elk集群安装配置详解
2016-10-14 11:33
429 查看
# 一:简介
```
Elasticsearch作为日志的存储和索引平台;
Kibana 用来从 Elasticsearch获取数据,进行数据可视化,定制数据报表;
Logstash 依靠强大繁多的插件作为日志加工平台;
Filebeat 用来放到各个主机中收集指定位置的日志,将收集到日志发送到 Logstash;
Log4j 直接与 Logstash 连接,将日志直接
Logstash(当然此处也可以用 Filebeat 收集 tomcat 的日志)。
```
#### port
```
Elasticsearch
9200:对外提供服务的 HTTP 端口
9300:作为交互的 TCP 端口
Logstash
5000: Logstash TCP input
5044:用于接收来着 Filebeat 收集的日志数据
4569:用于接收来着 Log4j 的日志数据
8080:用于接收来自插件 Logstash-input-http 的日志数据
Kibana
5601 端口用于 Kibana的界面
```
#### 安装环境介绍:
```
- 系统版本
more /etc/redhat-release
CentOS Linux release 7.2.1511 (Core)
- 系统内核
uname -a
Linux yunwei-ts-100-71 3.10.0-327.13.1.el7.x86_64 #1 SMP Thu Mar 31 16:04:38 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
- java 版本
java -version
openjdk version "1.8.0_101"
OpenJDK Runtime Environment (build 1.8.0_101-b13)
OpenJDK 64-Bit Server VM (build 25.101-b13, mixed mode)
- 如果版本过低,或者没有安装执行命令如下:
yum install java-1.8.0-*
注意: Logstash需要Java 8或更高版本.可以使用 http://www.oracle.com/technetwork/java/javase/downloads/index.html [oracle官方版本] 或者使用开源版本OpenJDK: http://openjdk.java.net/. ```
#### 二:集群安装配置
```
- 测试集群规划
主机名 IP地址
yunwei-ts-100-70 172.16.1.70
yunwei-ts-100-71 172.16.1.71
yunwei-ts-100-111 172.16.1.111
- 软件版本:
elasticsearch 2.4.1
logstash.noarch 1:2.3.4-1
filebeat-1.2.3
kibana.x86_64 0:4.5.3-1
```
### 安装部署elasticsearch集群
##### 简介
ElasticSearch原生支持Cluster模式,节点之间通过单播或多播进行通信;ElasticSearch Cluster能自动检测节点的增加、失效和恢复,并重新组织索引。
##### ELK的工作原理:
使用多播进行机器发现同一个集群内的节点,并汇总各个节点的返回组成一个集群,主节点要读取各个节点的
状态,在关键的时候进行数据的恢复,主节点会jian'shi监视各个节点的状态,并决定每个分片的位置,通过ping的request检测各失效的节点。
##### elasticsearch的基本结构认识
```
以mysql数据库为实例对应理解:
mysql 数据库databases 表tables 行rows 列columns
es 索引indices 类型types 文档documents 字段fields
```
##### elasticsearch中所说的索引容易混淆,3种含义:
```
1. 索引(名词) 如上面类比,一个索引(index)就好比是mysql中的数据库,它是存储数据的地方。
2. 索引(动词)表示把一个文档存储到索引(名词)里。
3. 倒排索引 好比mysql为特定列增加一个索引。
- 和mysql类似,每个库都得有表,还有表的结构。es的每一个索引都有个类型,而每个type(类型)得有个mapping (映射)。mapping就像是mysql中的表结构, 他将每个字段匹配为一种确定的数据类型(string,date等)。
- 你可以向已有映射中增加字段,但你不能修改它。如果一个字段在映射中已经存在,这可能意味着那个字段的数据已经被索引。
- 如果你改变了字段映射,那已经被索引的数据将错误并且不能被正确的搜索到.为了提高搜索的效率,es使用倒排索引来做全文搜索。通过analyzer(分词器)先把需要分析的文本,表征化为适合的term(词),然后标准化这些term,使他们容易被搜索到。(比如说模糊大小写,空格等等)
```
##### 集群规划
```
主机名 IP 集群服务
yunwei-ts-100-70 172.16.100.70 (elasticsearch)
yunwei-ts-100-70 172.16.100.71 (elasticsearch)
yunwei-ts-100-70 172.16.100.111 (elasticsearch)
软件版本: 2.4.1-1
```
#### 安装 Elasticsearch
###### 添加yum 签名key,
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
###### 添加 elasticsearch.repo 到 /etc/yum.repos.d/ 目录
```
cat >/etc/yum.repos.d/elasticsearch.repo <<-EOF
[elasticsearch-2.x]
name=Elasticsearch repository for 2.x packages
baseurl=https://packages.elastic.co/elasticsearch/2.x/centos
gpgcheck=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
EOF
```
###### 2.1.3:安装软件包
```
yum install elasticsearch -y
```
###### 建立slasticsearch 存储数据的目录
```
