Ambari安装使用介绍
2016-11-02 08:34
330 查看
一、前言
在开始研究大数据Hadoop生态圈的时候,都是跟网上找了一下相关材料,官网上查询一下文档信息,对比着安装,从最初的3台机器开始,接触了Hadoop,开始了解Hadoop中的HDFS文件分布式系统,还有编写一些小的MapReduce的例子,慢慢的接触到了Zookeeper的使用,Hive,Hbase等等,每一个项目都是手工修改配置文件,然后启动相应的服务,试想一下,大公司在几十个,几百个,上千个节点,如果都是这样来配置还有监控大数据系统的状态是多么费劲,由此出来的Ambari,Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、Sqoop和Hcatalog等.
二、安装准备
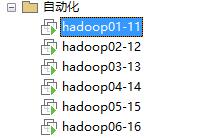
1、准备6台机器,我是在虚拟机中安装配置,操作系统为CentOS6.5
6台机器的IP从192.168.0.11-192.168.0.17, 11作为管理节点
2、停止防火墙服务

3、永久关闭防火墙

4、安装Ambari前需要先将openssl和openssh-clients库安装到Linux系统中
(本人采取系统是最小化安装)
5、SSH 的无密码登录;
Ambari 的 Server 会 SSH 到 Agent 的机器,拷贝并执行一些命令。因此我们需要配置 Ambari Server 到 Agent 的 SSH 无密码登录。在这个例子里,hadoop01 可以 SSH 无密码登录hadoop02到hadoop06,同步Hosts文件
修改hosts文件:
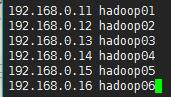
同步Hosts文件,拷贝到hadoop02-hadoop06中

设置SSH免登陆:在hadoop01中配置到hadoop06中所有的免登陆
在Hadoop01中生成密匙
拷贝
4000
公钥到hadoop02-hadoop06
6、下载yum仓库文件在hadoop01中
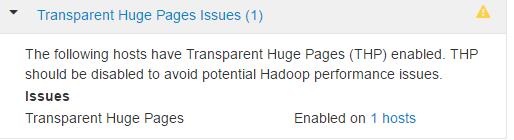
备注:避免大页未启动检查出错
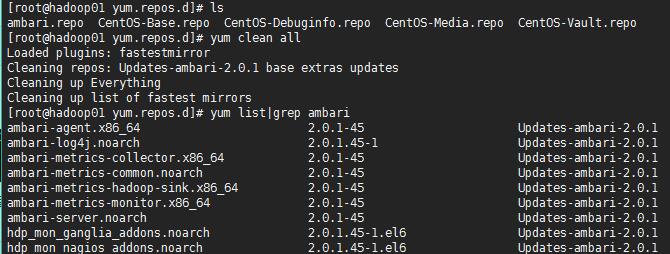
