Web Spider实战1——简单的爬虫实战(爬取"豆瓣读书评分9分以上榜单")
2016-11-02 21:09
295 查看
1、Web Spider简介
Web Spider,又称为网络爬虫,是一种自动抓取互联网网页信息的机器人。它们被广泛用于互联网搜索引擎或其他类似网站,以获取或更新这些网站的内容和检索方式。它们可以自动采集所有其能够访问到的页面内容,以供搜索引擎做进一步处理(分检整理下载的页面),而使得用户能更快的检索到他们需要的信息。2、一个简单的网络爬虫案例
作者在浏览网页的时候看到豆瓣书单的网页(首页),如下所示: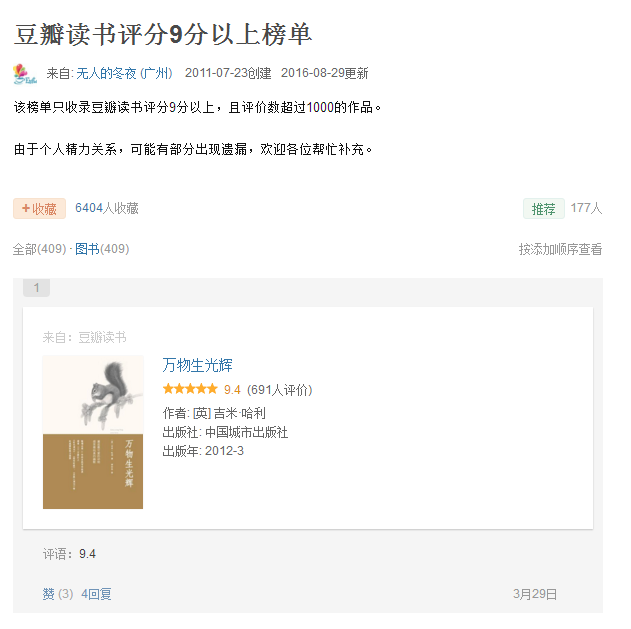
因为书单共有409本书,17个页面,若是要一个个浏览完,需要较长的时间,想要保存好书单,那是一件比较困难的事情,因此,想到是不是可以利用爬虫(Web Spider)把书名都保存下来,说干就干,下面详细介绍一下如何利用Python爬取书单。
3、单页面的抓取和分析
3.1、抓取
首先是单个页面的抓取,这里使用到了Python的urllib2库,urllib2库将网页以HTML的形式抓取到本地,代码如下:def spider(url, user_agent="wswp"):
print "Downloading: ", url
# 设置代理
headers = {"User-agent": user_agent}
request = urllib2.Request(url, headers=headers)
html = ""
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print "Download error: ", e.reason
html = None
return html在抓取的过程中,使用到了Request方法,urlopen方法和read方法。通过以上简单的抓取,将网页以HTML的格式抓取到本地。
3.2、对抓取的页面分析
在分析模块中主要是使用到了正则表达式,使用到了Python中的re库,利用正则表达式提取出书的名字,如:
页面的分析代码如下:
def parse_page(html):
html = html.replace("\r", "")
html = html.replace("\n", "")
html = html.replace("\013", "")
result = re.findall('<div class="title">(.*?)</div>', html)
book_list = []
for x in result:
# 得到书名
book_name = re.findall('<a.*?>(.+)</a>', x.strip())
book_list.append(book_name[0].strip())
return book_list最终得到了页面上的25本书的名字,如下:

3.3、主过程
在整个过程中使用到的模块为:import urllib2 import re
主过程为:
if __name__ == "__main__": seed = "https://www.douban.com/doulist/1264675/?start=0&sort=seq&sub_type=" html = spider(seed) book_list = parse_page(html) print len(book_list) for x in book_list: print x
4、抓取完整的书单
上面介绍了抓取其中一个页面的过程,为了能够抓取到完整的目录,需要解析所有的网页的网址,并对每一个网址都进行抓取,其中,网页的网址在页面下方的导航中:
在HTML代码中的格式为:

因此需要在分析模块中增加分析网址的功能,因此改进后的parse_page函数为:
def parse_page(html, url_map):
# 1、去除无效的字符
html = html.replace("\r", "")
html = html.replace("\n", "")
html = html.replace("\013", "")
# 2、解析出书名
result_name = re.findall('<div class="title">(.*?)</div>',html)
book_list = []
for x in result_name:
# 提取出书名
book_name = re.findall('<a.*?>(.+)</a>', x.strip())
book_list.append(book_name[0].strip())
# 3、解析出还有哪些网址
result_url = re.findall('<div class="paginator">(.*?)</div>', html)
url_list = re.findall("[a-zA-z]+://[^\s\"]*", result_url[0])
for x in url_list:
x = x.strip()
if x not in url_map:
url_map[x] = 0
return book_list, url_map在解析出书名后,解析出网址。
4.2、控制
在利用函数parse_page函数抓取一个网页后,分析出网页中的书单,同时,将网页中链向其他页面的网址提取出来,这样,我们需要一个控制模块,能够对提取出的网址依次抓取,分析,提取。这样的控制模块的代码如下:def control(seed):
# 设置map用于记录哪些网址需要爬取
url_map = {}
book_list = []
# 爬取种子网址
html = spider(seed)
url_map[seed] = 1 #种子网址已经爬取过
# 解析种子网址
book_tmp, url_map = parse_page(html, url_map)
for x in book_tmp:
book_list.append(x)
# 对url_map中的的网址依次爬取
while True:
for k, v in url_map.items():
if v == 0:
# 爬取
html = spider(k)
url_map[k] = 1
book_tmp, url_map = parse_page(html, url_map)
for x in book_tmp:
book_list.append(x)
break
else:
continue
if 0 not in url_map.values():
break
return book_list通过一个map存储所有页面的网址,key为网址,value为是否抓取过,0表示未抓取,1表示的是已抓取过。通过循环分析该map,直到所有的key对应的页面都被抓取过为止。
4.3、主函数
主函数为:if __name__ == "__main__": seed = "https://www.douban.com/doulist/1264675/?start=0&sort=seq&sub_type=" book_list = control(seed) print len(book_list) for x in book_list: print x
最终抓取到的书单的个数为408个,但是首页上显示有409本:
调研发现有一本书没有:
因此,整个抓取没有问题。
最终的书单的部分如下:

在上面实现了一个简单的爬虫,当然,想要抓取更多更复杂的网站,这个爬虫是不行的,接下来,我们会慢慢深入到爬虫的更多的技术。

相关文章推荐
- Python爬虫豆瓣读书评分9分以上榜单
- python3.5简单爬虫爬取百度百科(参考imooc实战)
- Python开发简单爬虫之实战演练
- python学习笔记:"爬虫+有道词典"实现一个简单的英译汉程序
- Python爬虫实战入门三:简单的HTML解析——爬取腾讯新闻
- Python爬虫实战入门二:从一个简单的HTTP请求开始
- Python爬虫实战之爬取链家广州房价_01简单的单页爬虫
- java爬虫实战简单用Jsoup框架进行网页爬虫(如抓取网页图片)
- Python 爬虫简单实战之CSDN
- Python爬虫实战(十一):两种简单的方法爬取动态网页
- python开发简单爬虫:实战篇
- Python爬虫简单实战,58同城西安二手笔电
- 实践项目十:爬取百度百科Python词条相关1000个页面数据(慕课简单爬虫实战)
- 最简单的python爬虫实战——爬取王者荣耀皮肤及头像
- Python爬虫简单实战:抓取小猪短租西安市前五页民房数据
- Python爬虫实战(三):简单爬取网页图片
- 简单爬虫实战
- 爬虫实战--简单爬取小说网站的小说(面对过程)
- python爬虫实战之最简单的网页爬虫教程
- Linux 内核级后门的原理和简单实战