mkdir -p /data/elasticsearch
chown elasticsearch.elasticsearch /data/elasticsearch
```
###### 2.1.4:调整配置文件
```
vi /etc/elasticsearch/elasticsearch.yml
cluster.name: ptsearch # 组名(同一个组,组名必须一致)
node.name: yunwei-ts-100-70 # 节点名称,建议和主机名一致
path.data: /data/elasticsearch # 数据存放的路径
path.logs: /var/log/elasticsearch/ # 日志存放的路径
bootstrap.mlockall: true # 锁住内存,不被使用到交换分区去
network.host: 0.0.0.0 # 网络设置
http.port: 9200 # 端口
discovery.zen.ping.unicast.hosts: ["172.16.100.71","172.16.100.111"] #手动发现节点,写本机之外的集群节点IP地址
discovery.zen.ping.multicast.enabled: false #关闭多播模式
```
==以上配置3台elasticsearch节点都要配,注意nodename写每台主机的名称,discovery.zen.ping.unicast.hosts:xie写本机之外的集群节点IP地址。==
###### 2.1.5:添加开机启动
systemctl enable elasticsearch.service
###### 启动服务
systemctl start elasticsearch
###### 查看服务状态
```
systemctl status elasticsearch
..............
Process: 6470 ExecStartPre=/usr/share/elasticsearch/bin/elasticsearch-systemd-pre-exec (code=exited, status=0/SUCCESS)
Main PID: 6473 (java)
Memory: 280.2M
CGroup: /system.slice/elasticsearch.service
└─6473 /bin/java -Xms256m -Xmx1g -Djava.awt.headless=true
```
==注意:上面可以看出elasticsearch设置默认的内存最小256m,最大1g==
##### 2.1.6:检查,验证服务器端口
```
netstat -antlp |egrep "9200|9300"
tcp 0 0 172.16.100.70:9200 172.16.3.151:36013 SYN_RECV -
tcp 0 0 172.16.100.70:9200 172.16.3.151:36012 SYN_RECV -
tcp 0 0 127.0.0.1:35793 127.0.0.1:9200 TIME_WAIT -
tcp 0 0 127.0.0.1:35791 127.0.0.1:9200 TIME_WAIT -
tcp 0 0 127.0.0.1:35794 127.0.0.1:9200 TIME_WAIT -
tcp 0 0 127.0.0.1:35792 127.0.0.1:9200 TIME_WAIT -
tcp6 0 0 :::9200 :::* LISTEN 6473/java
tcp6 0 0 :::9300 :::* LISTEN 6473/java
tcp6 0 0 172.16.100.70:53651 172.16.6.24:9200 ESTABLISHED 19098/java
tcp6 0 1 172.16.100.70:35771 10.42.0.1:9200 SYN_SENT 19098/java
```
##### 启动两个端口
```
9200:集群之间事务通信
9300:集群选举等
```
##### elasticsearch 目录环境介绍:
```
Environment=ES_HOME=/usr/share/elasticsearch
Environment=CONF_DIR=/etc/elasticsearch
Environment=DATA_DIR=/var/lib/elasticsearch
Environment=LOG_DIR=/var/log/elasticsearch
Environment=PID_DIR=/var/run/elasticsearch
EnvironmentFile=-/etc/sysconfig/elasticsearch
```
## 验证服务接口响应
##### 通过浏览器访问:
http://172.16.100.70:9200/ 返回数据如下:
```
{
"name" : "yunwei-ts-100-70", 《《===节点名称
"cluster_name" : "ptsearch", 《《===集群名称
"version" : {
"number" : "2.3.4",
"build_hash" : "e455fd0c13dceca8dbbdbb1665d068ae55dabe3f",
"build_timestamp" : "2016-06-30T11:24:31Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
}
```
##### 通过命令的方式查看数据(可以在node1本机上查看,也可以在其他机器上访问node的9200查看,如下)
```
curl -i -XGET 'http://172.16.100.70:9200/_count?pretty' -d '{"query":{"match_all":{}}}'
HTTP/1.1 200 OK
Content-Type: application/json; charset=UTF-8
Content-Length: 95
{
"count" : 2,
"_shards" : {
"total" : 1, 《《===集群加入节点后数据会变化
"successful" : 1,
"failed" : 0
}
}
```
##### 查看健康信息:
curl -XGET 'http://172.16.100.70:9200/_cluster/health?pretty'
```
{
"cluster_name" : "ptsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 1,
