决策树学习笔记
2016-11-05 19:15
155 查看
算法描述
输入
{(x_i,y_i )}, 样本个数为m, X∈R^n,Y∈{0,1},即X一共有n个属性,Y的值只有0或1,代表是分类“0”标签,还是分类“1”
输出
决策树
示例数据集
(数据来自《机器学习》(周志华著)书中的例子):
说明
数据集大小为17X7每一列为数据集的特征,列头为特征标签,具体内容为特征值,例如第一列,列头为”色泽”,而”浅绿””乌黑”等为特征值。最后一列为类别,1代表是好瓜,0代表是坏瓜,本示例中只有两个类别,也可以有多个类别。
计算过程
首先计算全体数据集的信息熵,信息熵是根据香农定理计算出来的,可以简单理解为一个数据集的信息量有多少(用二进制来衡量),整体数据集的信息熵计算,可以先计算两个类别的概率,然后运用香农定理求出
设整体数据集为D
P(好瓜=1)=8/17
P(好瓜=0)=9/17
所以熵为
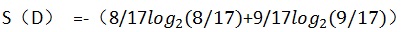
构造决策树的过程,也就是按某个特征极其特征值划分数据集的过程,划分后的数据集,包含的正例和反例尽量的明确,其实也就是划分后的数据子集的信息量降低,也可以称为纯度提高。因此就要计算按照哪个特征属性划分数据集后,数据集的含量降低得多,因此需要分别计算色泽、根蒂、敲声、纹理、脐部、触感,这六个属性划分后哪个信息量降低的最多。如果按色泽划分数据集则,则需要按色泽里面的属性值划分数据集,然后再算子集的信息熵:
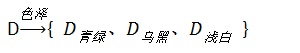
然后算
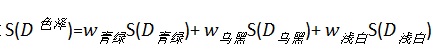
其中,权重w_0=C(D_青绿)/C(D),是按特征=青绿的样本个数除以样本个数,进行权重分配
计算信息增益
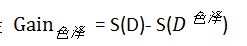
依以上步骤,再相继计算Gain_根蒂 、Gain_敲声 、Gain_纹理 、Gain_脐部 、Gain_触感 、
并且取最大值 Gain = max{Gain_根蒂 、Gain_敲声 、Gain_纹理 、Gain_脐部 、Gain_触感}
经过上一部计算后,发现信息增益最大的是纹理,所以决策树的第一个分类结点诞生了,就是纹理,
接下来,需要在第一步划分的结果上,重新整理数据集,将D按照纹理=清晰、纹理=模糊、纹理=稍糊,划分为三个数据子集
D_(纹理=清晰) :
D_(纹理=稍糊)
D_(纹理=模糊)
同时还要将这些数据子集中的纹理列要删除(即上述数据集中加粗的),代表已经按纹理属性进行过决策,不需要在子集中再决策,所以这些数据子集的列数是6(包含最后一列的分类标签类),行数相加为17,
接下来再为这三个数据子集运用上面寻找子集中最优的属性划分数据集的方法递归执行。
递归执行的结束条件(即产生叶子结点的条件):
当数据集中的类别一列只有一个类别全是相同类,比如数据集中的好瓜一列值都为0或都为1
当数据集中所有的列都划分过数据集了,数据集已经剩最后一列标签列的时候,则取标签列中标签值占比最的类别为最终的分类属性
主程序
运行结果

输入
{(x_i,y_i )}, 样本个数为m, X∈R^n,Y∈{0,1},即X一共有n个属性,Y的值只有0或1,代表是分类“0”标签,还是分类“1”
输出
决策树
示例数据集
(数据来自《机器学习》(周志华著)书中的例子):
| 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
|---|---|---|---|---|---|---|
| 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 1 |
| 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 1 |
| 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 1 |
| 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 1 |
| 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 1 |
| 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 1 |
| 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 1 |
| 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 1 |
| 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0 |
| 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 0 |
| 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 0 |
| 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 0 |
| 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 0 |
| 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 0 |
| 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0 |
| 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 0 |
| 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0 |
