Spark计算引擎原理
2016-10-21 23:03
513 查看
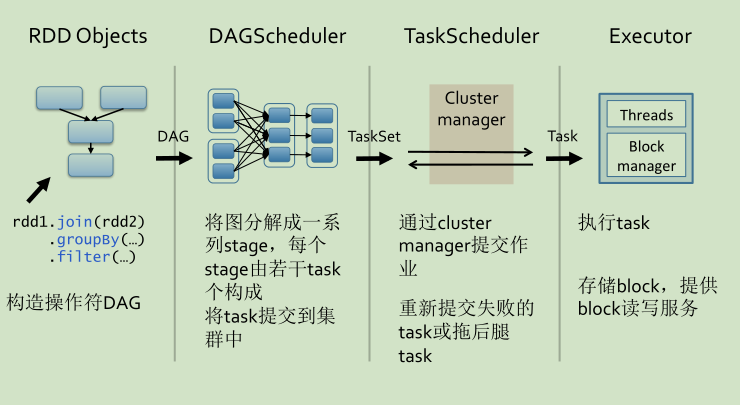
一、Spark内部原理
——通过RDD,创建DAG(逻辑计划)
——为DAG生成物理查询计划
——调用并执行Task
二、生成逻辑执行图:产生RDD
生成RDD的DAG图。
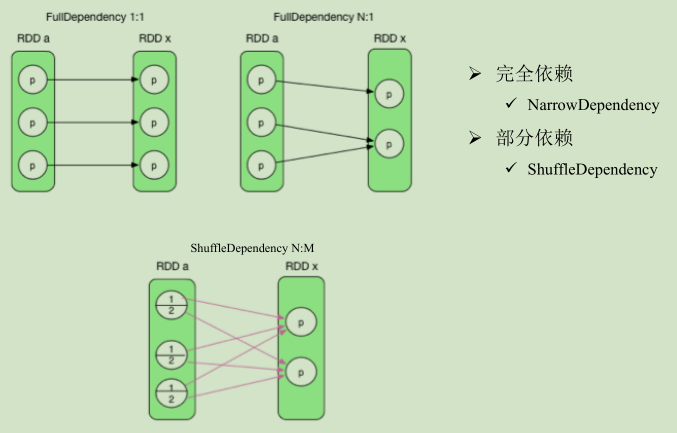
三、生成逻辑执行图:RDD之间关系
依赖关系分为两类。
完全依赖前面的partition只对应后面的一个partition,不会是多个。重点关注部分依赖(shuffle)
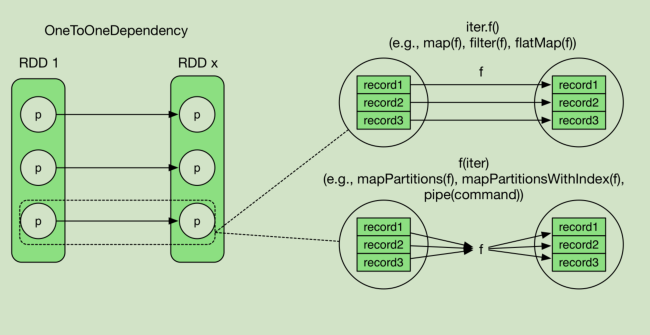
四、生成逻辑执行图:Shuffle
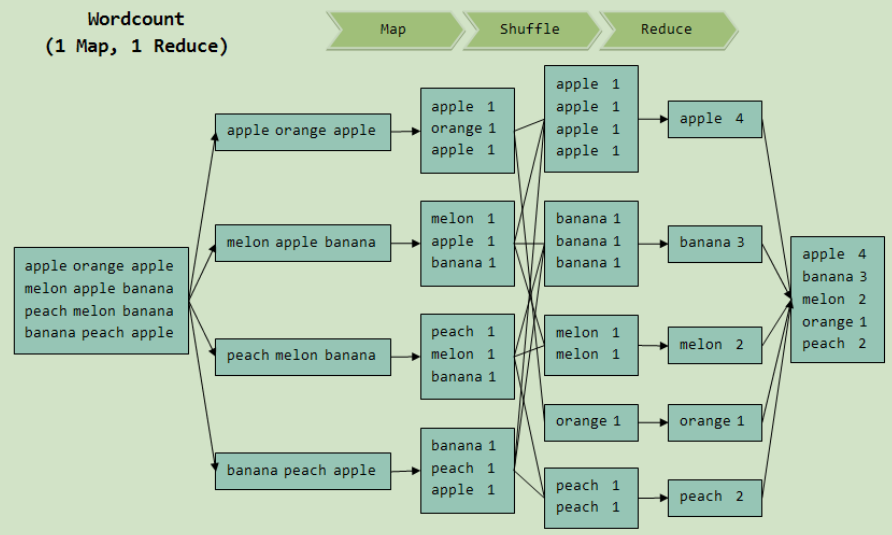
—每个reduce task要从每个map task端读取一部分数据,网络连接数是:M*R。
—shuffle是分布式计算框架的核心数据交换方式,其实现方式直接决定了计算框架的性能和扩展性。
—产生shuffle的算子:join、cogroup、和*ByKey(reduceByKey,groupByKey,sortByKey)
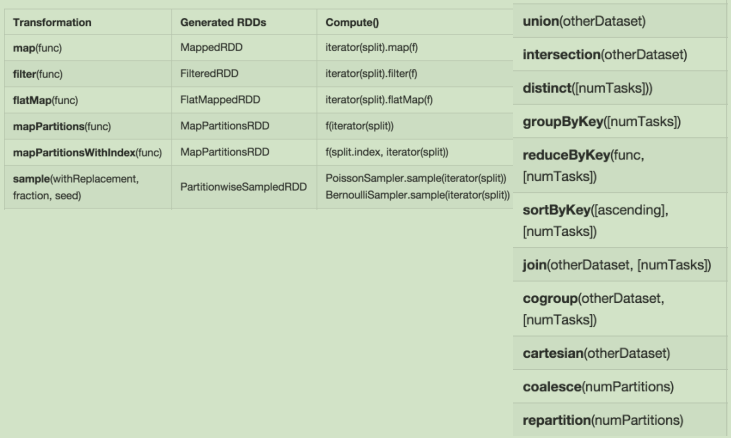