"active_shards" : 1,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 1,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 50.0
}
```
##### 查看节点数:
curl -XGET '172.16.100.70:9200/_cat/nodes?v'
```
host ip heap.percent ram.percent load node.role master name
172.16.100.111 172.16.100.111 7 98 0.65 d m yunwei-ts-100-111
172.16.100.70 172.16.100.70 5 69 0.00 d * yunwei-ts-100-70 <<主节点
172.16.100.71 172.16.100.71 7 97 0.00 d m yunwei-ts-100-71
```
##### 查看节点分片信息:
curl -XGET '172.16.100.70:9200/_cat/indices?v'
```
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana 1 1 2 0 38.4kb 19.2kb
green open .marvel-es-1-2016.10.11 1 1 1369 0 840.1kb 420kb
green open .marvel-es-1-2016.10.10 1 1 4468 0 1.2mb 634.9kb
```
#### elasticsearch日志定期清理日志、索引
索引旧数据需要清理,清理所以可以使用Elasticsearch的API。
例如:
删除某个索引2016年11月份的所有索引,可以使用下面的命令:
```
curl -XDELETE 'http://localhost:9200/customer-2016.11.*'
```
## ElasticSearch参数优化
(提高检索效率)
```
一、Linux操作系统优化
1) 调整系统资源最大句柄数
/etc/security/limits.conf
在文件中增加
* soft nofile 65536
* hard nofile 65536
2) 设置bootstrap.mlockall: 为true来锁住内存。因为当jvm开始swapping时es的效率会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。
同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过`ulimit -l unlimited`命令。
3) 关闭文件更新时间
cat /etc/fstab
/dev/sda7 /data/elasticSearch ext4 defaults,noatime 0 0
4) 提高ES占用内存(elasticsearch.in.sh)
ES_MIN_MEM=30g (一般为物理内存一半,但不要超过31G)
ES_MAX_MEM=30g
官方建议: https://www.elastic.co/guide/en/elasticsearch/guide/current/heap-sizing.html#compressed_oops ```
## 二、Elasticsearch 字段缓存优化
```
1) Fielddata(字段数据)
Elasticsearh默认会将fielddata全部加载到内存。但是,内存是有限的,需要对fielddata内存做下限制:Indices.fieldata.cache.size 节点用于fielddata的最大内存,如果fielddata达到该阀值,就会把旧数据交换出去。默认设置是不限制,建议设置10%。
2) doc-values
其实就是在elasticsearch 将数据写入索引的时候,提前生成好fileddata内容,并记录到磁盘上。因为fileddata数据是顺序读写的,所以即使在磁盘上,通过文件系统层的缓存,也可以获得相当不错的性能。doc_values只能给不分词(对于字符串字段就是设置了 "index":"not_analyzed",数值和时间字段默认就没有分词) 的字段配置生效。
如相应字段设置应该是:
"@timestamp":{
"type":"date",
"index":"not_analyzed",
"doc_values":true,
}
优化参考文档: https://my.oschina.net/davehe/blog/549189 ```
## 安装elasticsearch插件
安装部署访问下面博客页面: http://michaelkang.blog.51cto.com/1553154/1861838
### elasticsearch 安装配置故障排查:
###### elasticsearch服务启动报错:
```
[2016-10-11 16:18:43,974][WARN ][bootstrap ] Unable to lock JVM Memory: error=12,reason=Cannot allocate memory
[2016-10-11 16:18:43,975][WARN ][bootstrap ] This can result in part of the JVM being swapped out.
[2016-10-11 16:18:43,975][WARN ][bootstrap ] Increase RLIMIT_MEMLOCK, soft limit: 65536, hard limit: 65536
[2016-10-11 16:18:43,975][WARN ][bootstrap ] These can be adjusted by modifying /etc/security/limits.conf, for example:
# allow user 'elasticsearch' mlockall
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimited
[2016-10-11 16:18:43,975][WARN ][bootstrap ] If you are logged in interactively, you will have to re-login for the new limits to take effect.
