决策树分类ID3算法的Python实现
2016-10-20 21:05
731 查看
生成决策树是从数据中生成分类器的一个特别有效的方法。决策树从一组无次序、无规则的事例中推理出分类规则。
ID3算法的核心是信息熵和信息增益,计算信息熵和信息增益有以下关键公式:
信息熵:
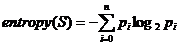
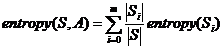
信息增益:
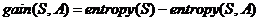
信息增益大的属性将被作为下一分类依据。
简单地说:ID3算法就是按照一定规则,选择出一堆样本属性中最为合适的一个属性,作为分类的依据,最终形成一个树状的分类规则。而这里的一定规则就是计算各个属性的信息增益,其中信息增益最大的属性就是被选出的属性。
很多天的天气数据如下图(其实没很多,就14项,够敲的了):
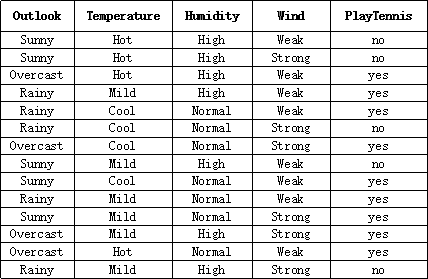
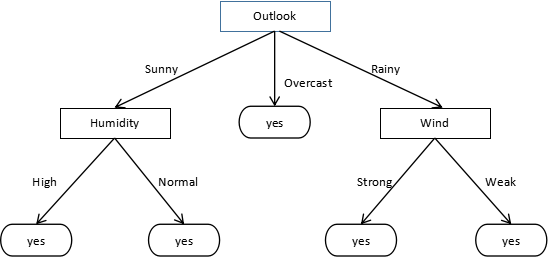
最后生成的决策树是这样的:
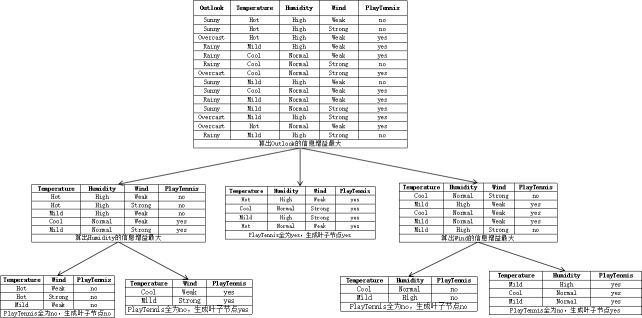
其中,数据经历了这样的变化:
听说Python语言更适合于数据挖掘,于是我在这次实验之前学习了Python语言,并在这次试验中运用了起来,用Python语言实现了ID3算法。由于本人初学Python,如有可以改进优化的地方敬请大家指教。
ID3算法
ID3算法采用自顶向下的递归方法构造决策树,从单表训练样本的单个节点开始,使用信息熵来选择合适的分类属性,将样本划分成若干子集,直到样本都在同一个分类中。ID3算法的核心是信息熵和信息增益,计算信息熵和信息增益有以下关键公式:
信息熵:
信息增益:
信息增益大的属性将被作为下一分类依据。
简单地说:ID3算法就是按照一定规则,选择出一堆样本属性中最为合适的一个属性,作为分类的依据,最终形成一个树状的分类规则。而这里的一定规则就是计算各个属性的信息增益,其中信息增益最大的属性就是被选出的属性。
举例
据说课本上的例子是相当经典的,就是根据很多天的天气情况决定是否打网球。很多天的天气数据如下图(其实没很多,就14项,够敲的了):
最后生成的决策树是这样的:
其中,数据经历了这样的变化:
听说Python语言更适合于数据挖掘,于是我在这次实验之前学习了Python语言,并在这次试验中运用了起来,用Python语言实现了ID3算法。由于本人初学Python,如有可以改进优化的地方敬请大家指教。
代码
#
# 用户输入
#
titles = ['Outlook', 'Temperature', 'Humidity', 'Wind', 'PlayTennis']
dataset = [
['Sunny', 'Hot', 'High', 'Weak', 'no'],
['Sunny', 'Hot', 'High', 'Strong', 'no'],
['Overcast', 'Hot', 'High', 'Weak', 'yes'],
['Rainy', 'Mild', 'High', 'Weak', 'yes'],
['Rainy', 'Cool', 'Normal', 'Weak', 'yes'],
['Rainy', 'Cool', 'Normal', 'Strong', 'no'],
['Overcast', 'Cool', 'Normal', 'Strong', 'yes'],
['Sunny', 'Mild', 'High', 'Weak', 'no'],
['Sunny', 'Cool', 'Normal', 'Weak', 'yes'],
['Rainy', 'Mild', 'Normal', 'Weak', 'yes'],
['Sunny', 'Mild', 'Normal', 'Strong', 'yes'],
['Overcast', 'Mild', 'High', 'Strong', 'yes'],
['Overcast', 'Hot', 'Normal', 'Weak', 'yes'],
['Rainy', 'Mild', 'High', 'Strong', 'no']
]
#
# ID3算法
#
import math
def log2(n):
return math.log(n)/math.log(2)
#
# 根据下标划分子集
#
def classify(data, index):
a = {}
for ls in data:
try:
a[ls[index]].append(ls)
except:
a[ls[index]] = [ls]
return a
#
# 计算信息熵
#
def entropy(data, index):
a = {}
for item in data:
try:
a[item[index]] += 1
except:
a[item[index]] = 1
entropy = 0.0
for key in a.keys():
p = 1.0 * a[key] / len(data)
entropy += p*log2(p)
return -entropy
#
# 计算子集的熵
#
def entropy2(data, attrIndex, tarIndex):
classes = classify(data, attrIndex)
e = 0.0
for key in classes.keys():
ent = entropy(classes[key], tarIndex)
e += ent * len(classes[key]) / len(data)
return e
#
# 计算信息增益
#
def gain(entropy, entropy2):
return entropy - entropy2
#
# 决策树节点
#
class TreeNode(object):
def __init__(self, data, index, attrIndexes):
self.decision = titles[index]
classes = classify(data, index) #根据属性分类
self.children = {}
children = classes.keys()
for child in children: #生成子树
data = classes[child]
self.children[child] = generateTree(data, list(attrIndexes))
def __str__(self):
return self.decision
#
# 生成节点
#
def generateTree(dataset, attrIndexes):
classes = classify(dataset, tarIndex)
if len(classes) == 1: #假如同一类
tree = dataset[0][tarIndex]
else:
e = entropy(dataset, tarIndex) #计算信息熵
gains = {}
maxIndex = attrIndexes[0]
for i in attrIndexes: #计算信息增益并找出信息增益最大的属性
gains[titles[i]] = gain(e, entropy2(dataset, i, tarIndex))
if gains[titles[i]] > gains[titles[maxIndex]]:
maxIndex = i
attrIndexSet = set(attrIndexes[:])
attrIndexSet.remove(maxIndex)
tree = TreeNode(dataset, maxIndex, attrIndexSet)
return tree
#
# 显示决策树
#
def displayTree(tree):
if isinstance(tree, TreeNode):
print (tree)
for key in tree.children:
print (key + ':' + tree.children[key].__str__())
displayTree(tree.children[key])
tarIndex = len(dataset[0]) - 1 #样本分类下标
attrIndexes = range(0,tarIndex) #样本属性下标
tree = generateTree(dataset, attrIndexes)
displayTree(tree)

相关文章推荐
- Python实现决策树_ID3算法
- Python 实现决策树分类算法
- 决策树ID3算法python实现代码及详细注释
- python实现决策树分类(2)
- python 使用Id3算法实现决策树
- CART分类决策树、回归树和模型树算法详解及Python实现
- python实现决策树分类(一)
- 决策树ID3算法的python实现
- 决策树(ID3算法)Python实现
- python实现决策树分类
- python实现决策树ID3算法
- 决策树---ID3算法(介绍及Python实现)
- 决策树的ID3算法实现(Python版)
- 决策树ID3算法及其Python实现
- 机器学习经典算法详解及Python实现--CART分类决策树、回归树和模型树
- Python实现ID3算法决策树
- 分类算法-----决策树(ID3)算法原理和Python实现
- python中利用决策树实现泰坦尼克死亡和生还人生的分类
- python实现决策树分类算法
- 分类决策树简介及ID3算法实现