推荐系统之隐语义模型(LFM)
2016-10-30 23:58
197 查看
一 基本概念
LFM(latent factor model)隐语义模型,这也是在推荐系统中应用相当普遍的一种模型。那这种模型跟ItemCF或UserCF有什么不同呢?这里可以做一个对比:
对于UserCF,我们可以先计算和目标用户兴趣相似的用户,之后再根据计算出来的用户喜欢的物品给目标用户推荐物品。
而ItemCF,我们可以根据目标用户喜欢的物品,寻找和这些物品相似的物品,再推荐给用户。
我们还有一种方法,先对所有的物品进行分类,再根据用户的兴趣分类给用户推荐该分类中的物品,LFM就是用来实现这种方法。
如果要实现最后一种方法,需要解决以下的问题:
(1)给物品分类
(2)确定用户兴趣属于哪些类及感兴趣程度
(3)对于用户感兴趣的类,如何推荐物品给用户
对分类,很容易想到人工对物品进行分类,但是人工分类是一种很主观的事情,比如一部电影用户可能因为这是喜剧片去看了,但也可能因为他是周星驰主演的看了,也有可能因为这是一部属于西游类型的电影,不同的人可以得到不同的分类。
而且对于物品分类的粒度很难控制,究竟需要把物品细分到个程度,比如一本线性代数,可以分类到数学中,也可以分类到高等数学,甚至根据线性代数主要适用的领域再一次细分,但对于非专业领域的人来说,想要对这样的物品进行小粒度细分无疑是一件费力不讨好的事情。
而且一个物品属于某个类,但是这个物品相比其他物品,是否更加符合这个类呢?这也是很难人工确定的事情。
对于上述需要解决的问题,我们的隐语义模型就派上用场了。隐语义模型,可以基于用户的行为自动进行聚类,并且这个类的数量,即粒度完全由可控。
对于某个物品是否属与一个类,完全由用户的行为确定,我们假设两个物品同时被许多用户喜欢,那么这两个物品就有很大的几率属于同一个类。
而某个物品在类所占的权重,也完全可以由计算得出。
以下公式便是隐语义模型计算用户u对物品i兴趣的公式:
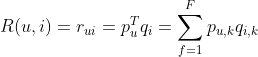
其中,p为用户兴趣和第k个隐类的关系,q为第k个隐类和物品i的关系,F为隐类的数量,r便是用户对物品的兴趣度。
接下的问题便是如何计算这两个参数p和q了,对于这种线性模型的计算方法,这里使用的是梯度下降法,详细的推导过程可以看一下我的另一篇博客。大概的思路便是使用一个数据集,包括用户喜欢的物品和不喜欢的物品,根据这个数据集来计算p和q。
下面给出公式,对于正样本,我们规定r=1,负样本r=0:

后面的lambda是为了防止过拟合的正则化项,下面给出python代码。
二 实战
我们这里依旧使用movielen的1M数据集
1 首先我们需要计算包含用户喜欢与不喜欢物品的数据集,采用不计算评分的隐反馈方式,只要用户评过分均认为用户对该物品有兴趣,而没有评分则可能没兴趣。
(1)用户正反馈数据
ace2
LFM(latent factor model)隐语义模型,这也是在推荐系统中应用相当普遍的一种模型。那这种模型跟ItemCF或UserCF有什么不同呢?这里可以做一个对比:
对于UserCF,我们可以先计算和目标用户兴趣相似的用户,之后再根据计算出来的用户喜欢的物品给目标用户推荐物品。
而ItemCF,我们可以根据目标用户喜欢的物品,寻找和这些物品相似的物品,再推荐给用户。
我们还有一种方法,先对所有的物品进行分类,再根据用户的兴趣分类给用户推荐该分类中的物品,LFM就是用来实现这种方法。
如果要实现最后一种方法,需要解决以下的问题:
(1)给物品分类
(2)确定用户兴趣属于哪些类及感兴趣程度
(3)对于用户感兴趣的类,如何推荐物品给用户
对分类,很容易想到人工对物品进行分类,但是人工分类是一种很主观的事情,比如一部电影用户可能因为这是喜剧片去看了,但也可能因为他是周星驰主演的看了,也有可能因为这是一部属于西游类型的电影,不同的人可以得到不同的分类。
而且对于物品分类的粒度很难控制,究竟需要把物品细分到个程度,比如一本线性代数,可以分类到数学中,也可以分类到高等数学,甚至根据线性代数主要适用的领域再一次细分,但对于非专业领域的人来说,想要对这样的物品进行小粒度细分无疑是一件费力不讨好的事情。
而且一个物品属于某个类,但是这个物品相比其他物品,是否更加符合这个类呢?这也是很难人工确定的事情。
对于上述需要解决的问题,我们的隐语义模型就派上用场了。隐语义模型,可以基于用户的行为自动进行聚类,并且这个类的数量,即粒度完全由可控。
对于某个物品是否属与一个类,完全由用户的行为确定,我们假设两个物品同时被许多用户喜欢,那么这两个物品就有很大的几率属于同一个类。
而某个物品在类所占的权重,也完全可以由计算得出。
以下公式便是隐语义模型计算用户u对物品i兴趣的公式:
其中,p为用户兴趣和第k个隐类的关系,q为第k个隐类和物品i的关系,F为隐类的数量,r便是用户对物品的兴趣度。
接下的问题便是如何计算这两个参数p和q了,对于这种线性模型的计算方法,这里使用的是梯度下降法,详细的推导过程可以看一下我的另一篇博客。大概的思路便是使用一个数据集,包括用户喜欢的物品和不喜欢的物品,根据这个数据集来计算p和q。
下面给出公式,对于正样本,我们规定r=1,负样本r=0:
后面的lambda是为了防止过拟合的正则化项,下面给出python代码。
二 实战
我们这里依旧使用movielen的1M数据集
1 首先我们需要计算包含用户喜欢与不喜欢物品的数据集,采用不计算评分的隐反馈方式,只要用户评过分均认为用户对该物品有兴趣,而没有评分则可能没兴趣。
(1)用户正反馈数据
def getUserPositiveItem(frame, userID): ''' 获取用户正反馈物品:用户评分过的物品 :param frame: ratings数据 :param userID: 用户ID :return: 正反馈物品 ''' series = frame[frame['UserID'] == userID]['MovieID'] positiveItemList = list(series.values) return positiveItemList(2)用户负反馈数据,根据用户无评分物品进行推荐,越热门的物品用户却没有进行过评分,认为用户越有可能对这物品没有兴趣