[2016-10-11 16:18:44,165][INFO ][node ] [yunwei-ts-100-71] version[2.4.1], pid[31324], build[c67dc32/2016-09-27T18:57:55Z]
[2016-10-11 16:18:44,165][INFO ][node ] [yunwei-ts-100-71] initializing ...
[2016-10-11 16:18:44,719][ERROR][bootstrap ] Exception
部分内容省略
```
###### 解决办法:
```
1:修改启动文件
systemd:
/usr/lib/systemd/system/elasticsearch.service set: LimitMEMLOCK=infinity
SysV:
/etc/sysconfig/elasticsearch set: MAX_LOCKED_MEMORY=unlimited
Upstart:
/etc/default/elasticsearch set: MAX_LOCKED_MEMORY=unlimited
Then restart Elasticsearch.
2:在limit 文件添加配置如下:
/etc/security/limits.conf
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimited
```
---
## 2.2:安装配置Kibana
##### 2.2.1:添加yum 签名key,添加 kibana.repo 到 /etc/yum.repos.d/ 目录
```
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
cat >/etc/yum.repos.d/kibana.repo <<-EOF
[kibana-4.5]
name=Kibana repository for 4.5.x packages
baseurl=http://packages.elastic.co/kibana/4.5/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
EOF
```
##### 安装软件包,
软件版本: 4.5.4-1
```
yum install kibana -y
```
##### 调整配置文件
```
sudo vi /opt/kibana/config/kibana.yml
......
4 # The host to bind the server to.
5 # server.host: "0.0.0.0"
6 server.host: "0.0.0.0" #
7
8 # If you are running kibana behind a proxy, and want to mount it at a path,
9 # specify that path here. The basePath can't end in a slash.
10 # server.basePath: ""
11
12 # The maximum payload size in bytes on incoming server requests.
13 # server.maxPayloadBytes: 1048576
14
15 # The Elasticsearch instance to use for all your queries.
16 # elasticsearch.url: "http://localhost:9200"
17 elasticsearch.url: "http://localhost:9200" #elasticsearch 地址 《=====
18..
```
==elasticsearch cluster地址,可以写多个节点,kibana 只会取最后一个连接,不支持多节点负载均衡和自动冗余==
```
elasticsearch.url: http://172.16.100.111:9200 elasticsearch.url: http://172.16.100.70:9200 elasticsearch.url: http://172.16.100.71:9200
```
##### 2.2.5:添加开机启动,启动服务;
```
chkconfig --add kibana
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable kibana.service
sudo systemctl start kibana
```
##### 检查,验证服务器端口
```
lsof -n -i:5601
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
node 29895 kibana 11u IPv4 9963707 0t0 TCP *:esmagent (LISTEN)
```
##### 验证访问:
http:172.16.100.70:5601
### 2.4: 安装部署 Kibana Dashboards
##### 下载软件包
```
cd ~
curl -L -O https://download.elastic.co/beats/dashboards/beats-dashboards-1.1.0.zip ```
##### 安装解压软件,解压软件包
```
sudo yum -y install unzip
unzip beats-dashboards-*.zip
```
##### 2.4.3:导入基础显示面板, 将数据导入 Elasticsearch 命令如下:
```
cd beats-dashboards-*
./load.sh
```
指向上面的命令将导入如下查询模板信息
```
[packetbeat-]YYYY.MM.DD
[topbeat-]YYYY.MM.DD
[filebeat-]YYYY.MM.DD
[winlogbeat-]YYYY.MM.DD
```
##### 访问页面,即可查看索引 http://172.16.100.70:5601/
---
## 2.3:安装配置 Logstash
##### 插件简介
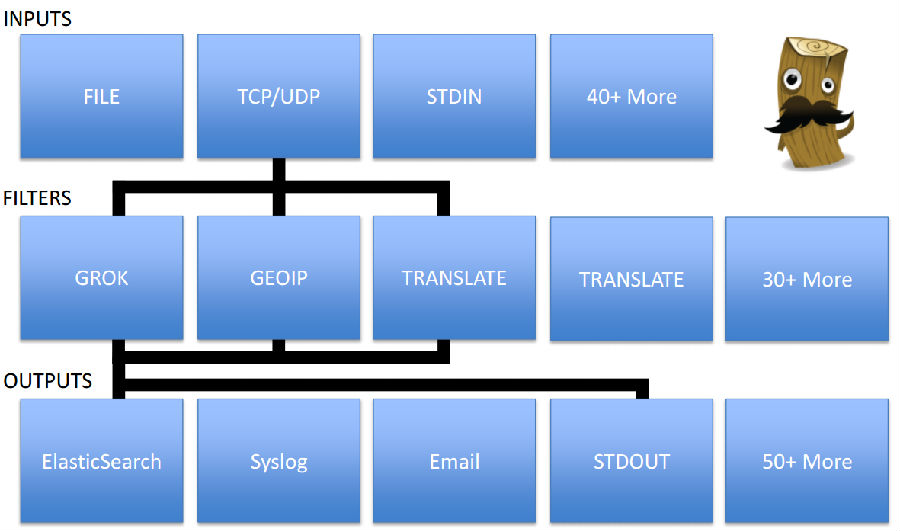
##### 官方参考信息: https://www.elastic.co/guide/en/logstash/current/index.html
##### 添加yum 签名key:
```
