spark基于用户的协同过滤算法与坑点,提交job
2016-10-21 15:48
176 查看
承接上文:
http://blog.csdn.net/wangqi880/article/details/52875524
对了,每台机子的防火墙要关闭哈,不然spark集群启动不起来
前一次,已经把spark的分布式集群布置好了,今天写一个简单的案例来运行。会写一些关于spark的推荐的东西,这里主要有4点,1基于用户协同过滤,2基于物品协同过滤,3基于模型的协同过滤,4基于关联规则的推荐(fp_growth),只写核心代码啊。
从这句话,我们可以看出UserBase推荐算法主要有3个工作要做:1用户相似度量,2最近邻居查找,3预测评分。
具体百度查
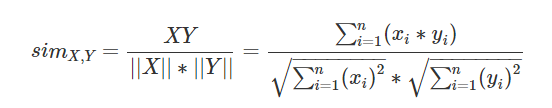
代码有注释哈,应该都可以看得懂,主要就是计算相似读,计算用户1给item1的评分,这里评分的计算为:用户均值+topn用户的加权平均值,权重为相似性。
2中间的转成行矩阵的方法恶心,toRowMatrix(),就是这个方法。因为,使用这个方法之后,矩阵的用户的标号顺序都变了,不知道怎么判断,标号和用户号都不一样了。举个例子大家就知道了,都可以试试:
运行的结果,和原始的样本一样的:
但是做了下面的转换成行矩阵的做法之后:
matrix的遍历方式为map,还不能输入用户id查找,恶心,用户2的打分用户3的打分反了,人工对比上下两个数据就知道了。
但是只能使用遍历方式,遍历matrix,我怎么知道这条记录是哪个用户的。
不过我人工计算了和程序计算的相似度是差不多的,相似度应该是OK的,这里也跪求大神指点疑问?
注意要保证数据文件在每个节点上都有哈
我的目录结构为(三台机器都要一样哈):
运行jar目录:/home/jar/

运行jar的数据目录为:/home/jar/data
jar与数据都好了之后,保证spark集群运行哈,然后输入命令运行我们的jar.
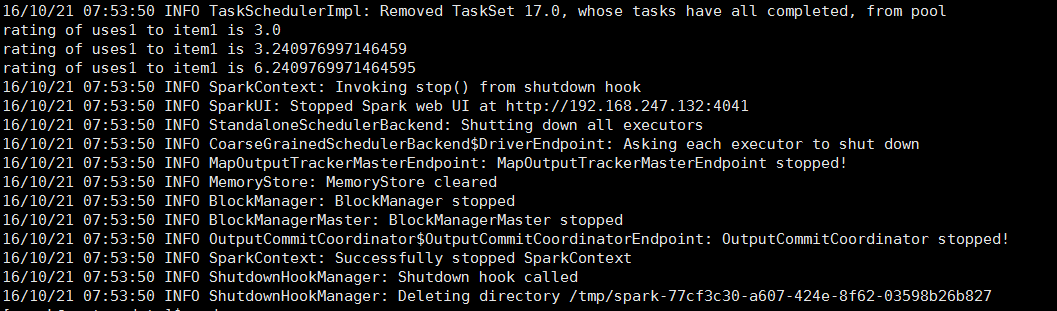
运行成功如图:
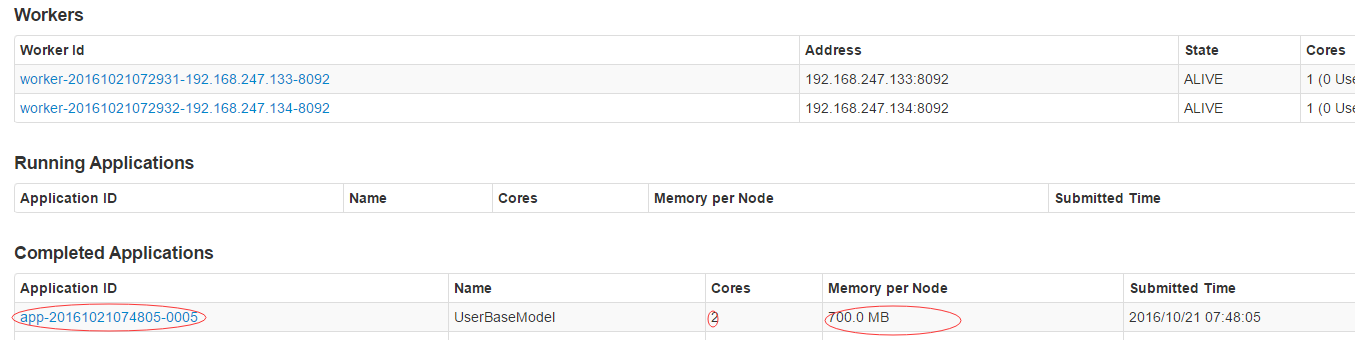
2保证你提交的job,设置的运行内存没有超过你自己在spark-env.sh中的内存,不然要报如下警告,资源不足,程序挂起,不能运行下去:

关于toRowMatrix()方法的疑问,求解大神解析。
有时间也会看源码研究下,
下一篇文章会写基于物品的协同过滤。
如果想做真实基于Spark的推荐,个人建议使用基于模型的与预计关联规则的推荐
http://blog.csdn.net/wangqi880/article/details/52875524
对了,每台机子的防火墙要关闭哈,不然spark集群启动不起来
前一次,已经把spark的分布式集群布置好了,今天写一个简单的案例来运行。会写一些关于spark的推荐的东西,这里主要有4点,1基于用户协同过滤,2基于物品协同过滤,3基于模型的协同过滤,4基于关联规则的推荐(fp_growth),只写核心代码啊。
基于spark用户协同过滤算法的实现
1用户协同过滤算法
1.1含义
它是统计计算搜索目标用户的相似用户,并根据相似用户对物品的打分来预测目标用户对指定物品的评分,一般选择topn选择相似度较高的相似用户做推荐结果。从这句话,我们可以看出UserBase推荐算法主要有3个工作要做:1用户相似度量,2最近邻居查找,3预测评分。
具体百度查
1.2相似性距离
这里直接使用cos距离了,cos距离是通过向量间的cos夹角来度量相似性,如果是在同一个方向增长,那么相似性是不会变得。公式如下:1.3样本数据如下:
1,1,5.0 1,2,1.0 1,3,5.0 1,4,1.0 2,1,5.0 2,2,1.0 2,3,5.0 2,4,1.0 3,1,1.0 3,2,5.0 3,3,1.0 3,4,5.0 4,1,1.0 4,2,5.0 4,3,1.0
2Spark代码如下:
package org.wq.scala.ml
import org.apache.spark.mllib.linalg.distributed._
