MSCNN 论文解析(A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
2016-10-26 15:24
1801 查看
转载来自:http://blog.csdn.net/ture_dream/article/details/52750565
最新看篇关于多尺度下快速目标检测的论文,是UCSD大学的SVCL实验室和IBM研究院一起研究的结果。其代码已经开源到GitHub,链接为:https://github.com/zhaoweicai/mscnn
跑mscnn ;软硬件需求:
linux 测试需要4G以上显存,训练12G以上
cuda 7.5
cudnn v3(v4不行)
matlab 2014a
(1)针对多尺度问题:
类似于FCNT跟踪方法,该文章也是观察到了卷积网络不同层得到的特征特点的不同,对不同层的特征采用不同的利用方式。比如conv-3的低网络层,有更小的感受野,可以进行小目标的检测;而高层如conv-5,对于大目标的检测更加准确。对于不同的输出层设计不同尺度的目标检测器,完成多尺度下的检测问题。
注: 在卷积神经网络中,感受野的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点 在原始图像上映射的区域大小。点击打开链接
(2)针对速度问题:
使用特征的上采样代替输入图像的上采样步骤。设计一个去卷积层,来增加特征图的分辨率,使得小目标依然可以被检测出来。这里使用了特征图的deconvolutional layer(去卷积层)来代替input图像的上采样,可以大大减少内存占用,提高速度。
作者说:去卷积层一直用于分隔和边缘检测,我们第一次用它加速和提高检测率。
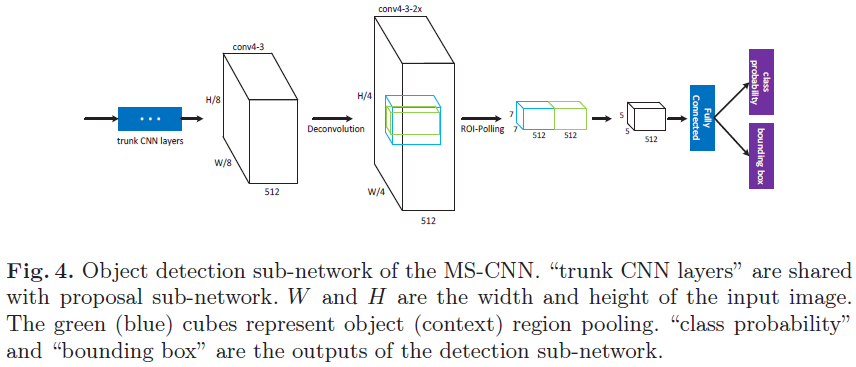
proposal子网络和目标检测子网络结构图分别如下:
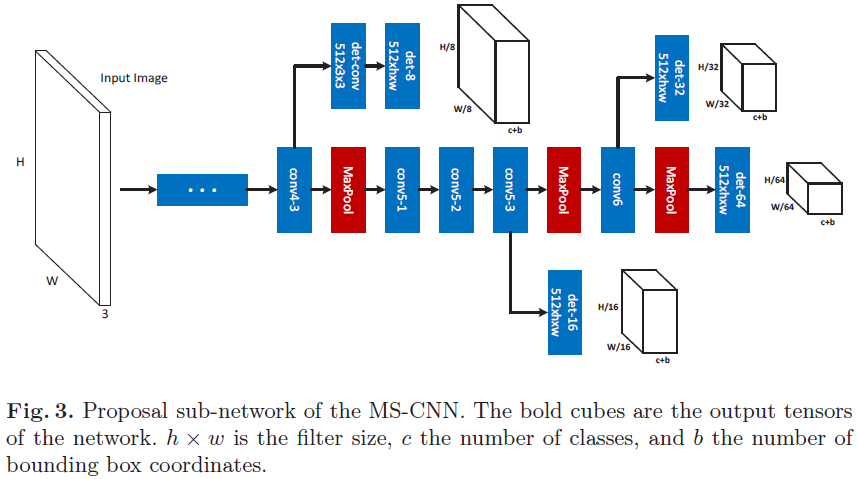
注:中间有色部分可以看成CNN trunk(cnn 主干线),一些层延伸了分支,分支由单检测层构成,通过分支的proposal判断为最终proposal。
技巧一:Conv4-3上面有一个缓冲卷积层,因为这一次更靠近主干线的底层(接近输入图),更影响梯度导致学习过程不稳定,缓冲卷积层能防止检测分支的梯度直接反向传播回主干线层。
数据扩展: 在KITTI数据集中,大多数目标很小,候选集差别很大,而最大目标尺寸过小,故把原始图像随机缩放成多个规模。
精调: 图像背景区域消耗计算内存,故在1000*600的大图里裁剪448*448的含目标图片,是12G显存够用
训练技巧: booststrapping 和multi-task loss 使训练在早期迭代过程不稳定,采用两步走,
第一步:随机采样,以学习率0.00005迭代10000次,生成模型
第二部:用生成的模型初始化第二层,自举,以初始学习率0.00005迭代,每迭代一万次学习率下降十倍,一共迭代 25000次。
测试评估:
KITTI数据集包含三类:car pedestrian cyclist,和三个水平评估:easy moderate hard。一共7518测试图(无ground truth标签),一共7481图片用于train/validation,采用脱离实验,将7481图片分为train和validation集(用来评估)。
文章主要在KITTI和Caltech Pedestrian数据集上进行了MSCNN的测试,因为这两个数据集中包含许多小目标。
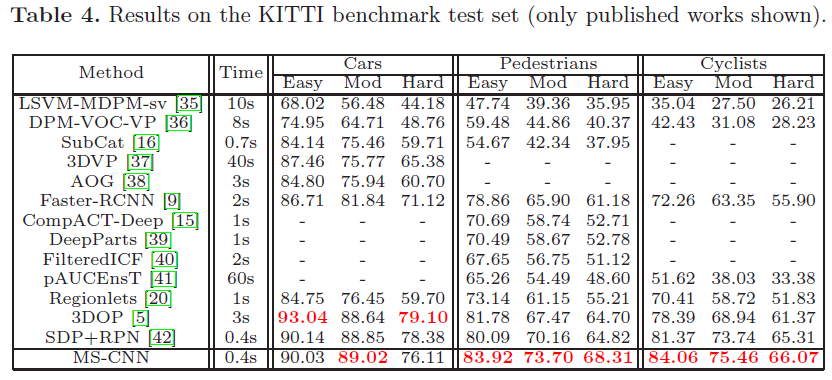
作者对proposal网络部分和目标检测部分的实验结果分别进行了全部系统的分析和对比,这里仅仅将在KITTI上的检测结果展示:
参考:http://blog.csdn.net/u012905422/article/details/52453819?locationNum=15
最新看篇关于多尺度下快速目标检测的论文,是UCSD大学的SVCL实验室和IBM研究院一起研究的结果。其代码已经开源到GitHub,链接为:https://github.com/zhaoweicai/mscnn
跑mscnn ;软硬件需求:
linux 测试需要4G以上显存,训练12G以上
cuda 7.5
cudnn v3(v4不行)
matlab 2014a
这篇文章主要解决多尺度同时存在时的检索问题,设计了MSCNN网络,提出了两点创新和几点技巧:
(1)针对多尺度问题:类似于FCNT跟踪方法,该文章也是观察到了卷积网络不同层得到的特征特点的不同,对不同层的特征采用不同的利用方式。比如conv-3的低网络层,有更小的感受野,可以进行小目标的检测;而高层如conv-5,对于大目标的检测更加准确。对于不同的输出层设计不同尺度的目标检测器,完成多尺度下的检测问题。
注: 在卷积神经网络中,感受野的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点 在原始图像上映射的区域大小。点击打开链接
(2)针对速度问题:
使用特征的上采样代替输入图像的上采样步骤。设计一个去卷积层,来增加特征图的分辨率,使得小目标依然可以被检测出来。这里使用了特征图的deconvolutional layer(去卷积层)来代替input图像的上采样,可以大大减少内存占用,提高速度。
作者说:去卷积层一直用于分隔和边缘检测,我们第一次用它加速和提高检测率。
