几种计算机视觉中常用的聚类算法(K-means, Agglomerative clustering, Mean shift, Spectral clustering)
2016-11-03 16:39
471 查看
前言:计算机视觉是让计算机理解图像与视频,本系列博客的目的在于加深自己在学习计算机视觉过程中对相关知识理解与回顾。其中很多内容参照:教材《ComputerVision:
Algorithms and Applications》,教材《Learning
Image Processing with OpenCV》工具书《LearningOpenCV》,国外大学的课程《Computer
Vision》和课程《Computer
Vision》。
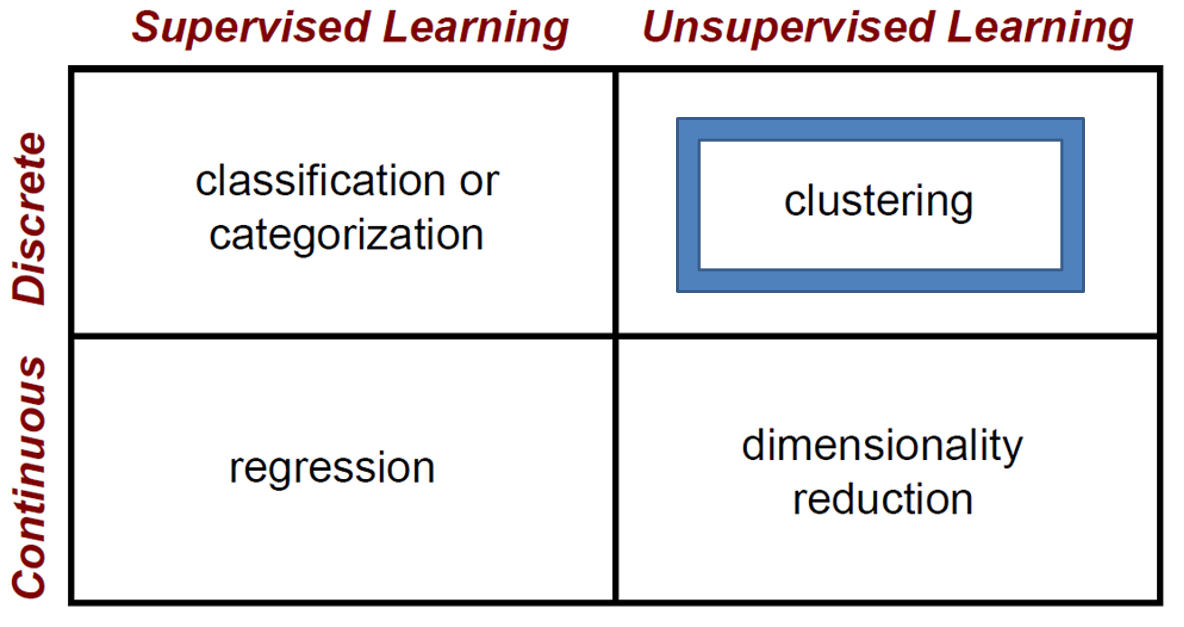
对于机器学习而言,聚类常常应用于离散情况下的非监督学习算法之中,如下图所示。
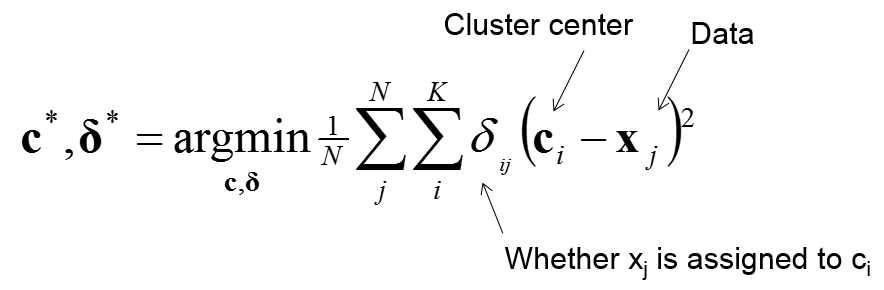
聚类的总体目标是使得最小化目标函数:
聚类的方法很多,常用的包括(K-means, Agglomerative clustering,mean shift, Spectral clustering)。
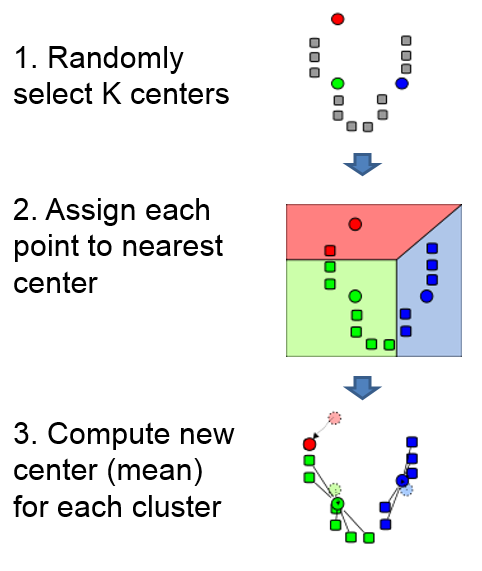
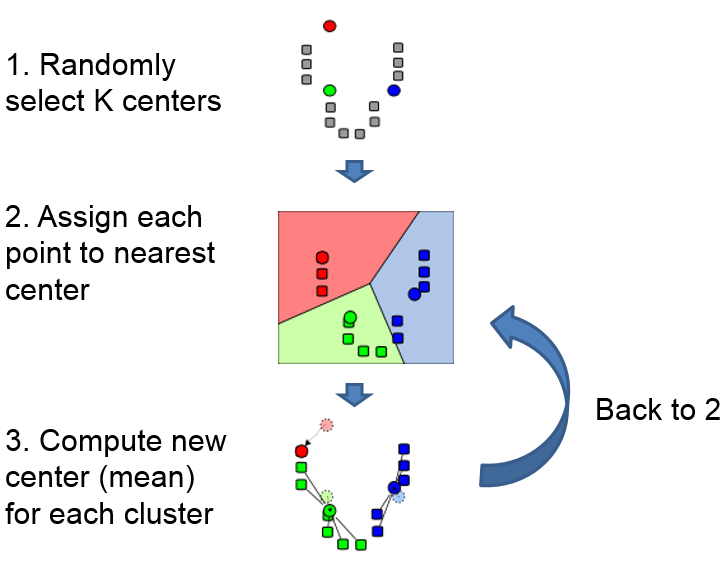
1. K-means
核心思想为迭代的指定点到最近的聚类中心。聚类算法会收敛到局部极小值。
算法的有点包括:
l 简单快速(不针对大型的聚类问题)
l 容易实现
l 能很好的表示数据