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/10/20.
*/
object UserBaseTest {
def main(args:Array[String]): Unit = {
val conf = new SparkConf().setAppName("UserBaseModel").setMaster("local").set("spark.sql.warehouse.dir","E:/ideaWorkspace/ScalaSparkMl/spark-warehouse")
val sc = new SparkContext(conf)
//test.data是用户_物品_评分样本,且用户为Int,物品为int型
val data = sc.textFile("data/mllib/test.data")
val parseData= data.map(_.split(",") match {case Array(user,item,rate)=>MatrixEntry(user.toLong-1,item.toLong-1,rate.toDouble)})
/*parseData.collect().map(x=>{
println(x.i+"->"+x.j+"->"+x.value)
})*/
//coordinateMatrix是专门保存user_item_rating这种数据样本的
println("ratings:")
val ratings = new CoordinateMatrix(parseData)
ratings.entries.collect().map(x=>{
println(x.i+","+x.j+","+x.value)
})
//把CoordinateMatrix转换成RowMatrix计算两个用户之间的cos相似性,且行表示用户,列表示物品
//RowMatrix的方法,columnSimilarities是计算,列与列的相似度,现在是user_item_rating,需要转置(transpose)成item_user_rating,这样才是用户的相似
//toRowMatrix()之后,物品的顺序不是从小到大排序的,但是相似度是Ok的
val matrix= ratings.transpose().toRowMatrix()
println("toRowMatrix之后的结果:")
matrix.rows.collect().map(x=>{
x.toArray.map(x=>{print(x+",")})
println("")
})
val similarities = matrix.columnSimilarities()
//相似性是对的
println("相似性")
similarities.entries.collect().map(x=>{
println(x.i+"->"+x.j+"->"+x.value)
})
/*
similarities.entries.filter(_.i==0).sortBy(_.value,false).collect().map(x=>{
println(x.i+"->"+x.j+"->"+x.value)
})*/
//计算用户1对物品1的评分,预测结果为,用户1的评价分+其他相似用户对其的加权平均值,相似度为权重
// val ratingOfUser1 = ratings.toRowMatrix().rows.collect()(3).toArray ,这个就是数字不能代表user的下标
// toRowMatrix()好像有点问题
val ratingOfUser1 = ratings.entries.filter(_.i==0).map(x=>{(x.j,x.value)}).sortBy(_._1).collect().map(_._2).toList.toArray
val avgRatingOfUser1 = ratingOfUser1.sum/ratingOfUser1.size