文章的网络结构类似RCNN,分为proposal提取和目标检测,两个部分独立进行。
proposal子网络和目标检测子网络结构图分别如下:注:中间有色部分可以看成CNN trunk(cnn 主干线),一些层延伸了分支,分支由单检测层构成,通过分支的proposal判断为最终proposal。
技巧一:Conv4-3上面有一个缓冲卷积层,因为这一次更靠近主干线的底层(接近输入图),更影响梯度导致学习过程不稳定,缓冲卷积层能防止检测分支的梯度直接反向传播回主干线层。
实验细节:
数据扩展: 在KITTI数据集中,大多数目标很小,候选集差别很大,而最大目标尺寸过小,故把原始图像随机缩放成多个规模。精调: 图像背景区域消耗计算内存,故在1000*600的大图里裁剪448*448的含目标图片,是12G显存够用
训练技巧: booststrapping 和multi-task loss 使训练在早期迭代过程不稳定,采用两步走,
第一步:随机采样,以学习率0.00005迭代10000次,生成模型
第二部:用生成的模型初始化第二层,自举,以初始学习率0.00005迭代,每迭代一万次学习率下降十倍,一共迭代 25000次。
测试评估:
KITTI数据集包含三类:car pedestrian cyclist,和三个水平评估:easy moderate hard。一共7518测试图(无ground truth标签),一共7481图片用于train/validation,采用脱离实验,将7481图片分为train和validation集(用来评估)。
实验过程与结果:
文章主要在KITTI和Caltech Pedestrian数据集上进行了MSCNN的测试,因为这两个数据集中包含许多小目标。作者对proposal网络部分和目标检测部分的实验结果分别进行了全部系统的分析和对比,这里仅仅将在KITTI上的检测结果展示:
参考:http://blog.csdn.net/u012905422/article/details/52453819?locationNum=15

相关文章推荐
- MSCNN 论文解析(A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- [论文解读] MSCNN: A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- 论文笔记 MSCNN:A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- 多尺度R-CNN论文笔记(5): A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- 目标检测--A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
- A Hierarchical Deep Convolutional Neural Network for Fast Artistic Style Transfer论文理解
- DeepID-Net:multi-stage and deformable deep convolutional neural network for object detection
- 【论文笔记】A Convolutional Neural Network Cascade for Face Detection
- 论文阅读:Deep Neural Networks for Object Detection
- Deep Saliency:Multi_Task Deep Neural Network Model for Salient object detection
- Single-Shot Refinement Neural Network for Object Detection-论文笔记
- 多尺度R-CNN论文笔记(4): PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
- 论文阅读--PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
- PVANET----Deep but Lightweight Neural Networks for Real-time Object Detection论文记录
- 论文阅读-《Deformable Part-based Fully Convolutional Network for Object Detection》
- 【论文笔记】Deep Neural Networks for Object Detection
- 论文《A Convolutional Neural Network Cascade for Face Detection》笔记
- 论文阅读(Weilin Huang——【TIP2016】Text-Attentional Convolutional Neural Network for Scene Text Detection)
- 论文《A Convolutional Neural Network Cascade for Face Detection》笔记
- 【深度学习论文笔记:Recognition】:Deep Neural Networks for Object Detection