从上下文无关文法(CFG)到语法分析树——SLR(1)分析法
2016-10-24 18:02
357 查看
LR方法
LR parsing是一种相对于LL更通用的方法,LR parser是高效的、自底向上的用于上下文无关文法的语法分析技术。LR(k)方法中的L、R、K分别代表:
L: left-to-right scan从左向右扫描
R:construct a rightmost derivation in reverse最右推导
k:the number of input symbols of look ahead每次扫描的字符数
LR方法分为三种:
SLR: simple LR 简单LR方法,本文介绍的就是简单LR(1)方法
LR(1): canonical LR 规范LR方法
LALR: look ahead LR
更多关于LL语法的分析方法,如预测分析法,可以查看这里。
本文例:
E => E + T
E => T
T => T * F
T => F
F => ( E )
F => i
构造自动机
首先为每个产生式构造自己的状态机。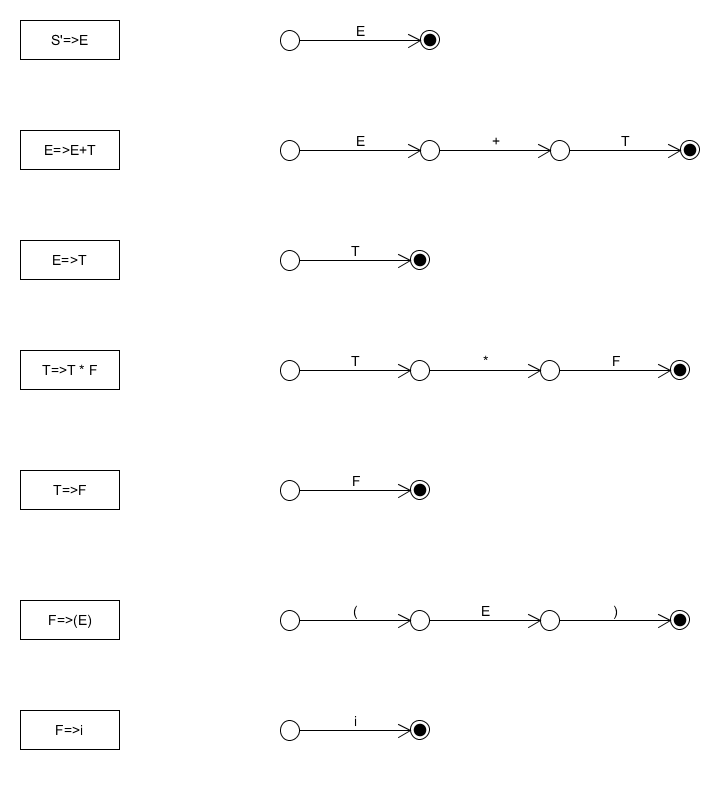
首先,我们需要理解这些状态机的含义。每个状态机都描述了每个产生式推导过程需要的状态转换。这样的转换是分层的。比如T=>T+F这个状态转换,当进行到最后F那一步时,可以直接通过i来转换,也可以通过(E)来转换,就是最后的那两个表达式,每个以非终结符为发出边的状态转换,如E、F等,都意味这样的转换需要分解为更细化的转换,而这些“更细化的转换”,都在后面定义了,如对于F有F=>(E)和F=>i。
因此,我们连出具体的分解状态。

(注:空白边都是指ϵ边)
我们完全不需要去细看图中的每条线(其实可以不画这张图),但是我们需要理解的是状态间的分层关系,即每个非终止符构成的发出边一定可以分解,分解的方式就是以这个非终止符为左边的推导式。因为每个推导式都被转化为状态机,这就意味着它可以分解为对应的更细化的状态。
Q:为什么有S’=>E这个状态存在?