//println(avgRatingOfUser1)
//计算其他用户对物品1的加权平均值,matrix是物品_用户_评分
//matrix的一行,就是物品的所有用户评分,drop(1)表示删除自己的评分哈
//matrix的(n)不能表示用户的下标啊
val ratingsToItem1=matrix.rows.collect()(0).toArray.drop(1)
//ratingsToItem1.map(x=>print(x))
//权重_.i==0选择第一个用户,sortBy(_.j)表示根据用户的下标作为Key,value降序(value越大,表示相似度越高),所以,越前相似度越高
val weights =similarities.entries.filter(_.i==0).sortBy(_.j).map(_.value).collect()
//val weights =similarities.entries.filter(_.i==0).sortBy(_.value,false).map(_.value).collect()
//(0 to 2)表示从0到2,默认步长1,这里表示,去top2相似的用户作为预测用户评分,真实情况,topn太少了哈
//sum(权重*用户评分)/sum(weights)
var weightedR = (0 to 2).map(t=>weights(t) * ratingsToItem1(t)).sum/weights.sum
//把平均值+top2相似用户的加权平均值
println("rating of uses1 to item1 is "+(avgRatingOfUser1))
println("rating of uses1 to item1 is "+(weightedR))
println("rating of uses1 to item1 is "+(avgRatingOfUser1+weightedR))
}
}代码有注释哈,应该都可以看得懂,主要就是计算相似读,计算用户1给item1的评分,这里评分的计算为:用户均值+topn用户的加权平均值,权重为相似性。
3坑点
1测试了300w多w记录,用户估计20w,物品大500,windows单机环境16g内存,配置2g的xxm,跑了1个小时都没有出来,速度太慢了,当然也跟机子配置有关,直接停了。2中间的转成行矩阵的方法恶心,toRowMatrix(),就是这个方法。因为,使用这个方法之后,矩阵的用户的标号顺序都变了,不知道怎么判断,标号和用户号都不一样了。举个例子大家就知道了,都可以试试:
//下面程序的结果,这个结果是ok的。
//用户_物品_打分
val ratings = new CoordinateMatrix(parseData)
ratings.entries.collect().map(x=>{
println("ratings=>"+x.i+"->"+x.j+"->"+x.value)
})运行的结果,和原始的样本一样的:
0,0,5.0 0,1,1.0 0,2,5.0 0,3,1.0 1,0,5.0 1,1,1.0 1,2,5.0 1,3,1.0 2,0,1.0 2,1,5.0 2,2,1.0 2,3,5.0 3,0,1.0 3,1,5.0 3,2,1.0
但是做了下面的转换成行矩阵的做法之后:
下面是做了transpose().toRowRamtrix的结果
ratings.toRowMatrix().rows.collect().map(x=>{
println()
x.toArray.map(t=>{
println(t+",")
})
})
5.0,5.0,1.0,1.0,
1.0,1.0,5.0,5.0,
1.0,1.0,5.0,0.0,
5.0,5.0,1.0,1.0,matrix的遍历方式为map,还不能输入用户id查找,恶心,用户2的打分用户3的打分反了,人工对比上下两个数据就知道了。
但是只能使用遍历方式,遍历matrix,我怎么知道这条记录是哪个用户的。
不过我人工计算了和程序计算的相似度是差不多的,相似度应该是OK的,这里也跪求大神指点疑问?