如果可以看到 Ambari 的对应版本的安装包列表,说明公共库已配置成功。然后就可以安装 Ambari 的 package 了。执行下面的命令安装 Ambari Server 到该机器。
待安装完成后,便需要对 Ambari Server 做一个简单的配置。执行下面的命令,(我这里执行默认选项),大家可以根据自己的配置做选择
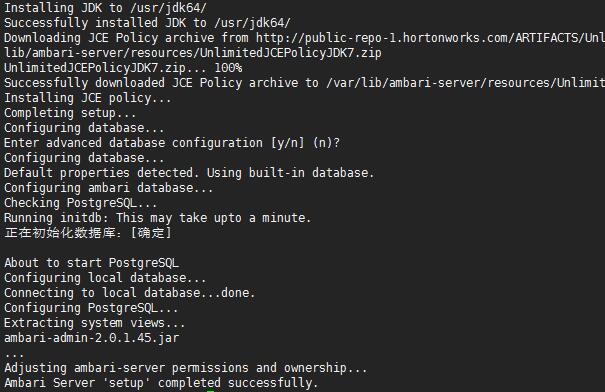
ambari-server相关命令:
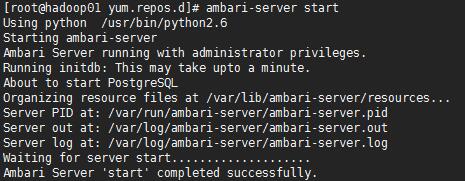
启动成功后可以使用:http://hostname:8080访问WebUi地址,用户名和密码是ADMIN,ADMIN
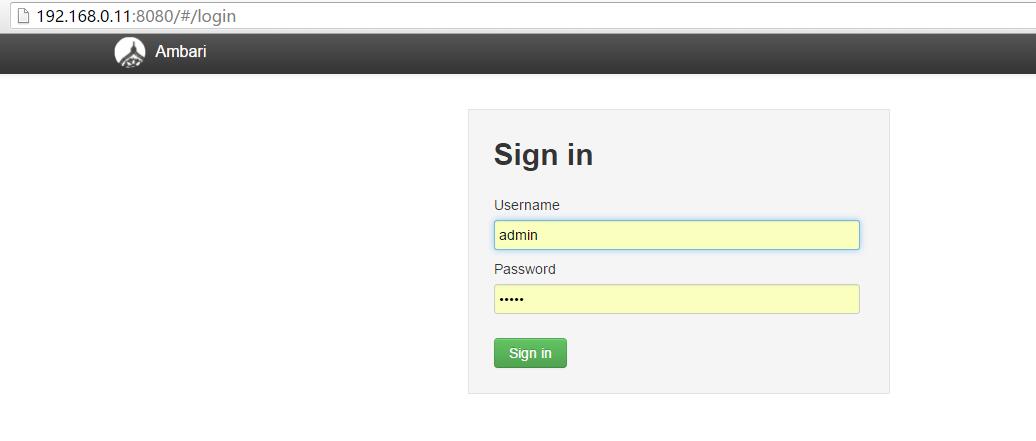
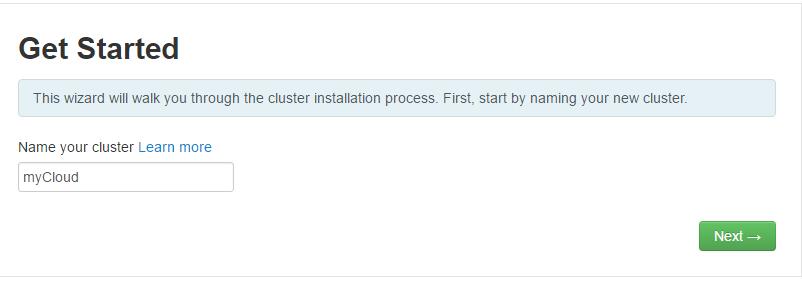
点击选择 Launch Install Wizard 输入您集群名称
部署一个Hadoop2.X的集群,选择一个 Stack,这个 Stack 相当于一个 Hadoop 生态圈软件的集合。Stack 的版本越高,里面的软件版本也就越高。这里我们选择 HDP2.2,里面的对应的 Hadoop 版本为 2.6.x。