缺点包括
l 需要设定k
l 对outliers很敏感
l 收敛到局部极小值
l 对于大型的聚类问题,其算法复杂度较高,可能导致运行很慢
基本原理:

2. Agglomerative clustering
基本思想为:从每一个点开始作为一个类,然后迭代的融合最近的类。能创建一个树形层次结构的聚类模型
算法优点为:
l 易于实现,具有广泛的应用
l 拥有一定的自适应形状
l 可提供层级聚类
算法缺点:
l 仍然需要选择聚类的个数或者设置相关的阈值
l 可能会导致聚类不平衡(如一个类超大,一个类超小)
基本原理为:


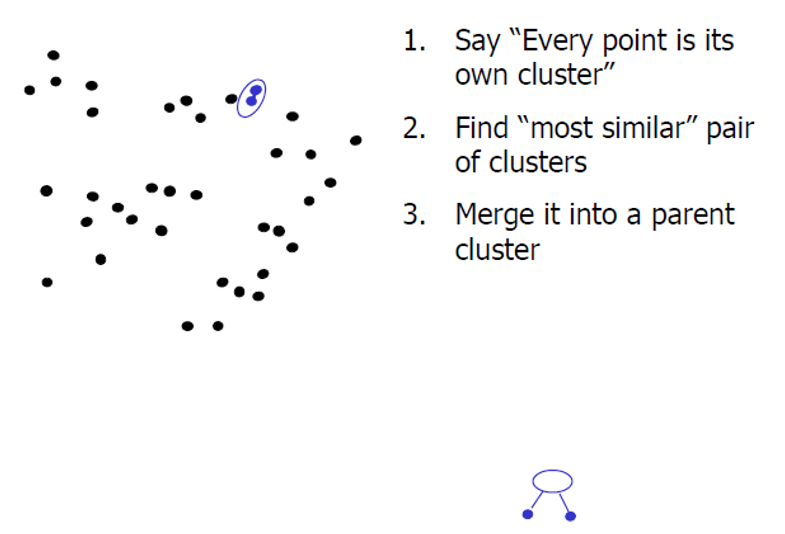
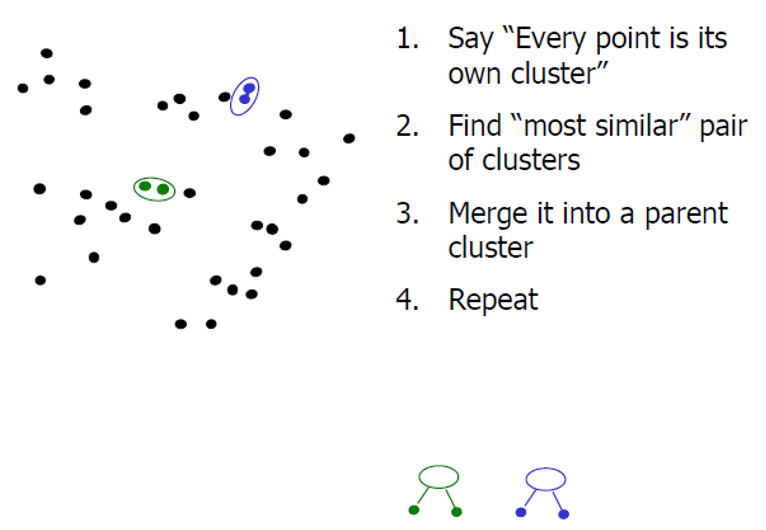
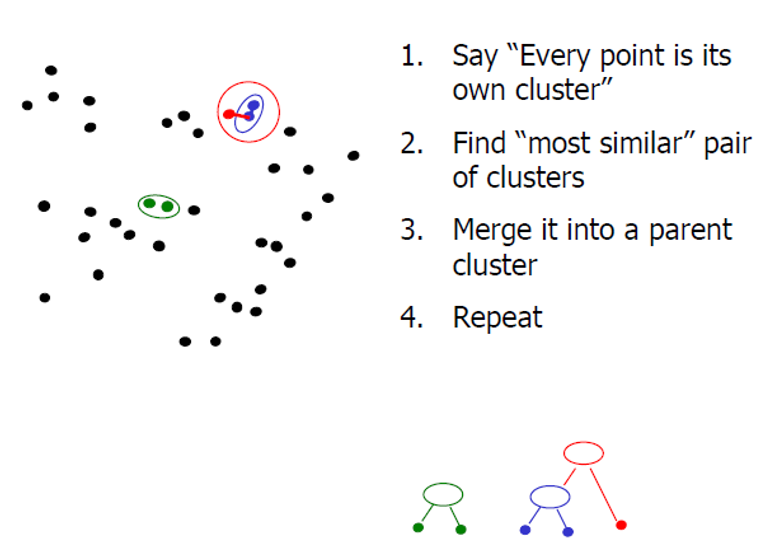
3. Mean shift
算法优点为:
l 对outliers很鲁棒
l 不需要预先设聚类的个数或者区域
算法缺点为:
l 需要设定核的尺寸
l 不适合特征维数很高的聚类
基本原理为:(算法流程+源码:http://blog.csdn.net/hjimce/article/details/45718593)
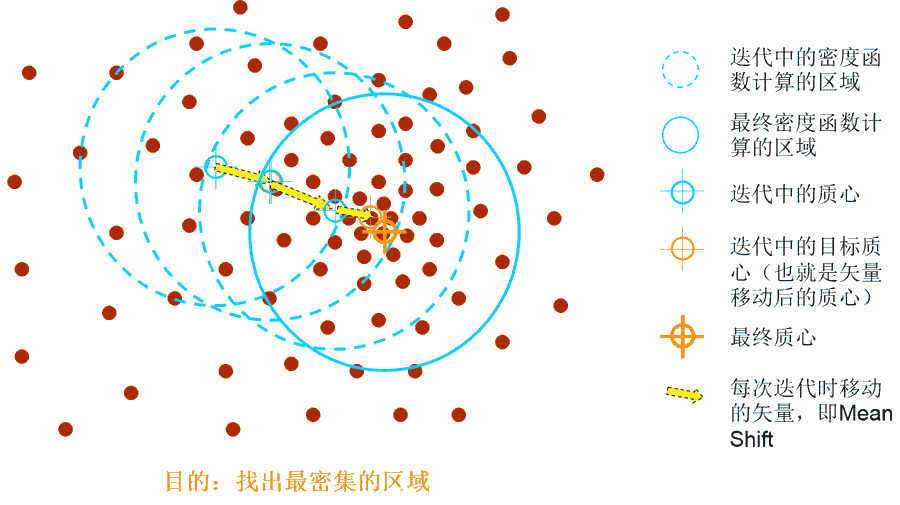
4. Spectral clustering
参见(https://www.cs.cmu.edu/~aarti/Class/10701/slides/Lecture21_2.pdf)
Algorithms and Applications》,教材《Learning
