NOIP 2011 瑞士轮
2016-10-31 20:51
162 查看
题目背景
在双人对决的竞技性比赛,如乒乓球、羽毛球、国际象棋中,最常见的赛制是淘汰赛和循环赛。前者的特点是比赛场数少,每场都紧张刺激,但偶然性较高。后者的特点是较为公平,偶然性较低,但比赛过程往往十分冗长。
本题中介绍的瑞士轮赛制,因最早使用于1895年在瑞士举办的国际象棋比赛而得名。它可以看作是淘汰赛与循环赛的折衷,既保证了比赛的稳定性,又能使赛程不至于过长。
题目描述
2*N 名编号为 1~2N 的选手共进行R 轮比赛。每轮比赛开始前,以及所有比赛结束后,都会按照总分从高到低对选手进行一次排名。选手的总分为第一轮开始前的初始分数加上已参加过的所有比赛的得分和。总分相同的,约定编号较小的选手排名靠前。
每轮比赛的对阵安排与该轮比赛开始前的排名有关:第1 名和第2 名、第 3 名和第 4名、……、第2K – 1 名和第 2K名、…… 、第2N – 1 名和第2N名,各进行一场比赛。每场比赛胜者得1 分,负者得 0 分。也就是说除了首轮以外,其它轮比赛的安排均不能事先确定,而是要取决于选手在之前比赛中的表现。
现给定每个选手的初始分数及其实力值,试计算在R 轮比赛过后,排名第 Q 的选手编号是多少。我们假设选手的实力值两两不同,且每场比赛中实力值较高的总能获胜。
输入输出格式
输入格式:
输入文件名为swiss.in 。
输入的第一行是三个正整数N、R 、Q,每两个数之间用一个空格隔开,表示有 2*N 名选手、R 轮比赛,以及我们关心的名次 Q。
第二行是2*N 个非负整数s1, s2, …, s2N,每两个数之间用一个空格隔开,其中 si 表示编号为i 的选手的初始分数。 第三行是2*N 个正整数w1 , w2 , …, w2N,每两个数之间用一个空格隔开,其中 wi 表示编号为i 的选手的实力值。
输出格式:
输出文件名为swiss.out。
输出只有一行,包含一个整数,即R 轮比赛结束后,排名第 Q 的选手的编号。
输入输出样例
输入样例#1:
2 4 2
7 6 6 7
10 5 20 15
输出样例#1:
1
说明
【样例解释】
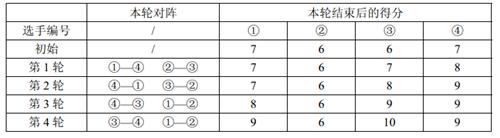
【数据范围】
对于30% 的数据,1 ≤ N ≤ 100;
对于50% 的数据,1 ≤ N ≤ 10,000 ;
对于100%的数据,1 ≤ N ≤ 100,000,1 ≤ R ≤ 50,1 ≤ Q ≤ 2N,0 ≤ s1, s2, …, s2N≤10^8,1 ≤w1, w2 , …, w2N≤ 10^8。
noip2011普及组第3题。
【分析】
好题啊好题
裸sort会被卡掉…
我们发现每次比赛完以后两两分数会改变,但所有赢的人分数都+1,所有输的人分数都不变,所以赢的人与输的人分数仍然是排好序的,这时候要用到二路归并
【代码】
在双人对决的竞技性比赛,如乒乓球、羽毛球、国际象棋中,最常见的赛制是淘汰赛和循环赛。前者的特点是比赛场数少,每场都紧张刺激,但偶然性较高。后者的特点是较为公平,偶然性较低,但比赛过程往往十分冗长。
本题中介绍的瑞士轮赛制,因最早使用于1895年在瑞士举办的国际象棋比赛而得名。它可以看作是淘汰赛与循环赛的折衷,既保证了比赛的稳定性,又能使赛程不至于过长。
题目描述
2*N 名编号为 1~2N 的选手共进行R 轮比赛。每轮比赛开始前,以及所有比赛结束后,都会按照总分从高到低对选手进行一次排名。选手的总分为第一轮开始前的初始分数加上已参加过的所有比赛的得分和。总分相同的,约定编号较小的选手排名靠前。
每轮比赛的对阵安排与该轮比赛开始前的排名有关:第1 名和第2 名、第 3 名和第 4名、……、第2K – 1 名和第 2K名、…… 、第2N – 1 名和第2N名,各进行一场比赛。每场比赛胜者得1 分,负者得 0 分。也就是说除了首轮以外,其它轮比赛的安排均不能事先确定,而是要取决于选手在之前比赛中的表现。
现给定每个选手的初始分数及其实力值,试计算在R 轮比赛过后,排名第 Q 的选手编号是多少。我们假设选手的实力值两两不同,且每场比赛中实力值较高的总能获胜。
输入输出格式
输入格式:
输入文件名为swiss.in 。
输入的第一行是三个正整数N、R 、Q,每两个数之间用一个空格隔开,表示有 2*N 名选手、R 轮比赛,以及我们关心的名次 Q。