A:
为了有一个共同的起点。因为一开始E => E + T,E => T是并列的一层,需要定义一个公共的起点。
生成DFA
Step1:State naming 命名状态
在之前我们直接把状态命名为1、2、3、4等,在这里这样简单的命名不能体现分层的特征,如何既能体现分层,又能具体标明以上图中每个具体的状态呢?我们的解决方案是:用产生式命名层,用点表示位置。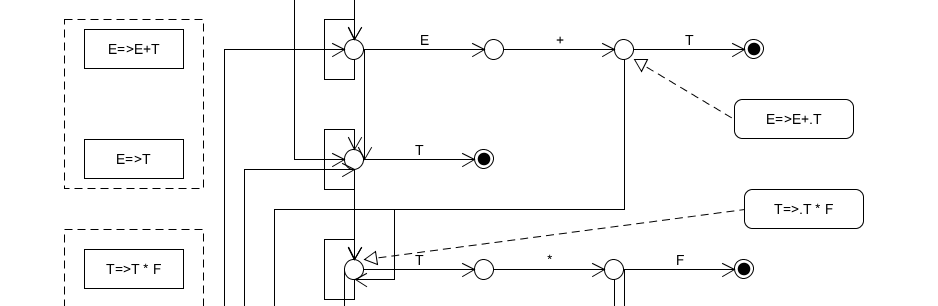
两个命名示例如上图所示。
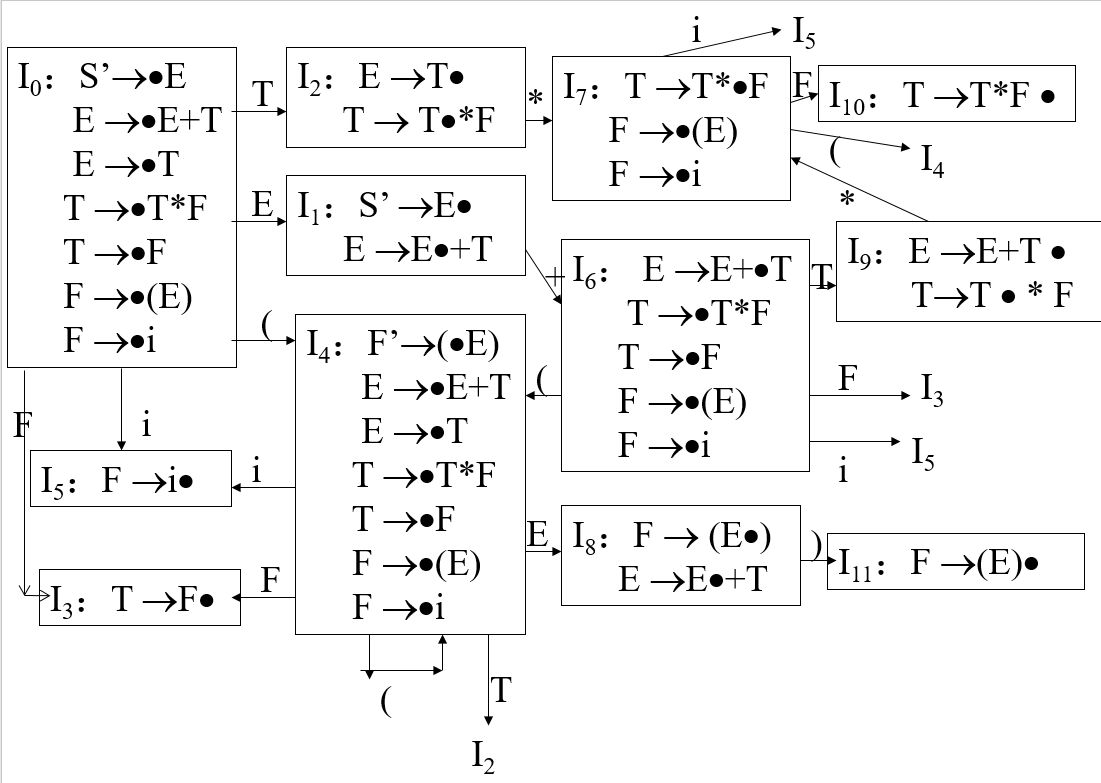
Step2:Determination 将NFA转化为LRDFA
在之前的文章中,我们提到了如何将NFA转化为DFA,使用的是表驱动法,当时提到了两个概念:ϵ闭包和子集构造法。在这里我们列出这种方法的特色部分。ϵ闭包->状态内扩展
如何寻找开始状态S’=>.E的“ϵ闭包”?方法是如果有一个点在非终结符的前面,那么该非终结符为左边的产生式对应的第一个状态也要加入这个新的状态。说人话就是,对于S’=>.E,点在E的前面,则E=>.E+T和E=>.T就加入S’=>.E的ϵ闭包,这是一个递归的过程,E=>.T里点在T的前面,则T=>.T*F和T=>.F也加入S’=>.E的ϵ闭包,然后再找F…我们为这种方法找一个新的名字叫做状态内扩展,当然这只是更简便的做法,用之前ϵ闭包的方法完全可以找到相同的结果。
子集构造法->状态间扩展
与之前不同的是,这里非终结符构成的发出边也要考虑。而寻找子集的方法更简单,只要将对应的点右移即可。如T=>.T*F从T发出的状态就是T=>T.*F,同样,这里用之前子集构造法一样可以解决,只是这种命名方法为转化DFA提供了很大的便利。