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch ```
##### 添加 logstash.repo 到 /etc/yum.repos.d/ 目录
```
cat >/etc/yum.repos.d/logstash.repo <<-EOF
[logstash-2.4]
name=Logstash repository for 2.4.x packages
baseurl=https://packages.elastic.co/logstash/2.4/centos
gpgcheck=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
EOF
```
2.3.3:安装软件包
```
yum install logstash -y
```
### 配置日志输入、输出
[tuopu](!http://image.3001.net/images/20150914/14422334919180.png)
##### 2.3.4:调整配置文件
vi /etc/logstash/conf.d/02-beats-input.conf
```
input {
beats {
port => 5044
# ssl => true
# ssl_certificate => "/etc/pki/tls/certs/logstash-forwarder.crt"
# ssl_key => "/etc/pki/tls/private/logstash-forwarder.key"
}
}
```
logstack 输入默认使用5044 端口,如果需要使用ssl 加密传输,可以配置自己证书
##### 创建一个配置文件,10-syslog-filter.conf ,添加 syslog messages,过滤配置。
sudo vi /etc/logstash/conf.d/10-syslog-filter.conf
nsert the following syslog filter configuration:
```
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
syslog_pri { }
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
```
配置完成保存退出,上面的配置是添加一个 syslog 的过滤标签,将输入的日志进行格式化并生成查询表;
##### 再创建一个配置文件 30-elasticsearch-output.conf:
sudo vi /etc/logstash/conf.d/30-elasticsearch-output.conf
添加日志输出配置如下:
```
output {
elasticsearch {
hosts => ["172.16.100.70","172.16.100.71","172.16.100.111"]
sniffing => true #单机模式关闭此选项
sniffing_delay => 5
manage_template => false
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
```
==协议:新插件支持三种协议: node,http 和 transpor。==
配置完成保存退出,这个配置主要实现logstash 将beats 收集的数据发送到elasticsearch ,
如果你想添加对其他应用程序使用的过滤器Filebeat输入,确保名称的文件所以他们之间的输入和输出配置(即02 - 30之间)。
##### 测试配置正确性,返回ok 为正常。
sudo service logstash configtest
##### 2.3.7:添加开机启动,启动服务;
sudo chkconfig logstash on
sudo /etc/init.d/logstash start
==logstash 使用systemctl 有问题,具体原因待查==
##### 检查,验证服务器端口
```
lsof -n -i:5044
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 13426 logstash 15u IPv6 88329771
```
##### 使用 curl 命令发送请求来查看 ES 是否接收到了数据
curl 'http://localhost:9200/_search?pretty'
---
## 添加filebeat客户端
##### 安装部署 Filebeat
##### 添加yum 签名key:
```
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch ```
##### 添加 beats.repo 到 /etc/yum.repos.d/ 目录
```
cat >/etc/yum.repos.d/beats.repo <<-EOF
[beats]
name=Elastic Beats Repository
baseurl=https://packages.elastic.co/beats/yum/el/$basearch
enabled=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
gpgcheck=1
EOF
```
##### 2.5.4:安装filebeat 服务
sudo yum install filebeat -y
##### 2.5.5:添加开机启动,启动服务
sudo systemctl start filebeat
sudo systemctl enable filebeat
### 源码安装filebeat 服务
##### 2.6.1:下载软件包:
curl -L -O https://download.elastic.co/beats/filebeat/filebeat-1.2.3-x86_64.rpm
##### 安装服务
yum install filebeat-1.2.3-x86_64.rpm
##### 配置服务:
sudo vi /etc/filebeat/filebeat.yml
我们将修改现有的发送日志文件配置,仅发送安全、消息日志。在路径下,注释掉——/var/log/*.日志文件。这将防止Filebeat发送所有日志。
filebeat.yml
```
...
paths:
- /var/log/secure
- /var/log/messages
# - /var/log/*.log
...