//程序计算相似度 2->3->0.7205766921228921 0->1->1.0000000000000002 1->2->0.3846153846153847 0->3->0.4003203845127179 1->3->0.4003203845127179 0->2->0.3846153846153847
4把jar提交到spark集群运行
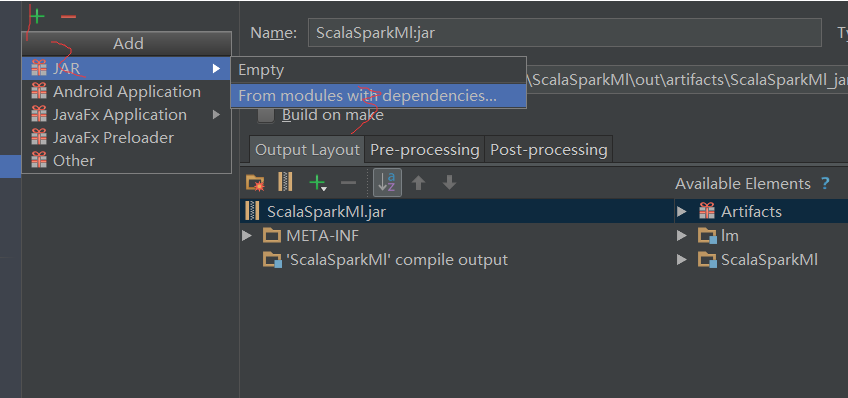
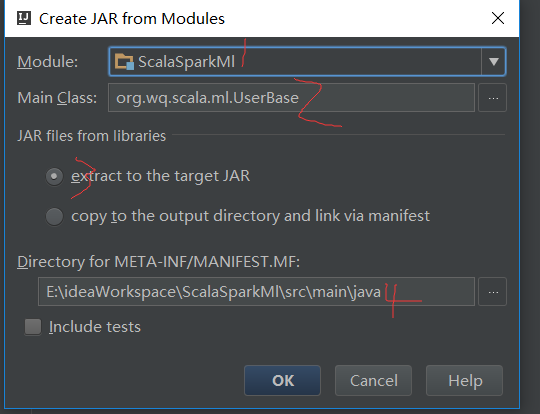
4.1打包方式
我使用的是idea,使用ctrl+alt+shift+s,4.2运行jar与注意事项
使用rz上传到centos中,shh工具或者其他工具都是可以,自己喜欢就好,注意要保证数据文件在每个节点上都有哈
我的目录结构为(三台机器都要一样哈):
运行jar目录:/home/jar/
运行jar的数据目录为:/home/jar/data
jar与数据都好了之后,保证spark集群运行哈,然后输入命令运行我们的jar.
spark-submit --class org.wq.scala.ml.UserBase --master spark://master:7077 --executor-memory 1g --num-executors 1 /home/jar/UserBaseSpark.jar /home/jar/data/test.data
运行成功如图:
4.3注意事项
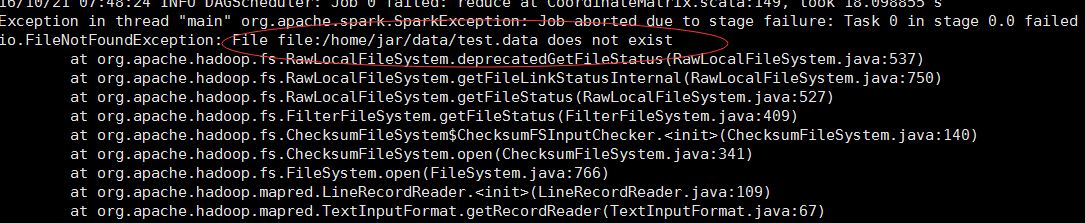
1保证你的数据文件在节点中都有,不然汇报错误:2保证你提交的job,设置的运行内存没有超过你自己在spark-env.sh中的内存,不然要报如下警告,资源不足,程序挂起,不能运行下去:
关于toRowMatrix()方法的疑问,求解大神解析。
有时间也会看源码研究下,
下一篇文章会写基于物品的协同过滤。
如果想做真实基于Spark的推荐,个人建议使用基于模型的与预计关联规则的推荐

相关文章推荐
- 案例:Spark基于用户的协同过滤算法
- 基于用户的协同过滤算法简介
- Mahout基于项目的协同过滤算法源码分析(2)--RowSimilarityJob
- 基于用户最近邻模型的协同过滤算法的Python代码实现
- [推荐算法]UserCF,基于用户的协同过滤算法
- 基于用户的协同过滤算法(UserCF)
- 【repost】毕设-基于用户的协同过滤算法在HBase中的存储
- [推荐算法]基于用户的协同过滤算法
- 基于用户和基于物品的协同过滤算法的比较
- 推荐算法之基于用户的协同过滤算法
- 推荐系统实践--基于用户的协同过滤算法
- Mahout基于项目的协同过滤算法源码分析(3)--RowSimilarityJob
- [推荐算法]基于用户的协同过滤算法
- 推荐系统--基于用户的协同过滤算法
- 推荐系统--基于用户的协同过滤算法
- Mahout基于项目的协同过滤算法源码分析(1)--PreparePreferenceMatrixJob
- [推荐算法]基于用户的协同过滤算法
- 基于用户的协同过滤算法的Python实现
- 基于用户的协同过滤算法
- 数据挖掘之推荐系统实践--基于用户的协同过滤算法