下图是完整的LRDFA图:
构造LR分析表
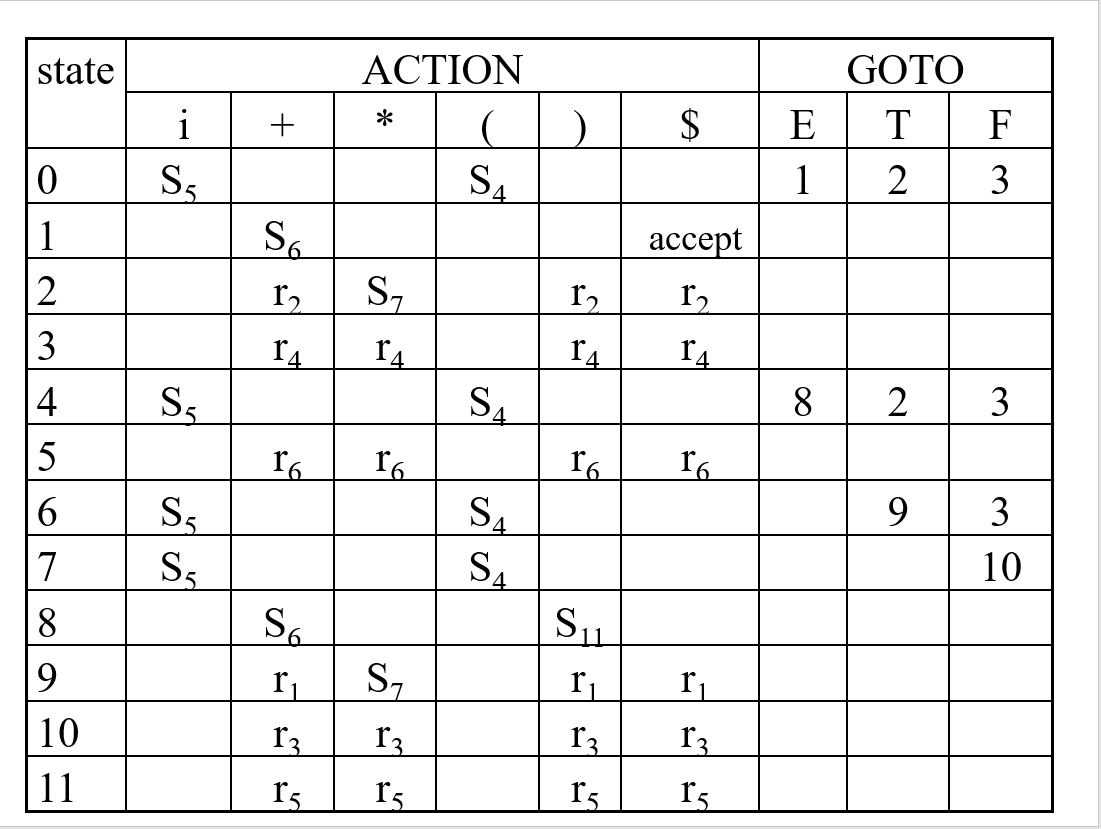
Action里的S和GOTO里的数字都很好填,直接按照上面生成的状态转换填写即可,如I0通过发出边T到I2,则在state0行T列写2,I0通过发出边i到I5,则在state0行i列写S5(Shift5)。这里要解释的是r(Reduce)的填写。
REDUCE
首先为所有产生式标号:
(0)S’=>E
(1)E => E + T
(2)E => T
(3)T => T * F
(4)T => F
(5)F => ( E )
(6)F => i
随后,观察每一个具体的状态。如果有一个状态中包含终止状态(即点在最右边),意味着这个子状态分析完毕,需要进行规约。我们就需要对这个推导求Follow(Follow是什么见上一篇文章)。
比如说,对于I2, 有E=>T.这个状态,这里点在T后面,也就是最后,我们需要对E求Follow,可以知道E的Follow为+和(和$,所以我们在state2的+、(、$列填上r2,这里的2的意思是产生规约的是第二个产生式E=>T。
分析过程
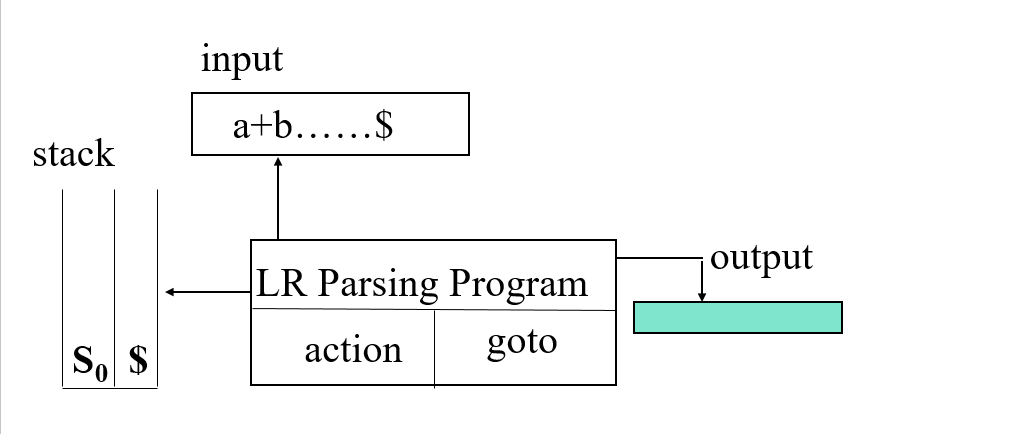
LR Parsing模型和之前的有一点区别,最大区别就是左边的栈有两列,最左边一列用于存放当前的状态,右边一列用来存放临时的字符和状态。
若当前状态与字符指针所指字符在LR表中对应一个ACTION的Shift(就是Si,状态转换),则把这个字符压栈,因为每次压栈时要同时压入字符和状态,此时压入的对应的状态就是ACTION里标明的状态,同时字符指针右移。
