Spark2.0安装配置
2016-11-03 14:48
344 查看
1. 下载
截止我写这篇文章的日期,spark的最新版本为2.0.0,因为我测试环境的hadoop版本是2.6.4的,所以我选择spark的版本是2.0.0,Hadoop是2.6;进入Apache Spark官网的下载页下载。
2. 环境配置
集群环境:| 主机名 | IP | hadoop环境 | Scala环境 | Java环境 |
|---|---|---|---|---|
| master | 192.168.146.146 | /usr/local/hadoop-2.6.4 | /usr/local/scala | /usr/local/jdk1.7.0_79 |
| node1 | 192.168.146.145 | /usr/local/hadoop-2.6.4 | /usr/local/scala | /usr/local/jdk1.7.0_79 |
| node2 | 192.168.146.144 | /usr/local/hadoop-2.6.4 | /usr/local/scala | /usr/local/jdk1.7.0_79 |
| node3 | 192.168.146.143 | /usr/local/hadoop-2.6.4 | /usr/local/scala | /usr/local/jdk1.7.0_79 |
将下载好的spark-2.0.0-bin-hadoop2.6.tgz拷贝到主机master上的/usr/local目录中,并执行命令解压到当前目录中:
tar -zxf spark-2.0.0-bin-hadoop2.6.tgz
解压后的目录结构如下:
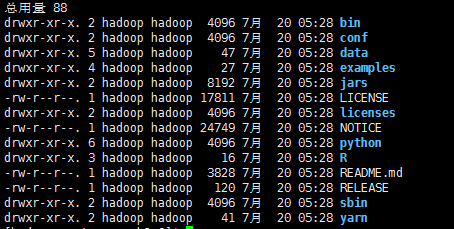
修改目录conf中的配置文件来配置spark的运行环境,conf目录中包含的文件有:
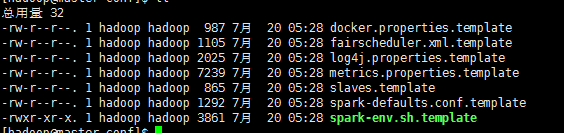
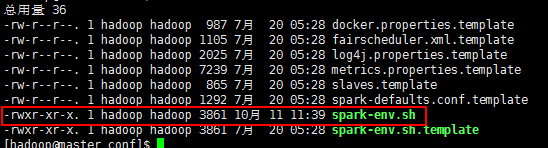
我们主要修改spark-env.sh这个文件。拷贝spark-env.sh.template并重命名为spark-env.sh:
cp spark-env.sh.template spark-env.sh,结果如下:
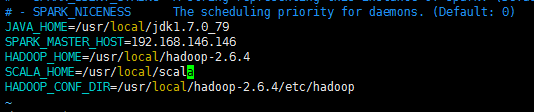
接下来修改spark-env.sh,主要添加以下几项配置:
| 配置项 | 值 | 说明 |
|---|---|---|
| JAVA_HOME | /usr/local/jdk1.7.0_79 | 指向jdk的安装路径 |
| HADOOP_HOME | /usr/local/hadoop-2.6.4 | 指向hadoop的安装路径 |
| SCALA_HOME | /usr/local/scala | scala的安装 |
| HADOOP_CONF_DIR | /usr/local/hadoop-2.6.4/etc/hadoop | hadoop配置文件所在的目录 |