Image Processing with OpenCV》工具书《LearningOpenCV》,国外大学的课程《Computer
Vision》和课程《Computer
Vision》。
对于机器学习而言,聚类常常应用于离散情况下的非监督学习算法之中,如下图所示。
聚类的总体目标是使得最小化目标函数:
聚类的方法很多,常用的包括(K-means, Agglomerative clustering,mean shift, Spectral clustering)。
1. K-means
核心思想为迭代的指定点到最近的聚类中心。聚类算法会收敛到局部极小值。
算法的有点包括:
l 简单快速(不针对大型的聚类问题)
l 容易实现
l 能很好的表示数据
缺点包括
l 需要设定k
l 对outliers很敏感
l 收敛到局部极小值
l 对于大型的聚类问题,其算法复杂度较高,可能导致运行很慢
基本原理:
2. Agglomerative clustering
基本思想为:从每一个点开始作为一个类,然后迭代的融合最近的类。能创建一个树形层次结构的聚类模型
算法优点为:
l 易于实现,具有广泛的应用
l 拥有一定的自适应形状
l 可提供层级聚类
算法缺点:
l 仍然需要选择聚类的个数或者设置相关的阈值
l 可能会导致聚类不平衡(如一个类超大,一个类超小)
基本原理为:
3. Mean shift
算法优点为:
l 对outliers很鲁棒
l 不需要预先设聚类的个数或者区域
算法缺点为:
l 需要设定核的尺寸
l 不适合特征维数很高的聚类
基本原理为:(算法流程+源码:http://blog.csdn.net/hjimce/article/details/45718593)
