企业级HBase集群搭建
2016-11-04 08:16
239 查看
参考HBase的基本原理,本次实验在配置好的Hadoop HA集群之上,将HMaster服务部署在HDFS的namenode1和namenode2节点,将RegionServer部署在datanode节点,使用独立的ZooKeeper集群进行搭建。
1. 查看系统的最大文件打开数和最大进程数
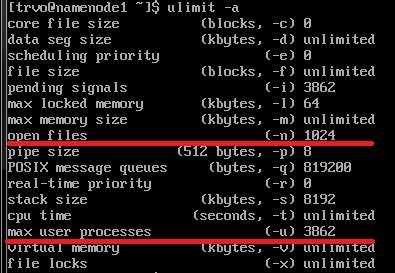
2. 打开/etc/security/limits.conf文件,添加如下内容
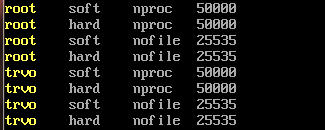
3. 打开/etc/sysctl.conf文件,修改Linux内核参数
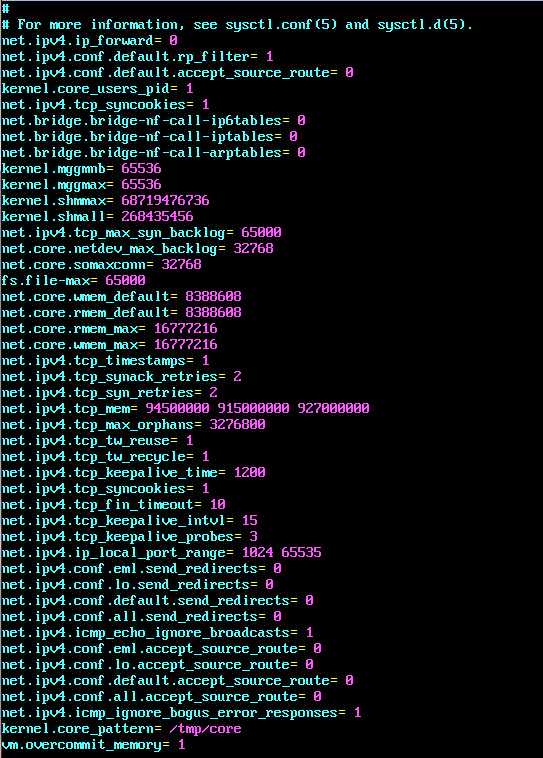

2. 解压缩、移动hbase文件夹到~/apache/hbase
3. 在集群各节点上修改用户环境变量

4. 进入hbase的conf文件夹,设置hbase-site.xml
5. 修改hbase-env.sh
6. 修改regionservers文件
datanode
7. 新建backup-masters文件
namenode2
8. 返回hbase主目录,创建相关文件夹
$mkdir tmp
$mkdir pids
$mkdir logs
9. 将hbase工作目录同步到集群其它节点
$scp -r /home/trvo/apache/hbase trvo@namenode2:/home/trvo/apache/
$scp -r /home/trvo/apache/hbase trvo@datanode:/home/trvo/apache/
$zkServer.sh start
2. 在namenode1上启动hadoop
$start-all.sh
3. 启动YARN的另一个ResourceManager
$yarn-daemon.sh start resourcemanager
4. 在namenode1上启动hbase
$start-hbase.sh
5. 进入Web UI,查看主Master状态
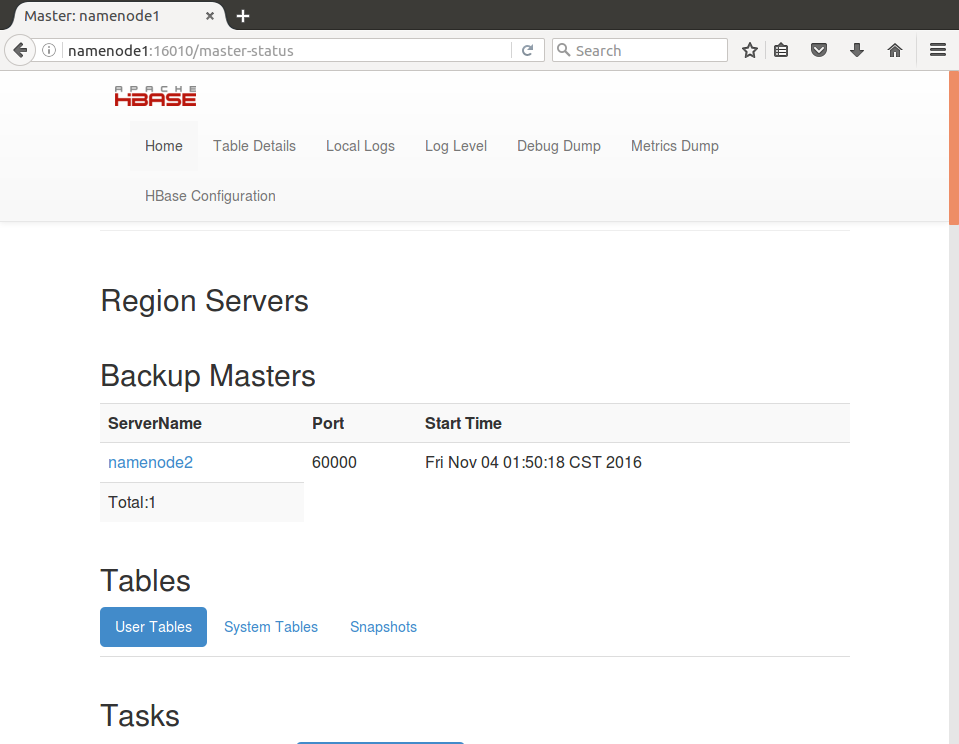
6. 查看备份Master状态
一、配置Linux系统
针对企业级的应用场合,需要修改Linux系统的部分参数,主要是以下几点。1. 查看系统的最大文件打开数和最大进程数
2. 打开/etc/security/limits.conf文件,添加如下内容
3. 打开/etc/sysctl.conf文件,修改Linux内核参数
二、配置HBase
1. 获取hbase压缩包2. 解压缩、移动hbase文件夹到~/apache/hbase
3. 在集群各节点上修改用户环境变量
4. 进入hbase的conf文件夹,设置hbase-site.xml
<configuration> <!-- 设置HRegionServers共享目录 --> <property> <name>hbase.rootdir</name> <value>hdfs://mycluster/hbase</value> </property> <!-- 设置HMaster的rpc端口 --> <property> <name>hbase.master.port</name> <value>16000</value> </property> <!-- 设置HMaster的http端口 --> <property> <name>hbase.master.info.port</name> <value>16010</value> </property> <!-- 指定缓存文件存储的路径 --> <property> <name>hbase.tmp.dir</name> <value>/home/trvo/apache/hbase/tmp</value> </property> <!