| SPARK_MASTER_HOST | 192.168.146.146 | spark集群master运行主机 |
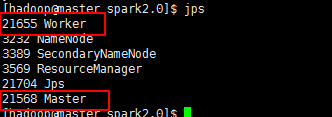
执行sbin/start-all.sh命令,查看是否能够启动spark,查看是否有Worker和Master进程。
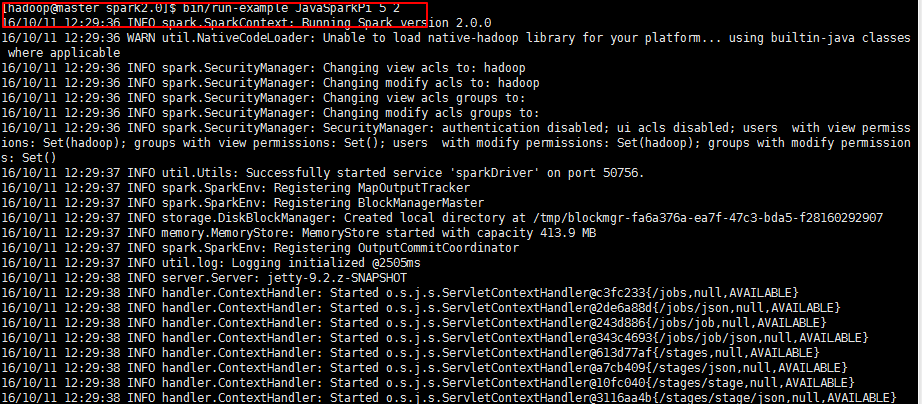
运行spark提供的示例检测:bin/run-example JavaSparkPi 5 2
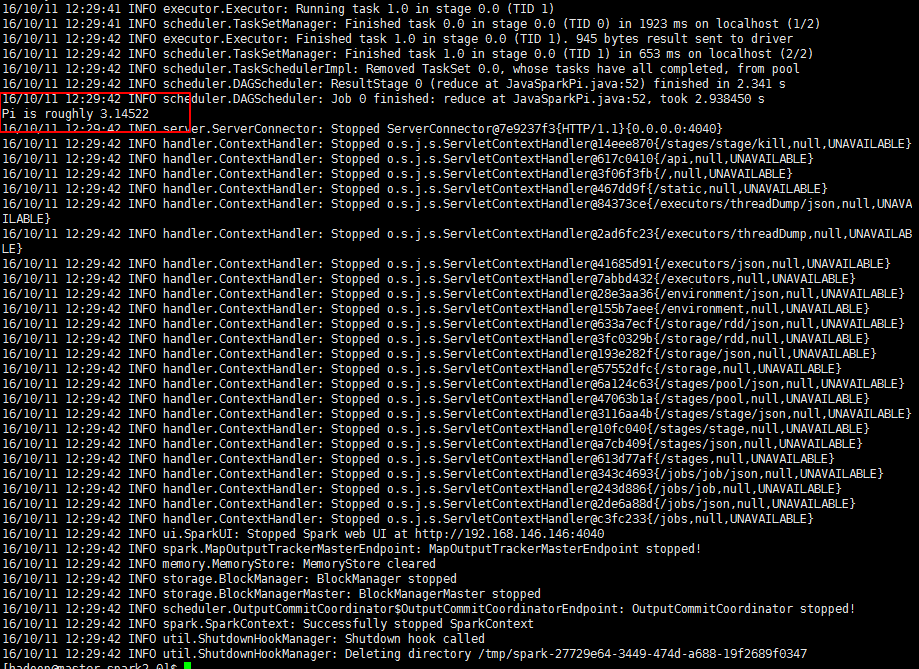
至此,单个节点的Spark环境配置结束。
3. 多个节点的集群环境配置
在上述单个节点启动成功的基础上,配置多个节点集群环境是比较简单的一件事情。修改master上节点的slaves配置文件来配置Worker节点的位置,这里我将node1、node2、node3作为Worker节点的运行机器,在conf/slaves(复制slaves.template)中添加node1、node2和node3。

将master上配置好的spark目录文件全部分别拷贝到node1、node2和node3所在机器上(可以通过ansible这个工具来操作)。
通过命令sbin/start-all.sh启动spark集群


也可以通过浏览器来查看集群状态,在浏览器中通过spark主节点的8080端口可以查看集群状态,在浏览器中输入:http://master:8080