def getUserNegativeItem(frame, userID): ''' 获取用户负反馈物品:热门但是用户没有进行过评分 与正反馈数量相等 :param frame: ratings数据 :param userID:用户ID :return: 负反馈物品 ''' userItemlist = list(set(frame[frame['UserID'] == userID]['MovieID'])) #用户评分过的物品 otherItemList = [item for item in set(frame['MovieID'].values) if item not in userItemlist] #用户没有评分的物品 itemCount = [len(frame[frame['MovieID'] == item]['UserID']) for item in otherItemList] #物品热门程度 series = pd.Series(itemCount, index=otherItemList) series = series.sort_values(ascending=False)[:len(userItemlist)] #获取正反馈物品数量的负反馈物品 negativeItemList = list(series.index) return negativeItemList2 接下来是初始化参数p和q,这里我们采用随机初始化的方式,将p和q取值在[0,1]之间:
def initPara(userID, itemID, classCount): ''' 初始化参数q,p矩阵, 随机 :param userCount:用户ID :param itemCount:物品ID :param classCount: 隐类数量 :return: 参数p,q ''' arrayp = np.random.rand(len(userID), classCount) arrayq = np.random.rand(classCount, len(itemID)) p = pd.DataFrame(arrayp, columns=range(0,classCount), index=userID) q = pd.DataFrame(arrayq, columns=itemID, index=range(0,classCount)) return p,q3 定义函数计算用户对物品的兴趣
def lfmPredict(p, q, userID, itemID): ''' 利用参数p,q预测目标用户对目标物品的兴趣度 :param p: 用户兴趣和隐类的关系 :param q: 隐类和物品的关系 :param userID: 目标用户 :param itemID: 目标物品 :return: 预测兴趣度 ''' p = np.mat(p.ix[userID].values) q = np.mat(q[itemID].values).T r = (p * q).sum() r = sigmod(r) return r def sigmod(x): ''' 单位阶跃函数,将兴趣度限定在[0,1]范围内 :param x: 兴趣度 :return: 兴趣度 ''' y = 1.0/(1+exp(-x)) return y4 隐语义模型,利用梯度下降迭代计算参数p和q
def latenFactorModel(frame, classCount, iterCount, alpha, lamda):
'''
隐语义模型计算参数p,q
:param frame: 源数据
:param classCount: 隐类数量
:param iterCount: 迭代次数
:param alpha: 步长
:param lamda: 正则化参数
:return: 参数p,q
'''
p, q, userItem = initModel(frame, classCount)
for step in range(0, iterCount):
for user in userItem:
for userID, samples in user.items():
for itemID, rui in samples.items():
eui = rui - lfmPredict(p, q, userID, itemID)
for f in range(0, classCount):
print('step %d user %d class %d' % (step, userID, f))
p[f][userID] += alpha * (eui * q[itemID][f] - lamda * p[f][userID])
q[itemID][f] += alpha * (eui * p[f][userID] - lamda * q[itemID][f])
alpha *= 0.9
return p, q5 最后根据计算出来的p和q参数对用户进行物品的推荐def recommend(frame, userID, p, q, TopN=10): ''' 推荐TopN个物品给目标用户 :param frame: 源数据 :param userID: 目标用户 :param p: 用户兴趣和隐类的关系 :param q: 隐类和物品的关系 :param TopN: 推荐数量 :return: 推荐物品 ''' userItemlist = list(set(frame[frame['UserID'] == userID]['MovieID'])) otherItemList = [item for item in set(frame['MovieID'].values) if item not in userItemlist] predictList = [lfmPredict(p, q, userID, itemID) for itemID in otherItemList] series = pd.Series(predictList, index=otherItemList) series = series.sort_values(ascending=False)[:TopN] return series隐语义模型介绍就到这里了,完整的项目代码可以到我的个人github上面查看:https://github.com/lpty
ace2

相关文章推荐
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 推荐系统-基于隐语义模型(LFM)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 推荐系统之隐语义模型(LFM)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)
- 实战智能推荐系统(10)-- 隐语义模型 LFM (Funk-SVD)