利用Python进行数据分析系列之——数据格式转换
2016-11-04 01:43
405 查看
待我学有所成,结发与蕊可好。@夏瑾墨 by Jooey
需求:将
在数据可视化中,OD弦图要求以百分比的输入格式,也可以用具体的客流数值,但是需要修改一下绘图的js脚本。由于目前数据处理的结果主要是二维表形式的csv,与弦图要求的输入格式不一致,所以这里按照需求先进行额外的数据格式转换,OD_Matrix_Weekday_BusyHourAM.json 是站点之间的OD流量,这个例子json文件中每一行表示该站点到其他各个站点的客流占总客流的百分百,所以都是很小的数值。

json数据格式:二维数据,且每个数值为改站点对之间客流所占的百分百。
进行格式转换:从二维表–>二维数组

实现:下面讲方法:
在同一文件路径下,执行以下命令完成数据转换:
涉及的相关背景知识总结:
1.CSV模块是Python的内置模块,
就可以调用,CSV模块主要就两个函数:csv.reader()——读取csv文件数据,csv.writer()——写入csv文件数据。csv产生的数据都是字符串类型的,它不会做任何其他类型的转换。
2. use “\t” for delimiter 进行分界
3. 数据结构的推导式(List comprehension),也叫列表的解析式。比如现在我有41个元素要装进列表中,普通的写法是这样的:
下面换成列表解析的方式来写:
后者执行效率高,我们用
1.列表推导式的用法:
2.字典推导式用法:
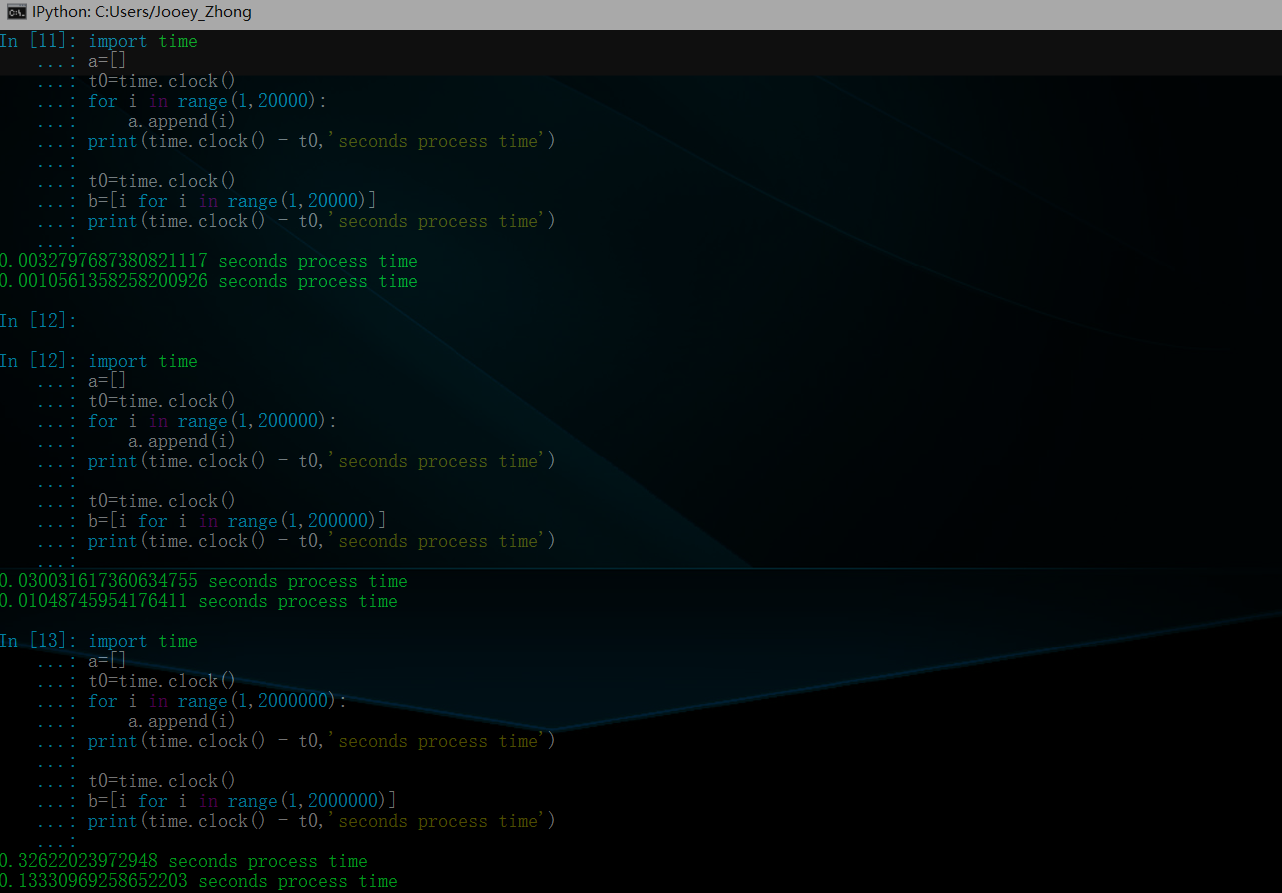
3.用来衡量比较这两种方式程序的耗时
得到结果:
参考资料
1.Python3-cookbook6.1 读写CSV数据
http://python3-cookbook.readthedocs.io/zh_CN/latest/c06/p01_read_write_csv_data.html
2.Python学习笔记——csv模块读写数据
http://www.360doc.com/content/14/0707/10/16740871_392565773.shtml
3.python: import csv file (delimiter “;” or “,”)
http://stackoverflow.com/questions/16312104/python-import-csv-file-delimiter-or
需求:将
OD_Matrix_Weekday_BusyHourAM.csv转换成
OD_Matrix_Weekday_BusyHourAM.json。
在数据可视化中,OD弦图要求以百分比的输入格式,也可以用具体的客流数值,但是需要修改一下绘图的js脚本。由于目前数据处理的结果主要是二维表形式的csv,与弦图要求的输入格式不一致,所以这里按照需求先进行额外的数据格式转换,OD_Matrix_Weekday_BusyHourAM.json 是站点之间的OD流量,这个例子json文件中每一行表示该站点到其他各个站点的客流占总客流的百分百,所以都是很小的数值。
json数据格式:二维数据,且每个数值为改站点对之间客流所占的百分百。
进行格式转换:从二维表–>二维数组
实现:下面讲方法:
#List.py 数据格式转换的python脚本
import sys #导入系统相关的信息模块
import csv #导入csv模块读取写入csv文件数据
myList = [([0] * 42) for i in range(42)] #定义一个列表
x=0
y=0
sum = 0
with open(sys.argv[1]) as f: #使用sys.argv[0]采集脚本名称
f_tsv = csv.reader(f, delimiter='\t') #读取csv文件
headers = next(f_tsv)
for row in f_tsv:
x = int(row[0]) #使用下标访问myList列表的第1个字段
y = int(row[1]) #使用下标访问myList列表的第2个字段
if x > 30 :
x = x-10
if y > 30 :
y = y -10
myList[x-1][y-1]=row[2]
sum = sum + int(row[2])
#print ("%f",myList)
for i in range(42):
for j in range(42):
#myList[i][j]='{0:.10f}'.format(float(myList[i][j])/sum)
myList[i][j]=(float(myList[i][j])/sum) #输出浮点型
print myList在同一文件路径下,执行以下命令完成数据转换:
python list.py OD_Matrix_Weekday_BusyHourAM.csv >OD_Matrix_Weekday_BusyHourAM.json
涉及的相关背景知识总结:
1.CSV模块是Python的内置模块,
Import csv
就可以调用,CSV模块主要就两个函数:csv.reader()——读取csv文件数据,csv.writer()——写入csv文件数据。csv产生的数据都是字符串类型的,它不会做任何其他类型的转换。
2. use “\t” for delimiter 进行分界
3. 数据结构的推导式(List comprehension),也叫列表的解析式。比如现在我有41个元素要装进列表中,普通的写法是这样的:
a=[] for i in range(1,42): a.append(i)
下面换成列表解析的方式来写:
a = [i in range(1,42)]
后者执行效率高,我们用
time clock()方法,以浮点数计算的秒数返回当前的CPU时间。用来衡量不同程序的耗时,比time.time()更好用。但是这里有一点要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是”进程时间”,它是用秒表示的浮点数(时间戳)。而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行时间。(实际上是以WIN32上QueryPerformanceCounter()为基础,它比毫秒表示更为精确)
1.列表推导式的用法:
List=[item for item in iterable] a=[i**2 for in range(1,10)] b=[j+i for j in range(1,10)] k=[n for n in range(1,10) if n % 2==0] z=[letter.lower() for letter in 'ABCDEFGH']
2.字典推导式用法:
d={i:i+1 for in range(4)}
g={i:j for i,j in zip(range(1,6),'abcde')}
g={i:j.upper() for i,j in range(1,6),abcde''}3.用来衡量比较这两种方式程序的耗时
import time a=[] t0=time.clock() for i in range(1,2000000): a.append(i) print(time.clock() - t0,'seconds process time') t0=time.clock() b=[i for i in range(1,2000000)] print(time.clock() - t0,'seconds process time')
得到结果:
参考资料
1.Python3-cookbook6.1 读写CSV数据
http://python3-cookbook.readthedocs.io/zh_CN/latest/c06/p01_read_write_csv_data.html
2.Python学习笔记——csv模块读写数据
http://www.360doc.com/content/14/0707/10/16740871_392565773.shtml
3.python: import csv file (delimiter “;” or “,”)
http://stackoverflow.com/questions/16312104/python-import-csv-file-delimiter-or

