htmlunit抓取js执行后的网页源码
2016-11-01 13:19
204 查看
上次我不是写了一个自动抓取博客访问量吗 (点击打开链接) 可是昨天晚上我又运行的时候,发现不能用了。。
运行了几次 发现使用URLConnection 得到的网页源码和浏览器直接查看的不同。 URLConnection 使用IO流读取到的源码
只有积分 没有访问量了

而使用浏览器访问 直接查看源码

有访问。
这也就导致了我的程序不能用了 需要更新了

想想原因 可能是幕后主使人把访问量放在了js里面 动态展示,而我使用URLConnection 访问的静态界面 确确实实没有收到。
于是开始百度了 百度过来 百度过去。。
发现了一个回复了三年还没有结贴的帖子
里面回复了好多方法 发现有个htmlunit 于是就自己测试一下
发现真的可以。得到了js执行后的源码。
废话不说了。
方法如下
最后得到的源码如下:

其它的代码和点击打开链接 这篇文章相比几乎没变。如果不明白 可以去看一下 这里就不再赘述了
执行后 成功写入到txt文档

使用了htmlunit会弹出好多异常警告
加上这些代码 就会消失了~
由于我们在这里 引入了htmlunit 的jar包 .那么再用上次的脚本批量处理 就行不通了 ~
而且要引入的jar包也不是一个 是多个 所以要批量处理了
首先我们要把所有要用的jar包 使用-cp命令导入。
可是htmlunit的jar包太多了 所以想到一个方法 使用for循环遍历htmlunit文件夹里面的jar文件 将其处理为一个字符串 然后再使用-cp命令 全部代码如下
htmlunit jar包下载
运行了几次 发现使用URLConnection 得到的网页源码和浏览器直接查看的不同。 URLConnection 使用IO流读取到的源码
只有积分 没有访问量了
而使用浏览器访问 直接查看源码
有访问。
这也就导致了我的程序不能用了 需要更新了
想想原因 可能是幕后主使人把访问量放在了js里面 动态展示,而我使用URLConnection 访问的静态界面 确确实实没有收到。
于是开始百度了 百度过来 百度过去。。
发现了一个回复了三年还没有结贴的帖子
java爬虫项目,如何获取js执行后的完整网页源代码?
里面回复了好多方法 发现有个htmlunit 于是就自己测试一下发现真的可以。得到了js执行后的源码。
废话不说了。
方法如下
public static void main(String[] args) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
// TODO Auto-generated method stub
WebClient wc=new WebClient(BrowserVersion.FIREFOX_24);
wc.setJavaScriptTimeout(5000);
wc.getOptions().setUseInsecureSSL(true);//接受任何主机连接 无论是否有有效证书
wc.getOptions().setJavaScriptEnabled(true);//设置支持javascript脚本
wc.getOptions().setCssEnabled(false);//禁用css支持
wc.getOptions().setThrowExceptionOnScriptError(false);//js运行错误时不抛出异常
wc.getOptions().setTimeout(100000);//设置连接超时时间
wc.getOptions().setDoNotTrackEnabled(false);
HtmlPage page=wc.getPage("http://blog.csdn.net/su20145104009?viewmode=contents");
String res=page.asText();
//处理源码
deal(res);
}最后得到的源码如下:
其它的代码和点击打开链接 这篇文章相比几乎没变。如果不明白 可以去看一下 这里就不再赘述了
执行后 成功写入到txt文档
使用了htmlunit会弹出好多异常警告
加上这些代码 就会消失了~
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log", "org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware.htmlunit")
.setLevel(Level.OFF);
java.util.logging.Logger.getLogger("org.apache.commons.httpclient")
.setLevel(Level.OFF);由于我们在这里 引入了htmlunit 的jar包 .那么再用上次的脚本批量处理 就行不通了 ~
而且要引入的jar包也不是一个 是多个 所以要批量处理了
首先我们要把所有要用的jar包 使用-cp命令导入。
可是htmlunit的jar包太多了 所以想到一个方法 使用for循环遍历htmlunit文件夹里面的jar文件 将其处理为一个字符串 然后再使用-cp命令 全部代码如下
echo off
setlocal enabledelayedexpansion
::定义一个字符串
set str=
::遍历htmlunit文件夹
for /f "delims=" %%a in ('dir /b "E:\lib\htmlunit-2.14-bin\lib\*.jar"') do (
set "str=!str!E:\lib\htmlunit-2.14-bin\lib\%%a;"
)
echo on
e:
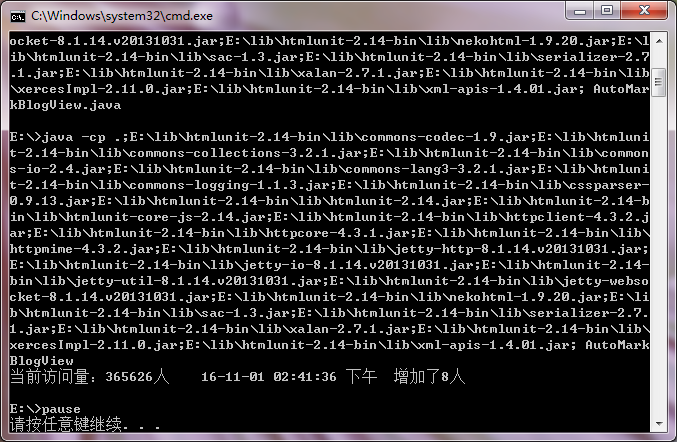
javac -cp .;%str% AutoMarkBlogView.java
java -cp .;%str% AutoMarkBlogView
pause运行结果如下:htmlunit jar包下载

相关文章推荐
- htmlunit抓取js执行后的网页源码
- htmlunit扒取JS加载之后的网页源码(2)——解决带参、中文乱码和转义问题
- 如何抓取执行js之后的网页内容
- htmlunit扒取JS加载之后的网页源码(1)
- jsoup+htmlUnit可以实现抓取执行过js的html页面
- AS2 点击转到新网页,并且执行网页中JS
- C# 抓取网页Html源码 (网络爬虫)
- iPhone、iPad 网页抓取工具源码分享
- Ajax网页源码抓取程序
- JavaScript 全面解析各种浏览器网页中的JS 执行顺序
- [置顶] 自己动手写CSDN博客提取器源码分析之四:抓取网页源码
- 异步加载js文件并执行js方法:实现异步处理网页的复杂效果
- JavaScript 全面解析各种浏览器网页中的JS 执行顺序
- 三种asp.net 抓取网页源码实现(asp.net采集,读取源码)
- js实现当用户复制网页内容时添加版权等额外信息源码
- socket网页抓取源码
- C# 抓取网页Html源码 (网络爬虫)
- 抓取源码爱好者所有网页特效例子并保存到本地
- js取网页源码
- js获取网页源码