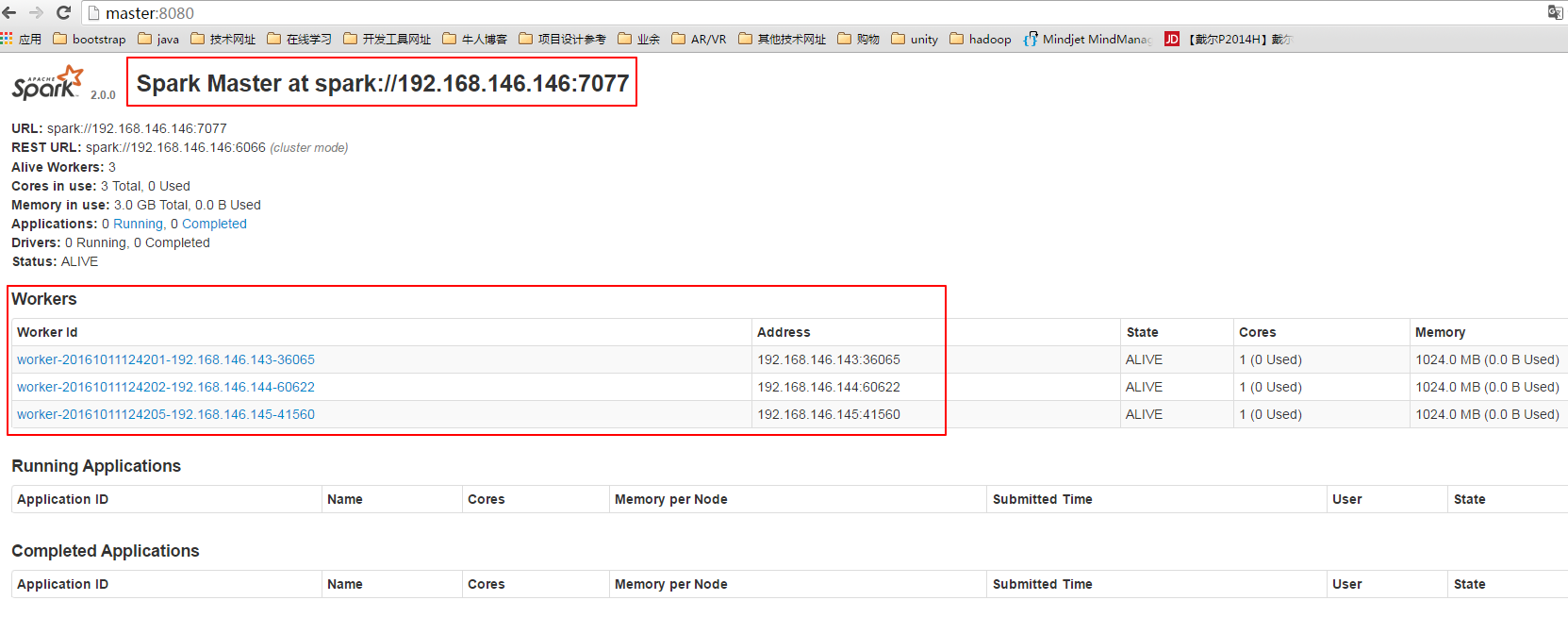
4. 运行测试
Standalone模式的测试 在shell环境下运行Spark提供的案例程序JavaSparkPi,通过如下命令:
bin/spark-submit –class org.apache.spark.examples.JavaSparkPi –master spark://master:7077 examples/jars/spark-examples_2.11-2.0.0.jar 10 4
shell界面输出如下信息:

从shell界面我们不能得到什么信息,我们可以通过浏览器来查看执行这个应用的具体信息,在浏览器中输入http://master:8080,我们将看到如下信息:
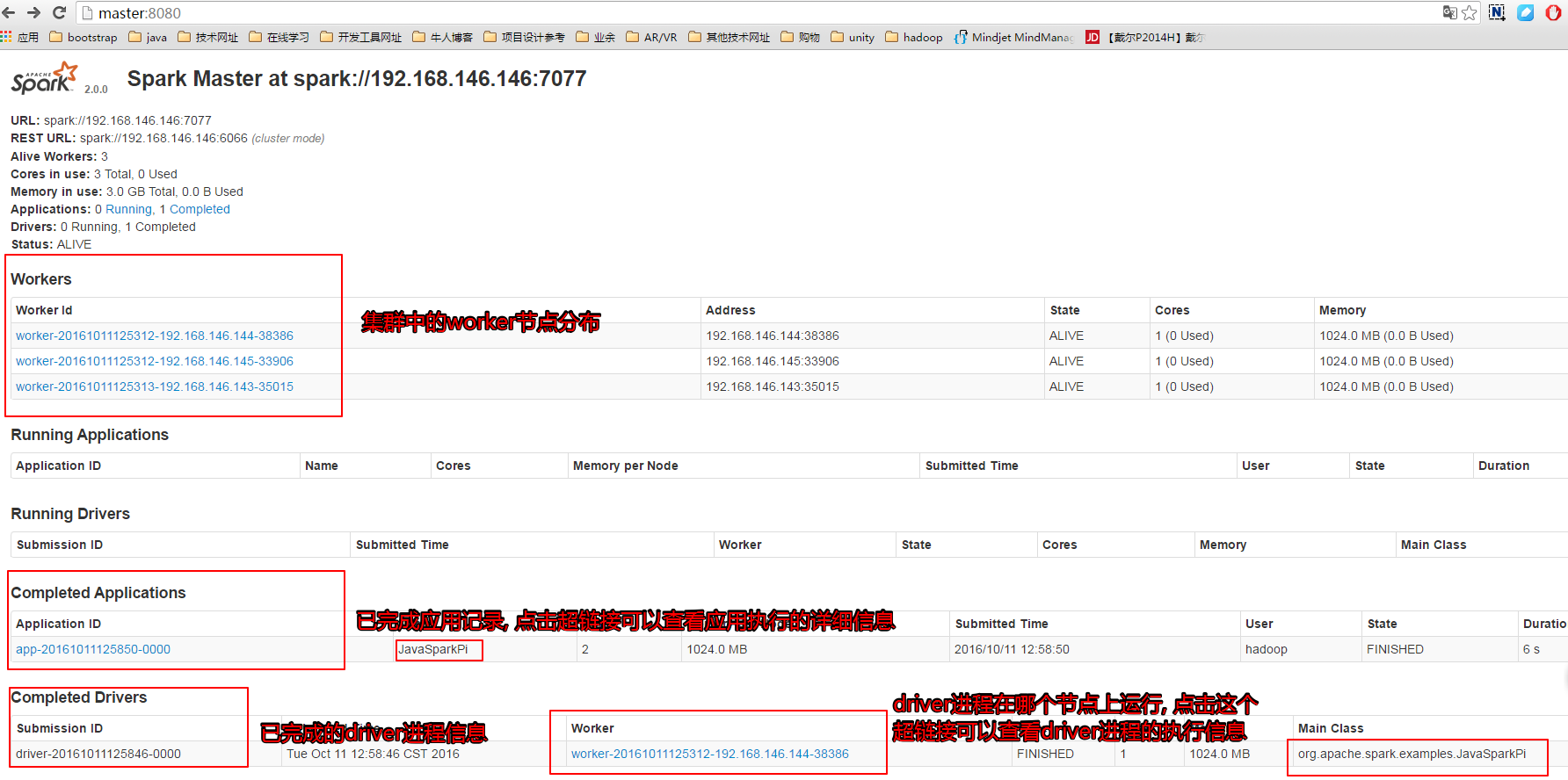
点击Completed Applications中的链接,我们可以查看运行这个应用所消耗的资源情况:
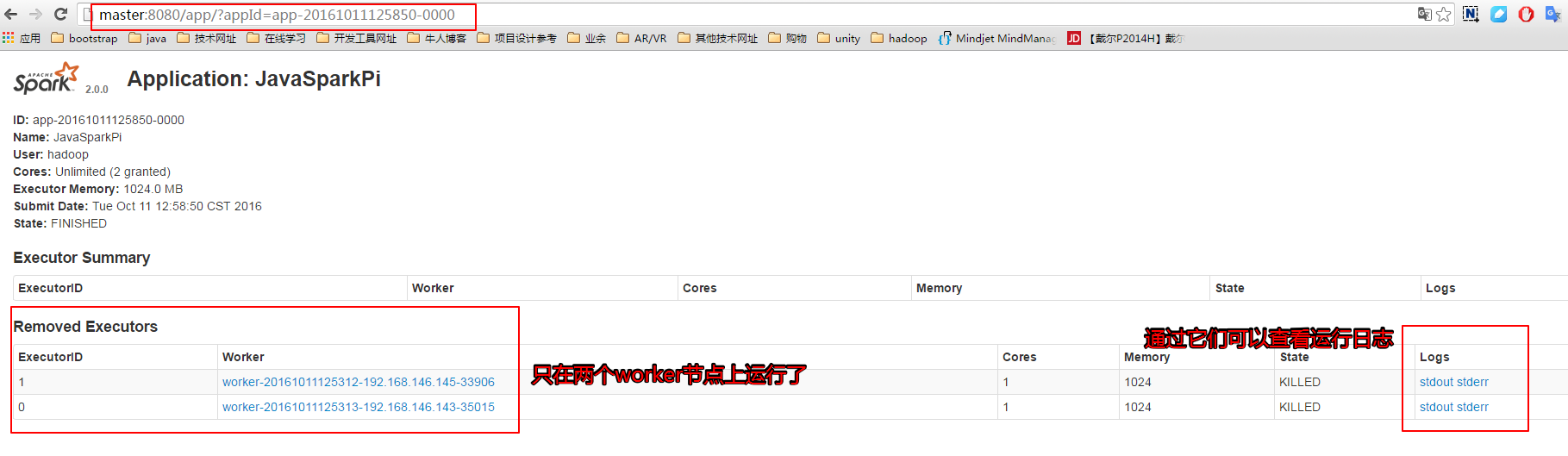
点击Completed Drivers下的超链来查看应用程序driver进程所在节点的信息,通过这个节点我们也可以查看整个应用程序的输入结果信息。
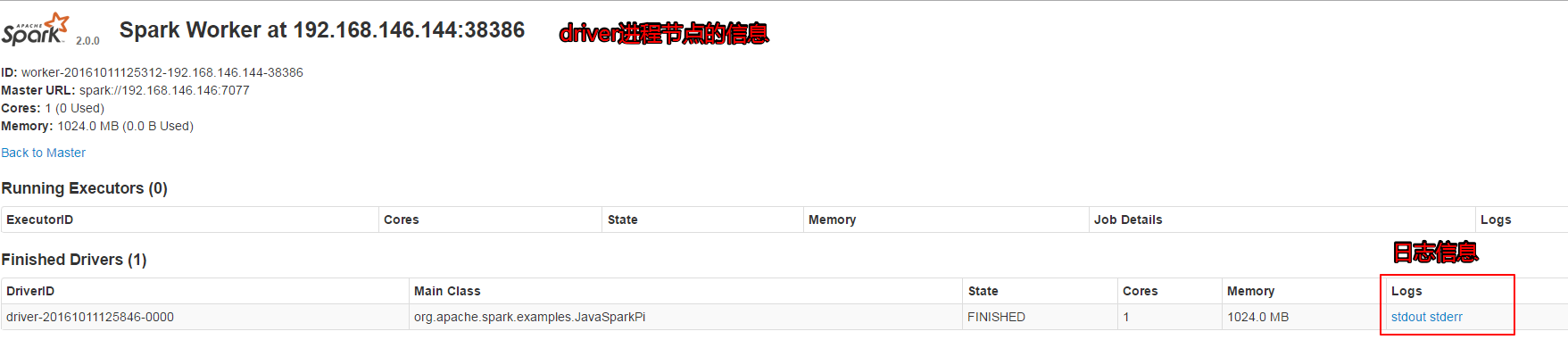
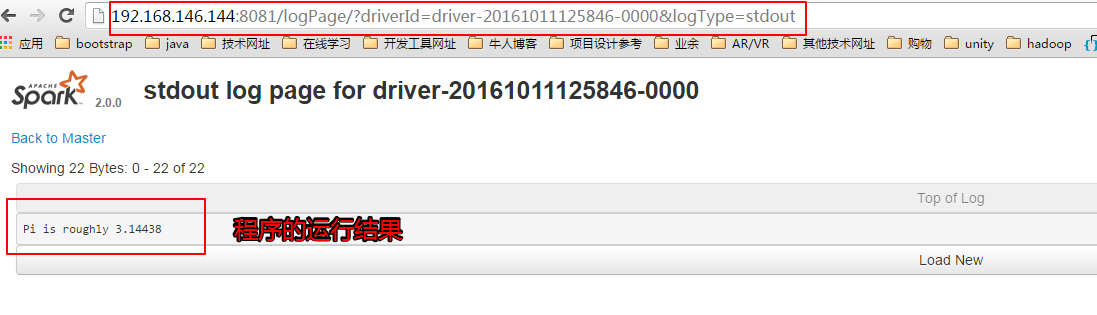
点击上图中的stdout,我们可以查看整个应该程序的输出结果。如下:

相关文章推荐