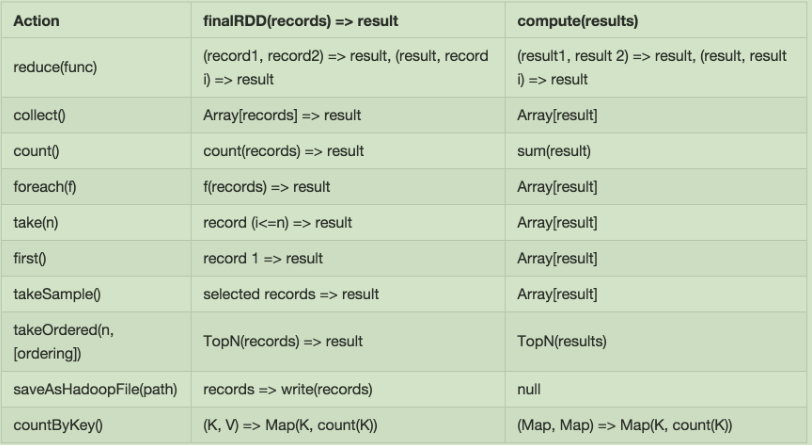
五、生成逻辑执行图:算子举例(1)
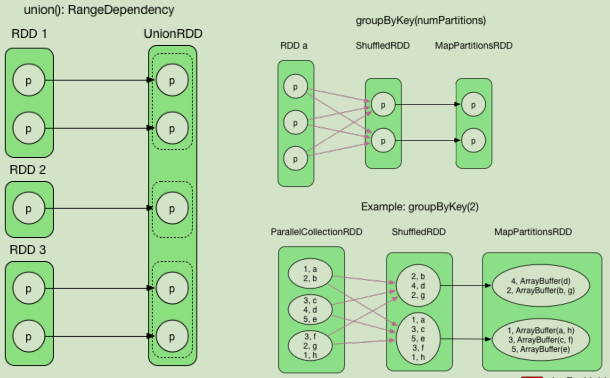
算子举例(2)
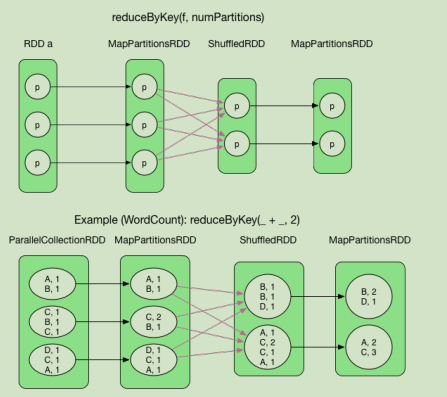
算子举例(3)
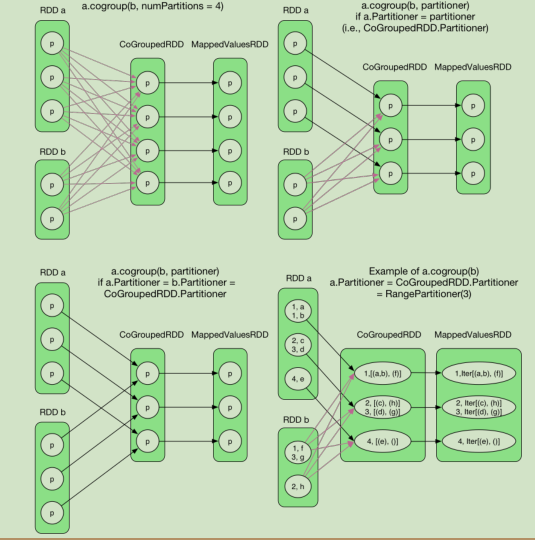
算子举例(4)
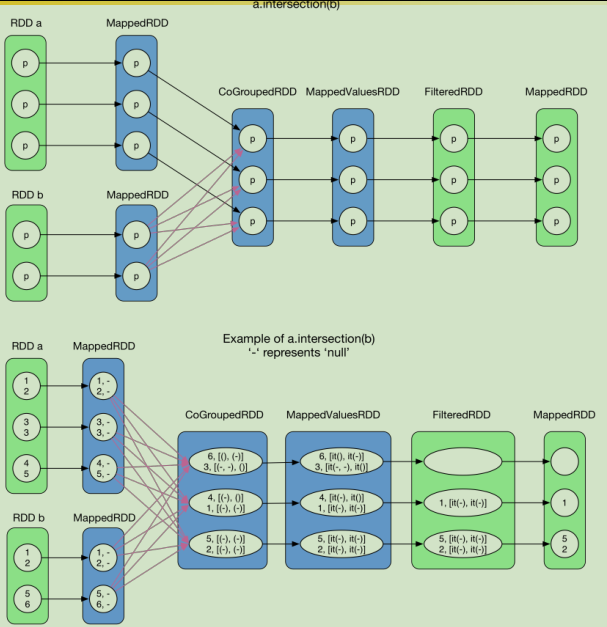
六、生成物理执行图:划分stage
物理计划分两步:划分stage;产生task。

前两个stage没有依赖关系可以并行的算。
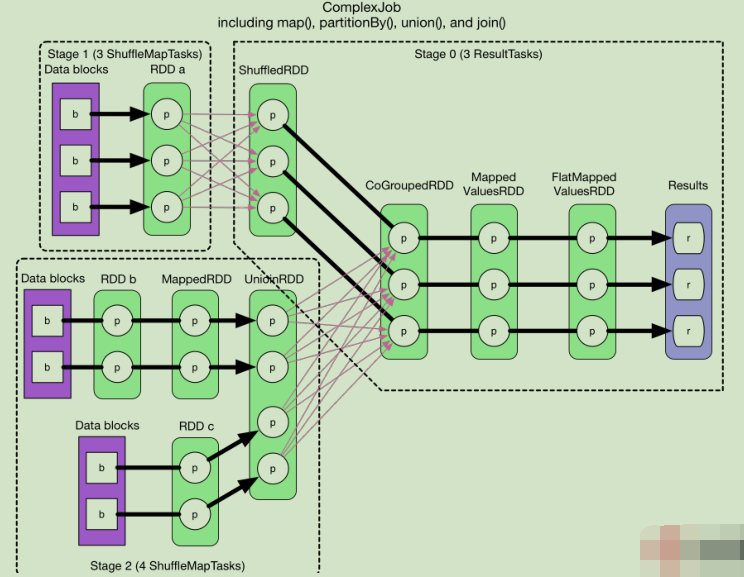
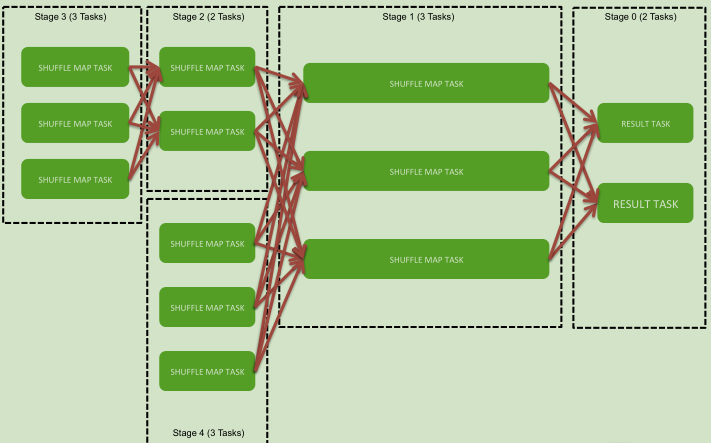
综合实例(看图)
逻辑执行图
没有依赖关系可以并行计算。下面分成五个stage。
生成13个task。
七、调度和提交任务
1.作业调度
——FIFO(默认)或Fair
——优化机制:数据本地性和推测执行
2.任务执行
——Task被序列化后,被driver发送到executor上执行,executor还原task进行本地计算。
——ShuffleMapTask将中间数据写到本地(必须写磁盘,如果不写磁盘容错、效率等都会非常差),ResultTask远程读取数据