关键:若当前状态与字符指针所指字符在LR表中对应一个ACTION的Reduce(即Ri),首先查看Ri对应的产生式,比如说F=>E+F,此时则需要弹出栈中的E+F(如果步骤顺利,那此时栈中已经有了E,+和F),把F压栈,与F同时压栈的状态为当前的状态(都弹出以后下面一行的状态)与F在LR表中对应的GOTO,如果当前状态为0,那么与F一起压栈的状态就是(0,F)对应的GOTO状态。
弹栈时字符要与状态一起弹出。
R0的意思是Accept,即分析成功结束。
PS:有空会画出每一步的栈图
PS:写这个花的时间实在太长了,真的是从周一写到周五,还有三节课不一定每节课都更啦!

相关文章推荐
- 从上下文无关文法(CFG)到语法分析树——LL(1)分析法
- 3.2语法分析-上下文无关文法
- 【现代编译器】语法分析——正则表达式,上下文无关文法,递归下降分析,分析树
- 【现代编译器】语法分析——正则表达式,上下文无关文法,递归下降分析,分析树
- 自然语言 和编译原理中的(1型文法)上下文有关文法和(2型文法)上下文无关文法CFG
- 文法系列之从上下文无关语法到转换语法
- 【语言处理与Python】8.2文法有什么用?\8.3上下文无关文法\8.4上下文无关文法分析
- 到底什么是上下文无关文法(CFG)?
- 文法系列之从上下文无关语法到转换语法
- 文法系列之上下文无关语法简介
- 上下文无关文法(Content-Free Grammar, CFG)
- [系列][编译原理]上下文无关文法及分析
- 上下文无关文法(CFG)
- 文法系列之上下文无关语法简介
- 【CT】三、上下文无关文法,CFG,PDA
- 上下文无关文法及分析
- 上下文无关文法及其分析树
- 词汇化概率上下文无关文法 Lexicalized PCFGs
- 2-型文法消除左递归算法(上下文无关文法)
- 上下文无关文法