设置HostName列表,将管理机器Hadoop01的私钥上传
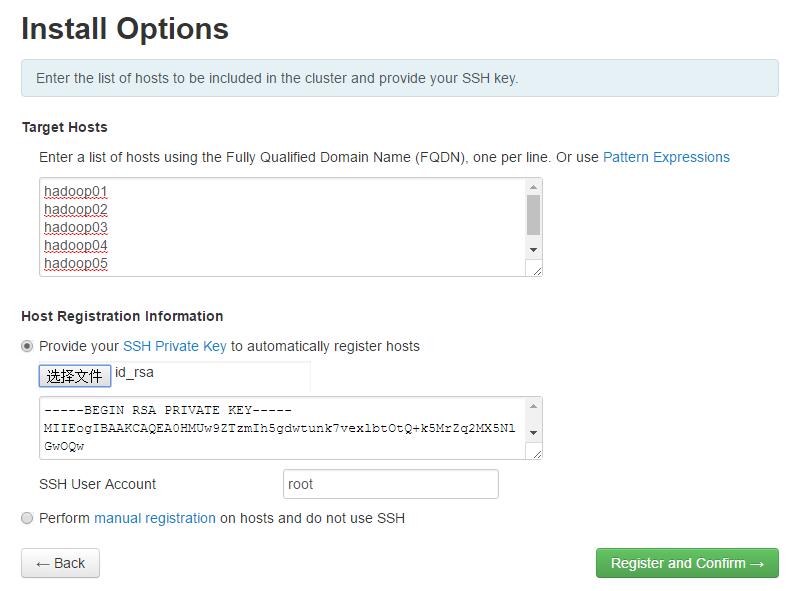
注册Ambari的相关属性
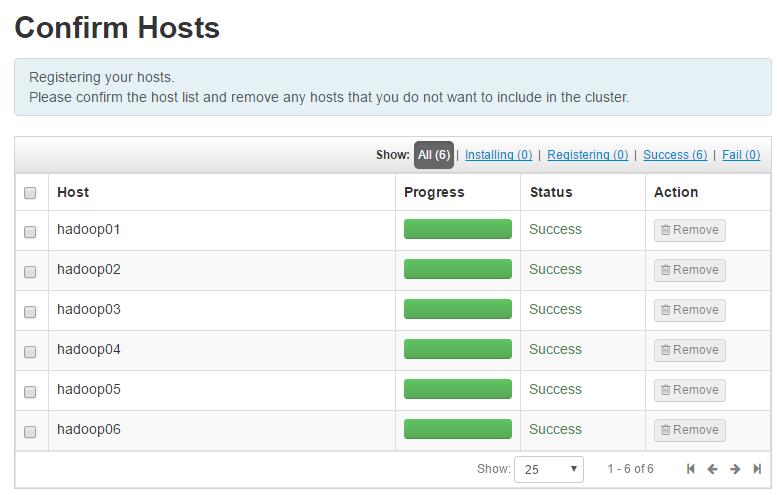
确定检查通过
我这里遇到启动大页的警告
解决:
查看是否启动大页返回0意味着禁用大页
启用大页功能:
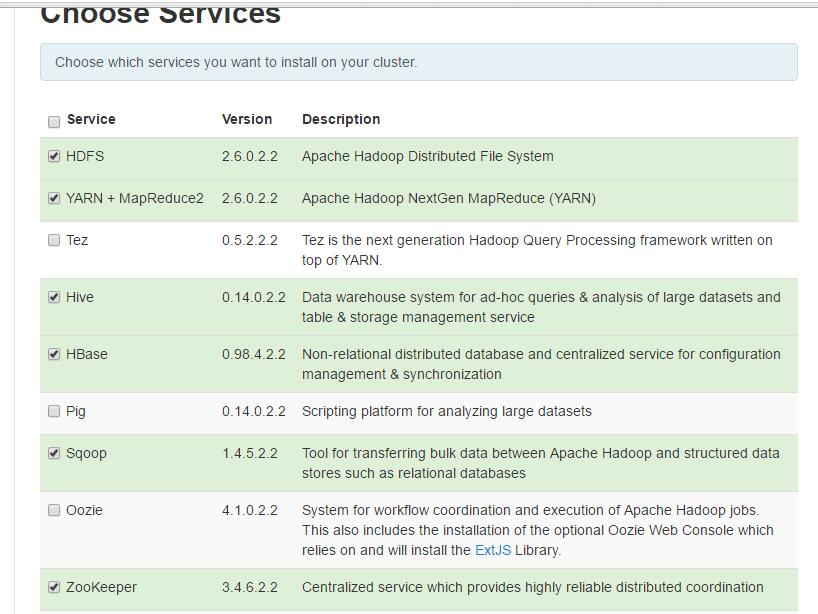
根据自己需要的功能勾选
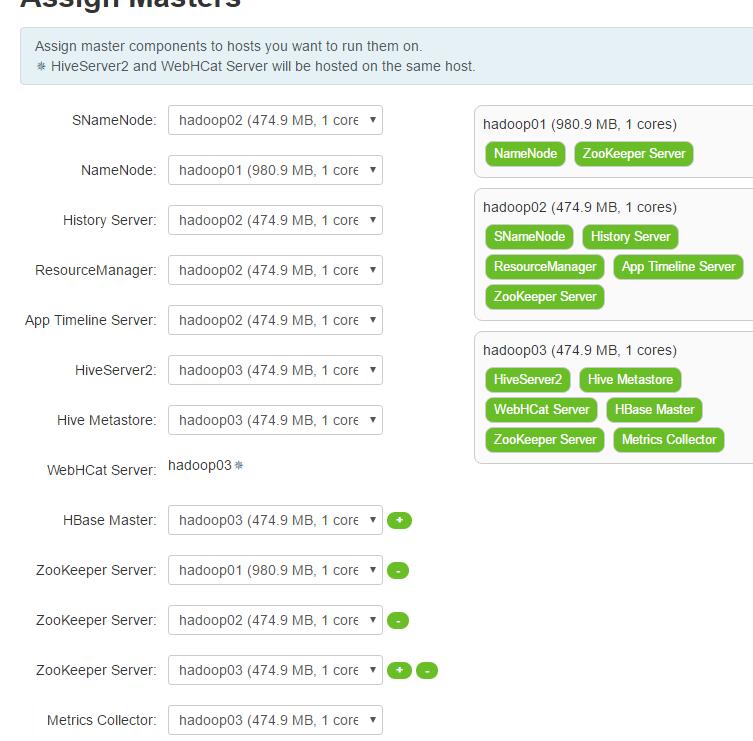
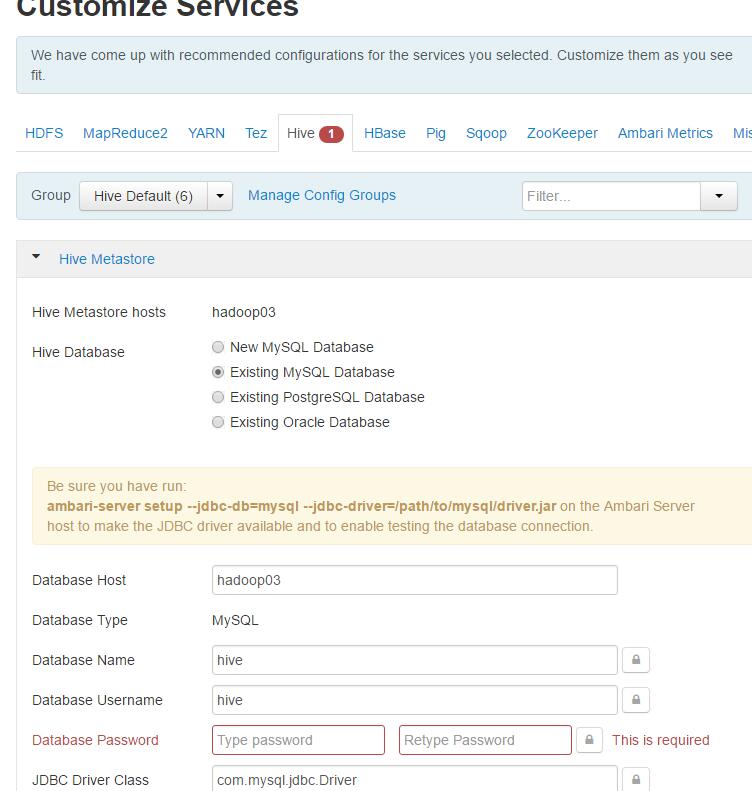
配置Hive选择自己的Mysql存储元数据
7、安装Mysql
在Hadoop03中启动配置Mysql
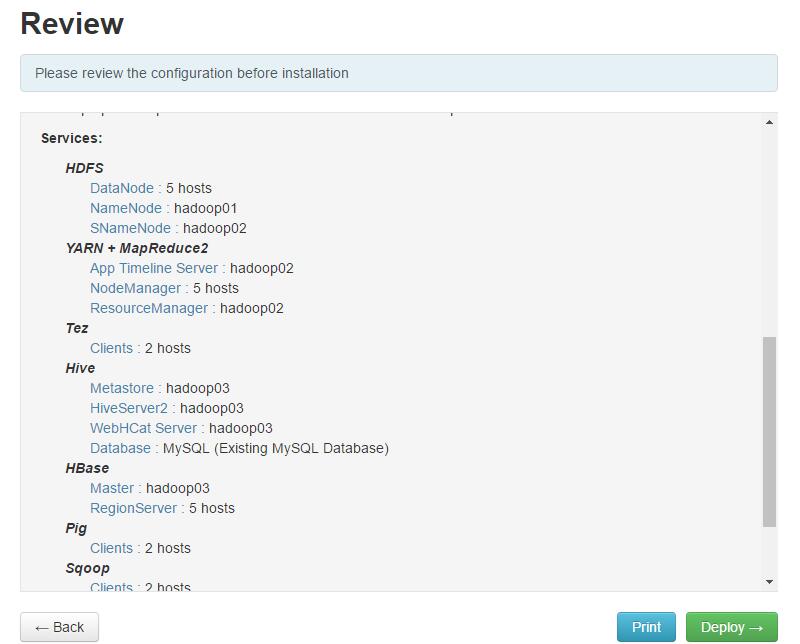
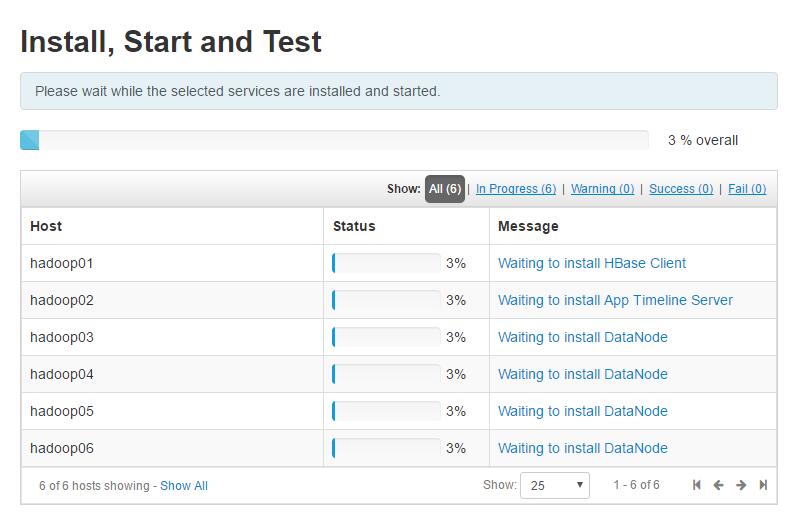
开始安装中
各台机器的安装目录:
/usr/lib/hadoop
/usr/lib/hbase
/usr/lib/zookeeper
/usr/lib/hcatalog
/usr/lib/hive
Log路径, 这里需要看出错信息都可以在目录下找到相关的日志
/var/log/hadoop
/var/log/hbase
配置文件的路径
/etc/hadoop
/etc/hbase
/etc/hive
HDFS的存储路径
/hadoop/hdfs
在开始研究大数据Hadoop生态圈的时候,都是跟网上找了一下相关材料,官网上查询一下文档信息,对比着安装,从最初的3台机器开始,接触了Hadoop,开始了解Hadoop中的HDFS文件分布式系统,还有编写一些小的MapReduce的例子,慢慢的接触到了Zookeeper的使用,Hive,Hbase等等,每一个项目都是手工修改配置文件,然后启动相应的服务,试想一下,大公司在几十个,几百个,上千个节点,如果都是这样来配置还有监控大数据系统的状态是多么费劲,由此出来的Ambari,Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、Sqoop和Hcatalog等.