——数据用的时候再算,而且数据是流到要计算的位置的
八、生成Job(遇到action开始执行)
——通过RDD,创建DAG(逻辑计划)
——为DAG生成物理查询计划
——调用并执行Task
二、生成逻辑执行图:产生RDD
生成RDD的DAG图。
三、生成逻辑执行图:RDD之间关系
依赖关系分为两类。
完全依赖前面的partition只对应后面的一个partition,不会是多个。重点关注部分依赖(shuffle)
四、生成逻辑执行图:Shuffle
—每个reduce task要从每个map task端读取一部分数据,网络连接数是:M*R。
—shuffle是分布式计算框架的核心数据交换方式,其实现方式直接决定了计算框架的性能和扩展性。
—产生shuffle的算子:join、cogroup、和*ByKey(reduceByKey,groupByKey,sortByKey)
五、生成逻辑执行图:算子举例(1)
算子举例(2)
算子举例(3)
算子举例(4)
六、生成物理执行图:划分stage
物理计划分两步:划分stage;产生task。
前两个stage没有依赖关系可以并行的算。
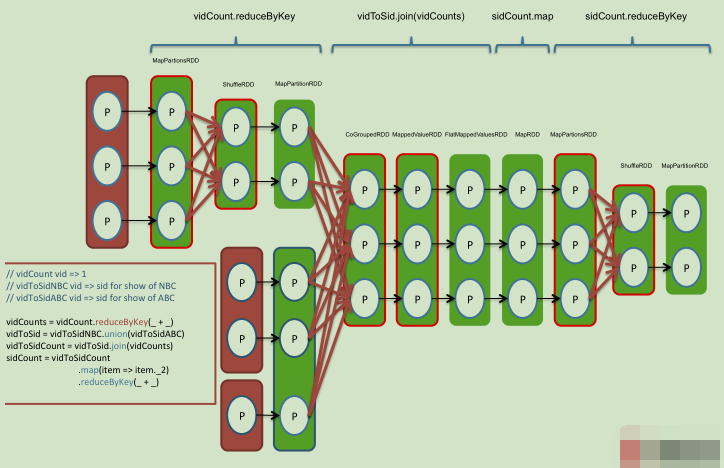
综合实例(看图)
