python爬虫——图片下载
2016-11-15 10:03
363 查看
转载自http://www.cnblogs.com/voidsky/p/5490800.html
原文是在win系统下实现的,在此我在ubuntu14.04中实现了一下:
主要定义了一个脚本picdown.py,并采用re与requests模块实现
picdown.py
执行脚本文件,输入刘亦菲;
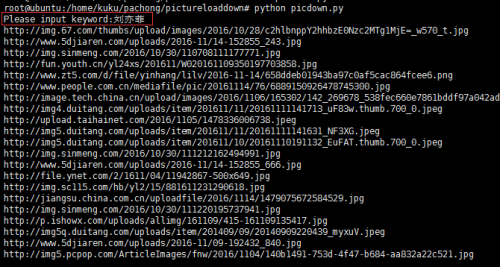
查看下载的文件
原文是在win系统下实现的,在此我在ubuntu14.04中实现了一下:
主要定义了一个脚本picdown.py,并采用re与requests模块实现
picdown.py
#-*- coding:utf-8 -*-
import re
import requests
def picdown():
word = raw_input('Please input keyword:')
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word='+word+'&ct=201326592&v=flip'
html = requests.get(url).text
#查找所有以objURL开始的字段,re.S表示让”.”可以匹配换行符,
#不然有些标签头和尾是分几行的,就会匹配失败
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
i = 0
for each in pic_url:
print each
try:
pic= requests.get(each, timeout=10)#请求超时
except requests.exceptions.ConnectionError:
print '[错误]当前图片无法下载'
continue
string = './picture/'+str(i) + '.jpg'#保存文件在当前目录下的picture文件夹中
fp = open(string,'wb')
fp.write(pic.content)
fp.close()
i += 1
if __name__=='__main__':
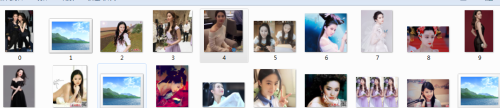
picdown()结果如下:执行脚本文件,输入刘亦菲;
查看下载的文件

相关文章推荐
- python 百度贴吧爬虫(下载图片)
- 我的第一个python爬虫程序(从百度贴吧自动下载图片)
- 每天一篇python:简单爬虫下载图片篇
- Python简单知乎爬虫--爬取页面的图片并下载到本地
- Python 爬虫5——爬取并下载网页指定规格的图片
- Python 爬虫学习 网页图片下载
- python爬虫 分页获取图片并下载
- Python爬虫下载网站上的图片到本地
- Python 3 爬虫之批量下载字帖图片
- Python3 爬虫下载指定页面图片
- python爬虫图片下载
- python实现爬虫下载美女图片
- [python][爬虫]从网页中下载图片
- python爬虫(1)下载任意网页图片
- python中使用网络爬虫下载图片
- python 爬虫学习<将某一页的所有图片下载下来>
- python实现爬虫下载美女图片
- python实现爬虫下载美女图片
- Python 爬虫5——爬取并下载网页指定规格的图片
- python爬虫框架scrapy学习图片下载