-- 开启分布式模式 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 指定ZooKeeper集群位置 --> <property> <name>hbase.zookeeper.quorum</name> <value>namenode1, namenode2, datanode</value> </property> <!-- 指定ZooKeeper集群端口 --> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property> <!--指定Zookeeper数据目录,需要与ZooKeeper集群上配置相一致 --> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/trvo/apache/zookeeper/data</value> </property> <!-- \\\\\\\\\\以下为优化配置项\\\\\\\\\\ --> <!-- 关闭分布式日志拆分 --> <property> <name>hbase.master.distributed.log.splitting</name> <value>false</value> </property> <!-- hbase客户端rpc扫描一次获取的行数 --> <property> <name>hbase.client.scanner.caching</name> <value>2000</value> </property> <!-- HRegion分裂前最大的文件大小(10G) --> <property> <name>hbase.hregion.max.filesize</name> <value>10737418240</value> </property> <!-- HRegionServer中最大的region数量 --> <property> <name>hbase.regionserver.reginoSplitLimit</name> <value>2000</value> </property> <!-- StoreFile的个数超过这个数就开始合并 --> <property> <name>hbase.hstore.compactionThreshold</name> <value>6</value> </property> <!-- 当某一个region的storefile个数达到该值则block写入,等待compact --> <property> <name>hbase.hstore.blockingStoreFiles</name> <value>14</value> </property> <!-- 超过memstore大小的倍数达到该值则block所有写入请求,自我保护 --> <property> <name>hbase.hregion.memstore.block.multiplier</name> <value>20</value> </property> <!-- service工作的sleep间隔 --> <property> <name>hbase.server.thread.wakefrequency</name> <value>500</value> </property> <!-- ZooKeeper客户端同时访问的并发连接数 --> <property> <name>hbase.zookeeper.property.maxClientCnxns</name> <value>2000</value> </property> <!-- 根据业务情况进行配置 --> <property> <name>hbase.regionserver.global.memstore.lowerLimit</name> <value>0.3</value> </property> <property> <name>hbase.regionserver.global.memstore.upperLimit</name> <value>0.39</value> </property> <property> <name>hbase.block.cache.size</name> <value>0.4</value> </property> <!