//vidCount vid =>1 //vidToSidNBC vid => sid for show of NBC //vidToSidABC vid => sid for show of ABC vidCounts=vidCount.reduceByKey(_+_) vidToSid=vidToSidNBC.union(vidToSidABC) vidToSidCount=vidToSid.join(vidToSidABC) sidCount=vidToSidCount .map(item => item._2) .reduceByKey(_+_)
逻辑执行图
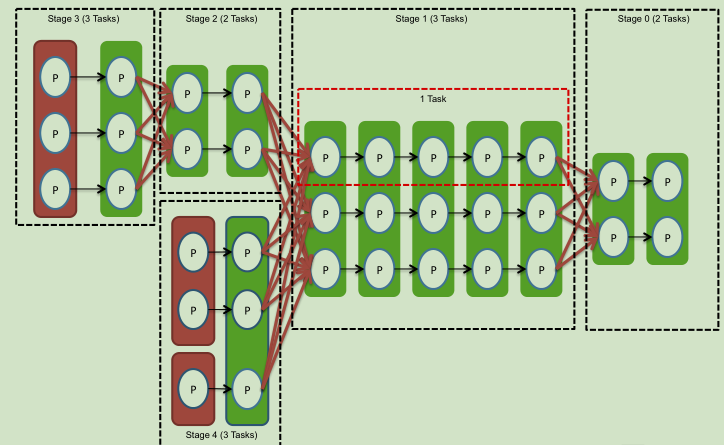
没有依赖关系可以并行计算。下面分成五个stage。
生成13个task。
七、调度和提交任务
1.作业调度
——FIFO(默认)或Fair
——优化机制:数据本地性和推测执行
2.任务执行
——Task被序列化后,被driver发送到executor上执行,executor还原task进行本地计算。
——ShuffleMapTask将中间数据写到本地(必须写磁盘,如果不写磁盘容错、效率等都会非常差),ResultTask远程读取数据
——数据用的时候再算,而且数据是流到要计算的位置的
八、生成Job(遇到action开始执行)

相关文章推荐
- spark大数据计算引擎原理深剖(优缺点)-spark简介
- Spark源码分析(1) 从WordCount示例看Spark延迟计算原理
- Spark源码分析(1) 从WordCount示例看Spark延迟计算原理
- spark部署、计算模型、内部执行原理、工作机制详解
- 深入理解Spark 2.1 Core (九):迭代计算和Shuffle的原理与源码分析
- Spark笔记(2)-Spark计算引擎剖析
- 正则表达式引擎的构建——基于编译原理DFA(龙书第三章)——3 计算4个函数
- 两款高性能并行计算引擎Storm和Spark比较
- 两款高性能并行计算引擎Storm和Spark比较
- HIVE和SPARKSQL计算引擎在TEXT导入PARQUET格式的HIVE存储引擎分片数量机制
- Spark (大规模数据处理而设计的快速通用的计算引擎, 与MapReduce类似 ) 基础概念
- 两款高性能并行计算引擎Storm和Spark比较
- 高性能并行计算引擎Storm和Spark比较
- 两款高性能并行计算引擎Storm和Spark比较
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
- 两款高性能并行计算引擎Storm和Spark比较
- 两款高性能并行计算引擎Storm和Spark比较
- 【转】Spark是基于内存的分布式计算引擎
- Spark源码分析(1) 从WordCount示例看Spark延迟计算原理
- 大数据SQL交互查询 presto/spark/mapreduce 计算引擎对比