HDFS数据快速拷贝方案:FastCopy
2016-10-30 11:07
295 查看
前言
我们在使用HDFS的时候,往往有的时候需要做一些临时的数据拷贝操作,如果是在同一个集群中的,我们直接用HDFS内部自带的cp这些命令即可;如果是跨集群的时候或者说待拷贝数据量规模非常大的时候,我们还可以使用DistCp工具。但是这是否意味着我们使用这些工具在拷贝数据的时候依然是高效的呢?答案其实并不是这样的。在许多比较早使用Hadoop的公司,估计都或多或少遇到过拷贝大规模数据效率不高的情况。比如说,FaceBook在其内部的Hadoop版本中开发了一种叫做FastCopy的数据快速拷贝工具。目前在JIRA上也有相应的记录:HDFS-2139(Fast copy for HDFS)。本节我们要讲述的主题正是FastCopy工具。FastCopy的原理介绍
FastCopy与传统的数据拷贝之间的一个主要不同点在于它尽可能地让数据拷贝发生在本地,以此减少跨节点间的数据传输。并且在FastCopy的本地数据拷贝过程中,还能通过对文件创建一个新的硬链接的方式,而无须做真正的数据拷贝操作。HDFS硬链接的相关内容可以阅读本人之前的一篇文章:HDFS符号链接和硬链接。HDFS内部的硬链接在FaceBook内部也已经早已实现。下面我们来学习FastCopy快速拷贝工具的一个主要原理:
1)查询待拷贝文件的所有block块信息。
2)获取这些源文件块信息所在的位置信息。
3)对于源文件的每个块,在NameNode内部对应创建一个空的目标块,这些目标块的存储位置尽可能与源块最后一致。
4)然后命令DataNode做一个本地的块拷贝操作。
5)然后等待块拷贝完成操作,然后上报到NameNode上。
对于上述过程中的第4步,可以直接利用硬链接来做。OK,这里的过程是一个FastCopy工具拷贝数据内部的过程,那么我们从大一点的角度来观察,FastCopy工具的总流程是怎样的呢,答案如下:
1.首先输入待拷贝的目标路径,这里可以为纯文件或目录。
2.第一步骤中输入的路径会转化为一个个FastCopy的请求。
3.这些请求会提交到一个线程池中去执行。
4.根据拷贝过程中的源块,目标块的所在节点位置,分别执行普通方式的DataCopy或是本地方式的LocalCopy两种拷贝操作。
此过程原理图如图1-1所示。
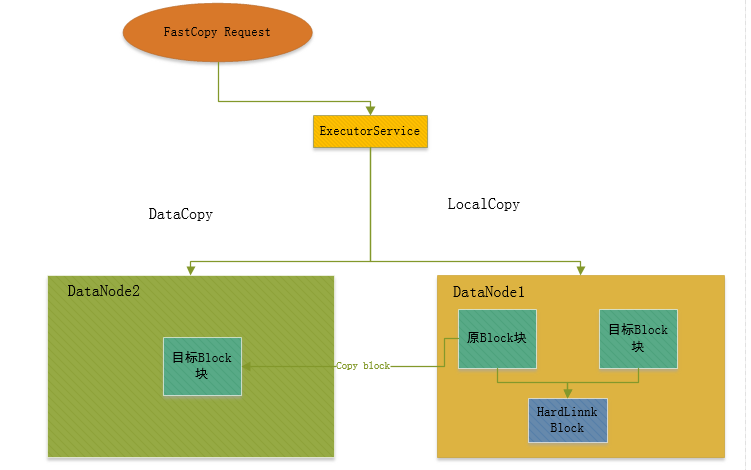
图 1-1 FastCopy数据拷贝过程
FastCopy原理部分的内容主要在于上面2点。上面的步骤细节大家在后面的关键代码分析中可以进行对应地查找。
FastCopy核心代码分析
在核心代码分析部分,我们将主要关注2个模块的实现:FastCopy工具如何尽可能地让块在本地进行复制。
FastCopy在数据拷贝时具体是如何执行的。
首先是第一个点的内容:在FastCopy中,是如何保证块尽量在本地复制呢?要想解答这个问题,我们先回到之前FastCopy的快速拷贝原理,其中有这么一个过程:
对于源文件的每个块,在NameNode内部对应创建一个空的目标块,这些目标块的存储位置尽可能与源块最后一致。
在这步过程的执行时,会将查询到的源块的位置信息优先作为目标创建块的位置信息。这样就保证了目标拷贝块和源快是在同一个节点上了。这里为什么指明说是优先呢,而不是绝对肯定的说法呢?因为这里还要考虑到目标盘上的存储空间够不够用的问题,如果目标存储的盘的可用空间不足,那么这个位置将不可用。然后NameNode将会选择下一个存储位置。
此部分代码如下:
/**
* Copy the file.