相关文章推荐
- 利用Python进行数据分析 基础系列随笔汇总
- 《利用Python 进行数据分析》 - 笔记(3)
- 利用python进行数据分析之pandas库的应用(一)
- 利用Python进行数据分析--数据聚合与分组运算
- [python和大数据-1]利用爬虫登录知乎进行BFS搜索抓取用户信息本地mysql分析【PART1】
- 利用Python进行数据分析--数据聚合与分组运算1
- 利用python进行数据分析之数据聚合和分组运算
- 利用Python进行数据分析--数据加载、存储与文件格式
- 《利用Python 进行数据分析》 - 笔记(2)
- 利用python进行数据分析之绘图和可视化
- 利用Python进行数据分析——准备工作篇
- linux下利用python进行数据分析(1)Anaconda 安装
- 《利用python 进行数据分析》要点记录
- 利用Python进行数据分析--数据规整化:清理、转换、合并、重塑
- 利用Python进行数据分析——时间序列[十](1) .
- 利用Python进行数据分析--时间序列
- 利用Python进行数据分析——第一章:重要Python库安装配置
- 利用Python进行数据分析——数据规整化:清理、转换、合并、重塑(七)(1)
- 利用Python进行数据分析--绘图和可视化
- 利用Python进行数据导入、变化、统计和假设检验等基本数据分析