- VMware虚拟机内安装的Ubuntu 16.04设置静态IP地址 spark2.0集群固定IP配置
- VMware虚拟机内安装的Ubuntu 16.04设置静态IP地址 spark2.0集群固定IP配置
- Spark2.0安装配置
- ORACLE 10G HTML DB 2.0 安装配置
- TileCache 2.0 安装与配置
- Opencv 2.0在Windows下的安装与配置
- Openfire+Spark+Spark Web安装配置(三)
- IIS6 安装与配置.net 2.0过程的详细图解
- Linux下Apache2.0简单安装、配置、测试过程
- GTK-2.0 的安装和配置
- Openfire+Spark+Spark Web安装配置(一)
- ★★ MyEclipse 8.5 开发环境配置、插件安装、汉化、Aptana2.0插件,SVN 插件,Flex Builder 3/4 插件安装
- Enhydra Shark学习(二)Enhydra Shark2.0的安装与配置
- [转]ASP.NET 2.0中MemberShip数据库的安装、配置及文档结构(一)
- OpenCV1.0,2.0在windows和Linux下的安装和在QT,VS中的配置
- Apache HTTP Server 2.0 安装和配置记录
- ActiveBPEL2.0安装配置文档
- Openfire+Spark+Spark Web安装配置(一)
- 微软虚拟化之一Hyper-V 2.0的安装及基本配置
- Openfire+Spark+Spark Web安装配置 手记(二)