二、安装准备
1、准备6台机器,我是在虚拟机中安装配置,操作系统为CentOS6.5
6台机器的IP从192.168.0.11-192.168.0.17, 11作为管理节点
2、停止防火墙服务
3、永久关闭防火墙
4、安装Ambari前需要先将openssl和openssh-clients库安装到Linux系统中
(本人采取系统是最小化安装)
yum install openssl yum install openssh-clients yum install ntp yum install ntpdate chkconfig ntpd on ntpdate 202.108.6.95 /etc/init.d/ntpd start ntpq -p
5、SSH 的无密码登录;
Ambari 的 Server 会 SSH 到 Agent 的机器,拷贝并执行一些命令。因此我们需要配置 Ambari Server 到 Agent 的 SSH 无密码登录。在这个例子里,hadoop01 可以 SSH 无密码登录hadoop02到hadoop06,同步Hosts文件
修改hosts文件:
vim /etc/hosts
同步Hosts文件,拷贝到hadoop02-hadoop06中
设置SSH免登陆:在hadoop01中配置到hadoop06中所有的免登陆
在Hadoop01中生成密匙
ssh-keygen -t rsa
拷贝
4000
公钥到hadoop02-hadoop06
ssh-copy-id hadoop01 ssh-copy-id hadoop02 ssh-copy-id hadoop03 ssh-copy-id hadoop04 ssh-copy-id hadoop05 ssh-copy-id hadoop06
6、下载yum仓库文件在hadoop01中
cd /etc/yum.repos.d wget http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.0.1/ambari.repo yum clean all yum list|grep ambari
备注:避免大页未启动检查出错
vim /etc/grub.conf 最后中加入 transparent_hugepage=always 重启系统
如果可以看到 Ambari 的对应版本的安装包列表,说明公共库已配置成功。然后就可以安装 Ambari 的 package 了。执行下面的命令安装 Ambari Server 到该机器。
yum install ambari-server
待安装完成后,便需要对 Ambari Server 做一个简单的配置。执行下面的命令,(我这里执行默认选项),大家可以根据自己的配置做选择
ambari-server setup
ambari-server start
ambari-server相关命令:
ambari-server start | stop | reset
启动成功后可以使用:http://hostname:8080访问WebUi地址,用户名和密码是ADMIN,ADMIN
点击选择 Launch Install Wizard 输入您集群名称
部署一个Hadoop2.X的集群,选择一个 Stack,这个 Stack 相当于一个 Hadoop 生态圈软件的集合。Stack 的版本越高,里面的软件版本也就越高。这里我们选择 HDP2.2,里面的对应的 Hadoop 版本为 2.6.x。
设置HostName列表,将管理机器Hadoop01的私钥上传
注册Ambari的相关属性
确定检查通过
我这里遇到启动大页的警告
解决:
查看是否启动大页返回0意味着禁用大页
cat /sys/kernel/mm/redhat_transparent_hugepage/enabled [always] madvise never grep -i HugePages_Total /proc/meminfo HugePages_Total: 0
启用大页功能:
vim /etc/grub.conf 最后中加入 transparent_hugepage=always 重启系统
根据自己需要的功能勾选
配置Hive选择自己的Mysql存储元数据
7、安装Mysql
在Hadoop03中启动配置Mysql
yum install mysql-server service mysqld start /usr/bin/mysql_secure_installation chkconfig --level 235 mysqld on mysql –u root –p create database hive; create user "hive" identified by "hive"; grant all privileges on hive.* to hive; flush privileges; ambari-server setup --jdbc-db=mysql --jdbc-driver=/path/to/mysql/driver.jar
开始安装中
各台机器的安装目录:
/usr/lib/hadoop
/usr/lib/hbase
/usr/lib/zookeeper
/usr/lib/hcatalog
/usr/lib/hive
Log路径, 这里需要看出错信息都可以在目录下找到相关的日志
/var/log/hadoop
/var/log/hbase
配置文件的路径
/etc/hadoop
/etc/hbase
/etc/hive
HDFS的存储路径
/hadoop/hdfs

相关文章推荐
- Hadoop建设工具Ambari的安装部署及完整使用(一)——介绍
- Windows Live Writer 安装及使用介绍
- 经典vim插件功能说明、安装方法和使用方法介绍(已更新)
- MongoDB Primary---->简要介绍 和 Linux安装MongoDB 并 简单使用
- ubunut11.0安装nginx基本目录结构介绍和配置使用方法
- mysql安装图解(详细步骤),配置,相关图形工具介绍及使用,中文支持
- vim插件【功能说明、安装方法和使用方法介绍】
- 经典vim插件功能说明、安装方法和使用方法介绍(已更新)
- node.js 第三方模块如何安装(使用npm)及介绍
- 不错的 solr 使用安装介绍
- LLVM安装使用介绍
- lighttpd的安装和基本模块的使用介绍
- Windows Server Update Server (WSUS) 介绍,安装与使用
- 进口轴承使用手册中介绍的推力轴承紧环和松环的安装
- 集群作业管理openPBS安装和使用介绍
- Linux压力测试工具webbench的安装使用介绍
- 第4章 ISE开发环境使用指南[FPGA开发实用教程]——第1节 ISE套件的介绍与安装
- Git介绍,安装,Git+Git flow使用