数据集大小为17X7每一列为数据集的特征,列头为特征标签,具体内容为特征值,例如第一列,列头为”色泽”,而”浅绿””乌黑”等为特征值。最后一列为类别,1代表是好瓜,0代表是坏瓜,本示例中只有两个类别,也可以有多个类别。
计算过程
首先计算全体数据集的信息熵,信息熵是根据香农定理计算出来的,可以简单理解为一个数据集的信息量有多少(用二进制来衡量),整体数据集的信息熵计算,可以先计算两个类别的概率,然后运用香农定理求出
设整体数据集为D
P(好瓜=1)=8/17
P(好瓜=0)=9/17
所以熵为
构造决策树的过程,也就是按某个特征极其特征值划分数据集的过程,划分后的数据集,包含的正例和反例尽量的明确,其实也就是划分后的数据子集的信息量降低,也可以称为纯度提高。因此就要计算按照哪个特征属性划分数据集后,数据集的含量降低得多,因此需要分别计算色泽、根蒂、敲声、纹理、脐部、触感,这六个属性划分后哪个信息量降低的最多。如果按色泽划分数据集则,则需要按色泽里面的属性值划分数据集,然后再算子集的信息熵:
然后算
其中,权重w_0=C(D_青绿)/C(D),是按特征=青绿的样本个数除以样本个数,进行权重分配
计算信息增益
依以上步骤,再相继计算Gain_根蒂 、Gain_敲声 、Gain_纹理 、Gain_脐部 、Gain_触感 、
并且取最大值 Gain = max{Gain_根蒂 、Gain_敲声 、Gain_纹理 、Gain_脐部 、Gain_触感}
经过上一部计算后,发现信息增益最大的是纹理,所以决策树的第一个分类结点诞生了,就是纹理,
接下来,需要在第一步划分的结果上,重新整理数据集,将D按照纹理=清晰、纹理=模糊、纹理=稍糊,划分为三个数据子集
D_(纹理=清晰) :
| 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
|---|---|---|---|---|---|---|
| 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 1 |
| 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 1 |
| 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 1 |
| 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 1 |
| 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 1 |
| 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 1 |
| 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 1 |
| 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 0 |
| 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0 |
| 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
|---|---|---|---|---|---|---|
| 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 1 |
| 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0 |
| 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 0 |
| 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 0 |
| 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0 |
| 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
|---|---|---|---|---|---|---|
| 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 0 |
| 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 0 |
| 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 0 |
接下来再为这三个数据子集运用上面寻找子集中最优的属性划分数据集的方法递归执行。
递归执行的结束条件(即产生叶子结点的条件):
当数据集中的类别一列只有一个类别全是相同类,比如数据集中的好瓜一列值都为0或都为1
当数据集中所有的列都划分过数据集了,数据集已经剩最后一列标签列的时候,则取标签列中标签值占比最的类别为最终的分类属性
代码实现
代码实现参考了《机器学习实战》一书中的python代码主程序
# -*- coding: utf-8 -*-
import train
from numpy import shape
if __name__ == '__main__':
dataArr,featureLabels = train.loadDataSet("data.txt")
tree=train.buildDecisionTree(dataArr, featureLabels)
train.showPictureByLevel(tree)
Train模块下的代码:
# -*- coding: utf-8 -*-
from math import log
import operator
#1.