* @return result of the operation
*/
private CopyResult copy() throws Exception {
// 获取源文件信息,并准备创建空目标文件
HdfsFileStatus srcFileStatus = srcNamenode.getFileInfo(src);
if (srcFileStatus == null) {
throw new FileNotFoundException("File : " + src + " does not exist");
}
LOG.info("Start to copy " + src + " to " + destination);
try {
...
LinkedList<LocatedBlock> blocksList = new LinkedList<LocatedBlock>();
LocatedBlock previousAdded = null;
do {
lastStart = lastEnd;
// 获取源文件的块对象
LocatedBlocks blocks = srcNamenode.getBlockLocations(src, lastStart, addition);
...
lastEnd = lastBlock.getStartOffset() + lastSize;
// 遍历此文件的块对象列表
for (LocatedBlock lb : blocks.getLocatedBlocks()) {
if (previousAdded == null
|| !previousAdded.getBlock().equals(lb.getBlock())) {
// 将块对象加入到块链表最后
blocksList.add(lb);
previousAdded = lb;
}
}
} while (lastEnd < fileLen);
...
EnumSetWritable<CreateFlag> flagWritable = new EnumSetWritable<CreateFlag>(flag);
// 在NameNode内部创建目标文件
HdfsFileStatus dstFileStatus = dstNamenode.create(destination, srcFileStatus.getPermission(),
clientName, flagWritable, true,
srcFileStatus.getReplication(), srcFileStatus.getBlockSize(),
CryptoProtocolVersion.supported());
// Instruct each datanode to create a copy of the respective block.
int blocksAdded = 0;
ExtendedBlock previous = null;
LocatedBlock destinationLocatedBlock = null;
// Loop through each block and create copies.
// 遍历之前源文件块列表
for (LocatedBlock srcLocatedBlock : blocksList) {
UserGroupInformation.getCurrentUser().addToken(srcLocatedBlock.getBlockToken());
String[] favoredNodes = new String[srcLocatedBlock.getLocations().length];
// 获取源文件块的位置信息
for (int i = 0; i < srcLocatedBlock.getLocations().length; i++) {
favoredNodes[i] = srcLocatedBlock.getLocations()[i].getHostName()
+ ":" + srcLocatedBlock.getLocations()[i].getXferPort();
}
LOG.info("favoredNodes for " + srcLocatedBlock + ":"
+ Arrays.toString(favoredNodes));
for (int sleepTime = 2000, retries = 10; retries > 0; retries -= 1) {
try {
// 在NameNode最后创建新的目标块,以之前的源文件块的位置信息传入,作为优先选择的存储位置
destinationLocatedBlock = dstNamenode.addBlock(destination,
clientName, previous, null, dstFileStatus.getFileId(),
favoredNodes);
break;
} catch (RemoteException e) {
...
}
if (destinationLocatedBlock == null) {
throw new IOException("get null located block from namendoe");
}
blocksAdded++;
// 拷贝真实数据
copyBlock(srcLocatedBlock, destinationLocatedBlock);
// 等待数据的拷贝
waitForBlockCopy(blocksAdded);
...