-- RegionServer的请求处理IO线程数 --> <property> <name>hbase.reginoserver.handler.count</name> <value>300</value> </property> <!-- 客户端最大重试次数 --> <property> <name>hbase.client.retries.number</name> <value>5</value> </property> <!-- 客户端重试的休眠时间 --> <property> <name>hbase.client.pause</name> <value>100</value> </property> </configuration>
5. 修改hbase-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk <
9e1a
span class="hljs-comment">//设置jdk的路径
export HADOOP_HOME=/home/trvo/apache/hadoop // 设置hadoop安装路径
export HBASE_HEAPSIZE=1024 // 设置HBase内存堆的大小
export HBASE_LOG_DIR=${HBASE_HOME}/logs //设置HBase的日志目录
export HBASE_PID_DIR=/home/trvo/apache/hbase/pids
export HBASE_MANAGES_ZK=false //选用独立的zookeeper集群6. 修改regionservers文件
datanode
7. 新建backup-masters文件
namenode2
8. 返回hbase主目录,创建相关文件夹
$mkdir tmp
$mkdir pids
$mkdir logs
9. 将hbase工作目录同步到集群其它节点
$scp -r /home/trvo/apache/hbase trvo@namenode2:/home/trvo/apache/
$scp -r /home/trvo/apache/hbase trvo@datanode:/home/trvo/apache/
三、启动HBase
1. 在集群各节点上启动zookeeper$zkServer.sh start
2. 在namenode1上启动hadoop
$start-all.sh
3. 启动YARN的另一个ResourceManager
$yarn-daemon.sh start resourcemanager
4. 在namenode1上启动hbase
$start-hbase.sh
5. 进入Web UI,查看主Master状态
6. 查看备份Master状态

相关文章推荐
- Hbase 集群搭建 干货
- 搭建企业级高可用HBase
- 搭建hbase-0.94.26集群环境
- hbase学习01-集群搭建
- hbase集群搭建
- HBASE集群搭建
- Hadoop分布式 之 Hbase集群搭建
- HBase集群搭建
- Hbase的集群搭建
- 搭建hbase-0.94.26集群环境
- [笔记]Hbase入门集群搭建
- Hadoop集群搭建(hadoop+zookeeper+hbase)Ubuntu14.04
- Hadoop及Hbase集群搭建
- 在原有的hbase集群中搭建一个新的hbase集群
- Ubuntu 16.10 搭建 hbase 1.2.5 完全集群
- Hadoop-2.6.0+Zookeeper-3.4.6+Spark-1.5.0+Hbase-1.1.2+Hive-1.2.0集群搭建
- 轻松搭建hadoop-1.2.1集群(5)—配置HBase集群
- 高可用Hadoop平台-HBase集群搭建
- Hadoop2.7.0学习——Hbase-0.98.13集群搭建
- 利用ambari搭建hadoop、hbase集群