#返回属性集及属性列list
def loadDataSet(fineName):
dataArray=[]
fr=open(fineName)
for line in fr.readlines():
curlLine=line.strip().split('\t')
dataArray.append(curlLine)
fr.close()
featureLabels=dataArray[0][0:-1]
dataArray=dataArray[1:]
return dataArray, featureLabels
#根据属性值,算出信息熵
#假设标签项有正负两项,则先把dataMat有多少行是正项,多少是负项计算出来,然后求概率和,就是香农值了
#求熵是= -正例概率×log(正例概率,2)-负例概率×log(负例概率,2),如果还有除正负例以外的类别,还要继续减
def caculateShang(dataArr):
labelCount={}
m=len(dataArr)
shang=0.0
for dataVec in dataArr:
#最后一列存的是类别值,例如正例为1,负例为0
label=dataVec[-1]
#key值为类别标签,如正例为1,负例为0,值为标签为此值的行数
if label not in labelCount.keys():
labelCount[label]=0
labelCount[label]+=1
for eachLabel in labelCount.keys():
prob=labelCount[eachLabel]/float(m)
shang-=prob*log(prob,2)
return shang
#选择最好的特征
def chooseBestFeatureToSplit(dataArr):
#求特征列数,要减1,因为有一列是标签列,并不是属性列
featureNums = len(dataArr[0])-1
totalShann=caculateShang(dataArr)
gainShann=0.0
bestFeature=-1
#按属性划分数据集
for i in range(featureNums):
#求第i列所有特征的值
featureValues=[each[i] for each in dataArr]
uniqFeaValues = set(featureValues)
newShann=0.0
#按每个特征值,划分数据集,求香农熵
for eachFeaValue in uniqFeaValues:
#将第i特征列中,按照特征值为eachFeaValue划分数据集
subData = splitDataSet(dataArr, i, eachFeaValue)
prob = len(subData)/float(len(dataArr))
#计算上一步划分出来的子集的香农熵,prob是权重值,代表数据集越多的集合,权值越大
newShann +=prob*caculateShang(subData)
#计算信息增益,选择信息增益差最大的属性划分方法
if gainShann<totalShann-newShann:
gainShann = totalShann-newShann
bestFeature=i
#返回信息增益最大的特征列
return bestFeature
#划分数据集,将特征列为featureAxis,并且特征值为featureValue的行,划到一个数据集中,并且去除特征值得到子集D,目的是为了计算子集D的熵
def splitDataSet(dataArr,featureAxis,featureValue):
subDataArr=[]
for eachVec in dataArr:
if eachVec[featureAxis]==featureValue:
subData = eachVec[:featureAxis]
subData.extend(eachVec[featureAxis+1:])
subDataArr.append(subData)
return subDataArr
#构建决策树 featureLabels为特征标签
def buildDecisionTree(dataArr,featureLabels):
#classList为分类,是数据集的最后一列值组成的list
classList = [each[-1] for each in dataArr]
#所有类别值都一致,返回叶子结点,即归属的类别值
if classList.count(classList[0])==len(classList):
return classList[0]
#只剩下一列值的情况,返回该值里面归属类别最多的类别
if len (dataArr[0])==1:
return majorityClass(classList)
#bestFeature是列数下标
bestFeature = chooseBestFeatureToSplit(dataArr)
bestFeatureLabel = featureLabels[bestFeature]
myTree={bestFeatureLabel:{}}
del(featureLabels[bestFeature])
bestFeatureValues = [each[bestFeature] for each in dataArr]
#求最佳特征列中特征值,去重
uniqValues = set(bestFeatureValues)
for eachValue in uniqValues:
subLabels=featureLabels[:]#copy
subDataArr = splitDataSet(dataArr,bestFeature,eachValue)
myTree[bestFeatureLabel][eachValue]=buildDecisionTree(subDataArr,subLabels)
return myTree
#分类
def majorityClass(classList):
classCount={}
for each in classList:
if each not in classCount.keys():
classCount[each]=0
classCount[each]+=1
#对字典进行排序
sortedClass= sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
return sortedClass[0][0]
#显示树
def showPictureByLevel(tree,i=0):
i+=1
if type(tree).__name__!='dict':
print ((i-1)*"\t")+"----"+tree
return
else:
for key in tree.keys():
print ((i-1)*"\t")+"|---"+ key
showPictureByLevel(tree[key],i)
return运行结果

相关文章推荐
- 决策树学习笔记
- Kaldi决策树状态绑定学习笔记(四)
- 决策树 学习笔记
- 决策树学习笔记整理
- 机器学习入门学习笔记:(3.2)ID3决策树程序实现
- Kaldi决策树状态绑定学习笔记
- 决策树学习笔记整理
- Spark MLlib 入门学习笔记 - 决策树
- 决策树学习笔记整理(转载)
- 深度学习*学习笔记-----之决策树(1)
- 统计学习笔记(五)决策树
- 决策树学习笔记
- 阅读笔记-机器学习-第3章-决策树学习
- 【ML学习笔记】24:白皮书ID3决策树的注解
- 机器学习笔记——决策树学习
- Kaldi决策树状态绑定学习笔记(一)
- 《机器学习实战》学习笔记---决策树
- 《统计机器学习》-决策树学习笔记
- 《统计学习方法》第五章决策树学习笔记
- 机器学习笔记——决策树学习