}
terminateExecutor();
// Wait for all blocks of the file to be copied.
waitForFile(src, destination, previous, dstFileStatus.getFileId());
} catch (IOException e) {
LOG.error("failed to copy src : " + src + " dst : " + destination, e);
// 如果此过程发生IO异常,则清除此次目标文件
dstNamenode.delete(destination, false);
throw e;
} finally {
shutdown();
}
return CopyResult.SUCCESS;
}接下来我们来看第二个关键部分的内容,DataNode节点上如何实现快速拷贝,假设此时前面在NameNode创建块的动作都已经完成了,最后就差DataNode节点的块复制操作。
FastCopy的复杂请求,最后触发到DataNode的对应方法copyBlock方法,代码如下:
public void copyBlock(ExtendedBlock src, ExtendedBlock dst, DatanodeInfo dstDn)
throws IOException {
...
long onDiskLength = data.getLength(src);
// 复制之前判断当前源块的长度是否一致,以此判断块是否损坏
if (src.getNumBytes() > onDiskLength) {
// Shorter on-disk len indicates corruption so report NN the corrupt block
String msg = "copyBlock: Can't replicate block " + src
+ " because on-disk length " + onDiskLength
+ " is shorter than provided length " + src.getNumBytes();
LOG.info(msg);
throw new IOException(msg);
}
LOG.info(getDatanodeInfo() + " copyBlock: Starting thread to transfer: " +
"block:" + src + " from " + this.getDatanodeUuid() + " to " + dstDn.getDatanodeUuid() +
"(" +dstDn + ")");
Future<?> result;
// 判断目标块的节点位置与源块节点是否一致
if (this.getDatanodeUuid().equals(dstDn.getDatanodeUuid())) {
// 如果是同一个节点,则是一次本地拷贝
result = blockCopyExecutor.submit(new LocalBlockCopy(src, dst));
} else {
// 否则,则是普通的一次数据拷贝
result = blockCopyExecutor.submit(new DataCopy(dstDn, src, dst));
}
try {
// 等待拷贝过程5分钟
result.get(5 * 60, TimeUnit.SECONDS);
} catch (Exception e) {
LOG.error(e);
throw new IOException(e);
}
}从上面的执行过程,我们可以看出,最后是2类方式的拷贝:LocalBlockCopy和DataCopy。
首先是LocalBlockCopy的本地拷贝方式,代码如下:
class LocalBlockCopy implements Callable<Boolean> {
// 源块
private ExtendedBlock srcBlock = null;
// 目标块
private ExtendedBlock dstBlock = null;
...
public Boolean call() throws Exception {
try {
dstBlock.setNumBytes(srcBlock.getNumBytes());
// 对源块创建一个新的硬链接
data.hardLinkOneBlock(srcBlock, dstBlock);
FsVolumeSpi v = (FsVolumeSpi)(getFSDataset().getVolume(dstBlock));
// 关闭块操作
closeBlock(dstBlock, DataNode.EMPTY_DEL_HINT, v.getStorageID());
...
} catch (Exception e) {
LOG.warn("Local block copy for src : " + srcBlock.getBlockName()
+ ", dst : " + dstBlock.getBlockName() + " failed", e);
throw e;
}
return true;
}
}还有一种是普通方式的拷贝,会有节点间的数据传输,代码如下:
private class DataCopy implements Runnable {
// 目标块所在节点
final DatanodeInfo target;
// 源块
final ExtendedBlock src;
// 目标块
final ExtendedBlock dst;
...