第二行是2*N 个非负整数s1, s2, …, s2N,每两个数之间用一个空格隔开,其中 si 表示编号为i 的选手的初始分数。 第三行是2*N 个正整数w1 , w2 , …, w2N,每两个数之间用一个空格隔开,其中 wi 表示编号为i 的选手的实力值。
输出格式:
输出文件名为swiss.out。
输出只有一行,包含一个整数,即R 轮比赛结束后,排名第 Q 的选手的编号。
输入输出样例
输入样例#1:
2 4 2
7 6 6 7
10 5 20 15
输出样例#1:
1
说明
【样例解释】
【数据范围】
对于30% 的数据,1 ≤ N ≤ 100;
对于50% 的数据,1 ≤ N ≤ 10,000 ;
对于100%的数据,1 ≤ N ≤ 100,000,1 ≤ R ≤ 50,1 ≤ Q ≤ 2N,0 ≤ s1, s2, …, s2N≤10^8,1 ≤w1, w2 , …, w2N≤ 10^8。
noip2011普及组第3题。
【分析】
好题啊好题
裸sort会被卡掉…
我们发现每次比赛完以后两两分数会改变,但所有赢的人分数都+1,所有输的人分数都不变,所以赢的人与输的人分数仍然是排好序的,这时候要用到二路归并
【代码】
//NOIP 瑞士轮
#include<map>
#include<cmath>
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
#define ll long long
#define M(a) memset(a,0,sizeof a)
#define fo(i,j,k) for(i=j;i<=k;i++)
using namespace std;
const int mxn=200005;
struct node {int sco,id,w;}a[mxn],x[mxn],y[mxn];
int n,r,q;
inline bool comp(const node &t1,const node &t2)
{if(t1.sco==t2.sco) return t1.id<t2.id;return t1.sco>t2.sco;}
inline void merge_sort()
{
int i=1,j=1,cnt=0;
while(i<=n && j<=n)
{
cnt++;
if(x[i].sco>y[j].sco) a[cnt]=x[i++];
else if(x[i].sco<y[j].sco) a[cnt]=y[j++];
else if(x[i].id<y[j].id) a[cnt]=x[i++];
else a[cnt]=y[j++];
}
while(i<=n) a[++cnt]=x[i++];
while(j<=n) a[++cnt]=y[j++];
}
int main()
{
int i,j;
scanf("%d%d%d",&n,&r,&q);
fo(i,1,2*n) scanf("%d",&a[i].sco);
fo(i,1,2*n) scanf("%d",&a[i].w);
fo(i,1,2*n) a[i].id=i;
sort(a+1,a+n+n+1,comp);
while(r--)
{
int cnt=0;
fo(i,1,n)
{
if(a[2*i].w>a[2*i-1].w)
a[2*i].sco++,x[++cnt]=a[2*i],y[cnt]=a[2*i-1];
else
a[2*i-1].sco++,x[++cnt]=a[2*i-1],y[cnt]=a[2*i];
}
merge_sort();
}
printf("%d\n",a[q].id);
return 0;
}

相关文章推荐
- [NOIP2011]瑞士轮
- 【NOIP2011PJ】瑞士轮
- NOIP2011 瑞士轮
- NOIP 2011 普及组 第3题 瑞士轮
- NOIP2011瑞士轮
- Noip2011瑞士轮题解
- NOIP2011普及组 瑞士轮(分治)
- NOIP2011 瑞士轮 T3 归并排序
- Noip2011瑞士轮题解
- (NOIP 普及2011) 瑞士轮
- 【NOIP2011PJ】瑞士轮
- NOIP2011 普及组 T3 洛谷P1309 瑞士轮
- NOIP 2011 瑞士轮
- NOIP2011普及组 瑞士轮
- NOIP2011普及组 瑞士环 保序性
- 【NOIP2011普及组】瑞士轮
- 【NOIP2011】瑞士轮
- noip2011 瑞士轮 (归并排序)
- 【2011noip普及组】瑞士轮解题报告
- NOIp 2011 瑞士轮