot()函数分析
- Linux程序编译执行原理之一:预处理-编译-汇编-链接过程分析
- 为分析影响Linux实时性构建的任务响应模型
- Andoird编译系统分析(一)