@Override
public void run() {
...
try {
final String dnAddr = target.getXferAddr(connectToDnViaHostname);
InetSocketAddress curTarget = NetUtils.createSocketAddr(dnAddr);
if (LOG.isDebugEnabled()) {
LOG.debug("Connecting to datanode " + dnAddr);
}
// 首先与目标节点建立连接的过程
sock = newSocket();
NetUtils.connect(sock, curTarget, dnConf.socketTimeout);
sock.setSoTimeout(dnConf.socketTimeout);
...
long writeTimeout = dnConf.socketWriteTimeout;
OutputStream unbufOut = NetUtils.getOutputStream(sock, writeTimeout);
InputStream unbufIn = NetUtils.getInputStream(sock);
DataEncryptionKeyFactory keyFactory =
getDataEncryptionKeyFactoryForBlock(dst);
IOStreamPair saslStreams = saslClient.socketSend(sock, unbufOut,
unbufIn, keyFactory, accessToken, bpReg);
unbufOut = saslStreams.out;
unbufIn = saslStreams.in;
// 新建输入、输出流对象
out = new DataOutputStream(new BufferedOutputStream(unbufOut,
HdfsConstants.SMALL_BUFFER_SIZE));
in = new DataInputStream(unbufIn);
blockSender = new BlockSender(src, 0, src.getNumBytes(),
false, false, true, DataNode.this, null, cachingStrategy);
DatanodeInfo srcNode = new DatanodeInfo(bpReg);
// 执行写块操作
new Sender(out).writeBlock(dst, StorageType.DEFAULT, accessToken,
"", new DatanodeInfo[] {target}, new StorageType[] {StorageType.DEFAULT}, srcNode,
BlockConstructionStage.PIPELINE_SETUP_CREATE,
0, 0, 0, 0, blockSender.getChecksum(), cachingStrategy,
false, false, null);
// 用blockSender对象读取本地数据,并传输数据到目标节点中
blockSender.sendBlock(out, unbufOut, null);
...
} catch (IOException ie) {
LOG.warn(bpReg + ":Failed to transfer " + src + " to " +
target + " " + dst + " got ", ie);
// check if there are any disk problem
checkDiskErrorAsync();
} finally {
// 关闭各个对象
xmitsInProgress.getAndDecrement();
IOUtils.closeStream(blockSender);
IOUtils.closeStream(out);
IOUtils.closeStream(in);
IOUtils.closeSocket(sock);
}
}
}如果前面本地拷贝中的硬链接功能不用的话,本人觉得这个DataCopy的方式同样是可以复用的。
以上部分代码只是FastCopy工具代码中的一部分,详细代码可以查阅本文末尾的参考资料。
以上就是本文的全部的内容了,希望大家能够好好体会FastCopy是如何让块尽量地在本地进行拷贝的,这是很核心的一个点。
参考资料
[1].Fast copy for HDFS[2].https://issues.apache.org/jira/secure/attachment/12784877/HDFS-2139-For-2.7.1.patch

相关文章推荐
- ASP.NET2.0快速入门--高级数据方案(3)
- ASP.NET2.0快速入门--高级数据方案(4)
- Avro技术应用_5. 利用 Camus 来将 Avro 数据从 Kafka 拷贝到 HDFS -- 待完善
- ViewFs----HDFS跨集群数据合并方案之ViewFileSystem
- 如何快速把hdfs数据动态导入到hive表
- ASP.NET2.0快速入门系列--高级数据方案(上)
- mysql通过拷贝文件实现数据快速迁移实例
- 大数据平台监控(一):Ganglia在集群中快速安装方案【内含通过yum只下载不安装,需要安装一个yum的插件】
- Spark,一种快速数据分析替代方案
- 如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案!(zz)
- 文件快速拷贝工具FastCopy 使用教程
- Spark,一种快速数据分析替代方案
- WebMatrix教程(五) (快速建立数据图表的方案)
- 如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案!
- 如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案!
- ASP.NET2.0快速入门--高级数据方案(4)
- 如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案!(zz)
- hdfs to hbase 快速导入数据
- HDFS跨集群数据合并方案之ViewFileSystem
- logstash传输自定义字段数据到hdfs进行分年月日分区,并且hive可以通过hiveQL快速查询数据