```
然后找到指定的行document_type:取消它,改变它的值,“syslog”。
filebeat.yml
```
...
document_type: syslog
...
```
==上面的配置指定日志类型为syslog(类型,在Logstash过滤器中使用)==
配置Filebeat连接Logstash服务器的端口5044。
filebeat.yml
```
### Logstash as output
logstash:
# The Logstash hosts
hosts: ["ELK_server_private_IP:5044"]
#配置日志最大装载量
bulk_max_size: 1024
#配置ssl 证书信息,不使用ssl,忽略此配置
filebeat.yml
...
tls:
# List of root certificates for HTTPS server verifications
certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"]
This configures Filebeat to use the SSL certificate that we created on the ELK Server.
```
保存退出
##### 2.6.4:添加开机启动,启动服务
sudo systemctl start filebeat
sudo systemctl enable filebeat
完成以上配置,Filebeat将发送你的syslog消息和secure到你的ELK服务器,其它节点重复以上配置即可。
##### filebeat 调试命令;
whereis filebeat
filebeat: /usr/bin/filebeat /etc/filebeat
##### 测试配置正确性
filebeat -configtest -e
以上配置设置ok,Filebeat(客户端)会将数据发送Logstash发送日志到elk服务器上。Logstash应该Filebeat数据加载到Elasticsearch日期戳的指数,filebeat-YYYY.MM.DD。
##### 导入 Filebeat 索引模板到 Elasticsearch
```
我们计划使用filebeat 处理日志到elasticsearch 收下要导入一个配置模板,elasticsearch 将按照模板格式对数据进行处理;
##### 先下载一个filebeat模板到本地目录;
cd ~
curl -O https://gist.githubusercontent.com/thisismitch/3429023e8438cc25b86c/raw/d8c479e2a1adcea8b1fe86570e42abab0f10f364/filebeat-index-template.json
##### 执行模板导入命令
curl -XPUT 'http://localhost:9200/_template/filebeat?pretty' -d@filebeat-index-template.json
##### 执行成功返回结果如下
{
"acknowledged" : true
}
```
##### 确认elk 服务器是否收到数据,
测试命令如下,在elk 服务器执行
```
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty'
```
##### 2.6.7:导入模板命令:
curl -XPUT 'http://localhost:9200/_template/filebeat' -d@/etc/filebeat/filebeat.template.json
#####参考文档:
``` https://www.elastic.co/guide/en/beats/filebeat/current/index.html https://www.elastic.co/guide/en/beats/libbeat/1.2/setup-repositories.html http://blog.smoker.cc/docker/20160325.html https://www.digitalocean.com/community/tutorials/how-to-install-elasticsearch-logstash-and-kibana-elk-stack-on-centos-7 http://www.tuicool.com/articles/YfAjI3a 安装Logstash:https://www.elastic.co/guide/en/beats/libbeat/1.2/setup-repositories.html
```
```
Elasticsearch作为日志的存储和索引平台;
Kibana 用来从 Elasticsearch获取数据,进行数据可视化,定制数据报表;
Logstash 依靠强大繁多的插件作为日志加工平台;
Filebeat 用来放到各个主机中收集指定位置的日志,将收集到日志发送到 Logstash;
Log4j 直接与 Logstash 连接,将日志直接
Logstash(当然此处也可以用 Filebeat 收集 tomcat 的日志)。
```
#### port
```
Elasticsearch
9200:对外提供服务的 HTTP 端口
9300:作为交互的 TCP 端口
Logstash
5000: Logstash TCP input
5044:用于接收来着 Filebeat 收集的日志数据
4569:用于接收来着 Log4j 的日志数据
8080:用于接收来自插件 Logstash-input-http 的日志数据
Kibana
5601 端口用于 Kibana的界面
```
#### 安装环境介绍:
```
- 系统版本
more /etc/redhat-release
CentOS Linux release 7.2.1511 (Core)
- 系统内核
uname -a
Linux yunwei-ts-100-71 3.10.0-327.13.1.el7.x86_64 #1 SMP Thu Mar 31 16:04:38 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
- java 版本
java -version
openjdk version "1.8.0_101"
OpenJDK Runtime Environment (build 1.8.0_101-b13)