4. Spectral clustering
参见(https://www.cs.cmu.edu/~aarti/Class/10701/slides/Lecture21_2.pdf)

相关文章推荐
- 常用牛人主页链接(计算机视觉、模式识别、机器学习相关方向,陆续更新。。。。)
- 计算机视觉常用资源汇总:OpenCV及CVPR相关、国内外视觉科研团队及网页、视觉相关书籍、数据库与期刊论文
- 计算机视觉、模式识别、机器学习常用牛人主页链接
- 常用牛人主页链接(计算机视觉、模式识别、机器学习相关方向,陆续更新。。。。)
- 常用牛人主页链接(计算机视觉、模式识别、机器学习相关方向,陆续更新。。。。)
- 计算机常用的几种语言:C语言
- 计算机视觉、模式识别、机器学习常用牛人主页链接
- 计算机视觉文献中常用名词解释
- 计算机视觉领域常用期刊和会议补充
- 计算机视觉、模式识别、机器学习常用牛人主页链接
- 机器视觉开源处理库汇总-介绍n款计算机视觉库/人脸识别开源库/软件 -几种图像处理类库的比较-视觉相关网站
- 常用牛人主页链接(计算机视觉、模式识别、机器学习相关方向,陆续更新。。。。)
- 计算机视觉、模式识别、机器学习常用牛人主页链接
- 机器视觉中常用的数据测试集 计算机视觉数据集
- 计算机视觉、模式识别、机器学习常用牛人主页链接
- 常用牛人主页链接(计算机视觉、模式识别、机器学习相关方向,陆续更新。。。。)
- 计算机视觉、模式识别、机器学习常用牛人主页链接
- 计算机视觉、模式识别、机器学习常用牛人主页链接
- 计算机视觉、模式识别、机器学习常用牛人主页链接
- 计算机视觉常用链接