OpenJDK 64-Bit Server VM (build 25.101-b13, mixed mode)
- 如果版本过低,或者没有安装执行命令如下:
yum install java-1.8.0-*
注意: Logstash需要Java 8或更高版本.可以使用 http://www.oracle.com/technetwork/java/javase/downloads/index.html [oracle官方版本] 或者使用开源版本OpenJDK: http://openjdk.java.net/. ```
#### 二:集群安装配置
```
- 测试集群规划
主机名 IP地址
yunwei-ts-100-70 172.16.1.70
yunwei-ts-100-71 172.16.1.71
yunwei-ts-100-111 172.16.1.111
- 软件版本:
elasticsearch 2.4.1
logstash.noarch 1:2.3.4-1
filebeat-1.2.3
kibana.x86_64 0:4.5.3-1
```
### 安装部署elasticsearch集群
##### 简介
ElasticSearch原生支持Cluster模式,节点之间通过单播或多播进行通信;ElasticSearch Cluster能自动检测节点的增加、失效和恢复,并重新组织索引。
##### ELK的工作原理:
使用多播进行机器发现同一个集群内的节点,并汇总各个节点的返回组成一个集群,主节点要读取各个节点的
状态,在关键的时候进行数据的恢复,主节点会jian'shi监视各个节点的状态,并决定每个分片的位置,通过ping的request检测各失效的节点。
##### elasticsearch的基本结构认识
```
以mysql数据库为实例对应理解:
mysql 数据库databases 表tables 行rows 列columns
es 索引indices 类型types 文档documents 字段fields
```
##### elasticsearch中所说的索引容易混淆,3种含义:
```
1. 索引(名词) 如上面类比,一个索引(index)就好比是mysql中的数据库,它是存储数据的地方。
2. 索引(动词)表示把一个文档存储到索引(名词)里。
3. 倒排索引 好比mysql为特定列增加一个索引。
- 和mysql类似,每个库都得有表,还有表的结构。es的每一个索引都有个类型,而每个type(类型)得有个mapping (映射)。mapping就像是mysql中的表结构, 他将每个字段匹配为一种确定的数据类型(string,date等)。
- 你可以向已有映射中增加字段,但你不能修改它。如果一个字段在映射中已经存在,这可能意味着那个字段的数据已经被索引。
- 如果你改变了字段映射,那已经被索引的数据将错误并且不能被正确的搜索到.为了提高搜索的效率,es使用倒排索引来做全文搜索。通过analyzer(分词器)先把需要分析的文本,表征化为适合的term(词),然后标准化这些term,使他们容易被搜索到。(比如说模糊大小写,空格等等)
```
##### 集群规划
```
主机名 IP 集群服务
yunwei-ts-100-70 172.16.100.70 (elasticsearch)
yunwei-ts-100-70 172.16.100.71 (elasticsearch)
yunwei-ts-100-70 172.16.100.111 (elasticsearch)
软件版本: 2.4.1-1
```
#### 安装 Elasticsearch
###### 添加yum 签名key,
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
###### 添加 elasticsearch.repo 到 /etc/yum.repos.d/ 目录
```
cat >/etc/yum.repos.d/elasticsearch.repo <<-EOF
[elasticsearch-2.x]
name=Elasticsearch repository for 2.x packages
baseurl=https://packages.elastic.co/elasticsearch/2.x/centos
gpgcheck=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
EOF
```
###### 2.1.3:安装软件包
```
yum install elasticsearch -y
```
###### 建立slasticsearch 存储数据的目录
```
mkdir -p /data/elasticsearch
chown elasticsearch.elasticsearch /data/elasticsearch
```
###### 2.1.4:调整配置文件
```
vi /etc/elasticsearch/elasticsearch.yml
cluster.name: ptsearch # 组名(同一个组,组名必须一致)
node.name: yunwei-ts-100-70 # 节点名称,建议和主机名一致
path.data: /data/elasticsearch # 数据存放的路径
path.logs: /var/log/elasticsearch/ # 日志存放的路径
bootstrap.mlockall: true # 锁住内存,不被使用到交换分区去
network.host: 0.0.0.0 # 网络设置
http.port: 9200 # 端口
discovery.zen.ping.unicast.hosts: ["172.16.100.71","172.16.100.111"] #手动发现节点,写本机之外的集群节点IP地址
discovery.zen.ping.multicast.enabled: false #关闭多播模式
```
==以上配置3台elasticsearch节点都要配,注意nodename写每台主机的名称,discovery.zen.ping.unicast.hosts:xie写本机之外的集群节点IP地址。==
###### 2.1.5:添加开机启动
systemctl enable elasticsearch.service
###### 启动服务
systemctl start elasticsearch
###### 查看服务状态
```
systemctl status elasticsearch
..............
Process: 6470 ExecStartPre=/usr/share/elasticsearch/bin/elasticsearch-systemd-pre-exec (code=exited, status=0/SUCCESS)
Main PID: 6473 (java)
Memory: 280.2M
CGroup: /system.slice/elasticsearch.service
└─6473 /bin/java -Xms256m -Xmx1g -Djava.awt.headless=true
```
==注意:上面可以看出elasticsearch设置默认的内存最小256m,最大1g==
##### 2.1.6:检查,验证服务器端口
```
netstat -antlp |egrep "9200|9300"
tcp 0 0 172.16.100.70:9200 172.16.3.151:36013 SYN_RECV -
tcp 0 0 172.16.100.70:9200 172.16.3.151:36012 SYN_RECV -
tcp 0 0 127.0.0.1:35793 127.0.0.1:9200 TIME_WAIT -
tcp 0 0 127.0.0.1:35791 127.0.0.1:9200 TIME_WAIT -
tcp 0 0 127.0.0.1:35794 127.0.0.1:9200 TIME_WAIT -
tcp 0 0 127.0.0.1:35792 127.0.0.1:9200 TIME_WAIT -
tcp6 0 0 :::9200 :::* LISTEN 6473/java
tcp6 0 0 :::9300 :::* LISTEN 6473/java
tcp6 0 0 172.16.100.70:53651 172.16.6.24:9200 ESTABLISHED 19098/java
tcp6 0 1 172.16.100.70:35771 10.42.0.1:9200 SYN_SENT 19098/java
```
##### 启动两个端口
```
9200:集群之间事务通信
9300:集群选举等
```
##### elasticsearch 目录环境介绍:
```
Environment=ES_HOME=/usr/share/elasticsearch
Environment=CONF_DIR=/etc/elasticsearch
Environment=DATA_DIR=/var/lib/elasticsearch
Environment=LOG_DIR=/var/log/elasticsearch
Environment=PID_DIR=/var/run/elasticsearch
EnvironmentFile=-/etc/sysconfig/elasticsearch
```
## 验证服务接口响应
##### 通过浏览器访问:
http://172.16.100.70:9200/ 返回数据如下:
```
{
"name" : "yunwei-ts-100-70", 《《===节点名称
"cluster_name" : "ptsearch", 《《===集群名称
"version" : {
"number" : "2.3.4",
"build_hash" : "e455fd0c13dceca8dbbdbb1665d068ae55dabe3f",
"build_timestamp" : "2016-06-30T11:24:31Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
}
```
##### 通过命令的方式查看数据(可以在node1本机上查看,也可以在其他机器上访问node的9200查看,如下)
```
curl -i -XGET 'http://172.16.100.70:9200/_count?pretty' -d '{"query":{"match_all":{}}}'
HTTP/1.1 200 OK
Content-Type: application/json; charset=UTF-8
Content-Length: 95
{
"count" : 2,
"_shards" : {
"total" : 1, 《《===集群加入节点后数据会变化
"successful" : 1,
"failed" : 0
}
}
```
##### 查看健康信息:
curl -XGET 'http://172.16.100.70:9200/_cluster/health?pretty'
```
{
"cluster_name" : "ptsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 1,
"active_shards" : 1,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 1,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 50.0
}
```
##### 查看节点数:
curl -XGET '172.16.100.70:9200/_cat/nodes?v'
```
host ip heap.percent ram.percent load node.role master name
172.16.100.111 172.16.100.111 7 98 0.65 d m yunwei-ts-100-111
172.16.100.70 172.16.100.70 5 69 0.00 d * yunwei-ts-100-70 <<主节点
172.16.100.71 172.16.100.71 7 97 0.00 d m yunwei-ts-100-71
```
##### 查看节点分片信息:
curl -XGET '172.16.100.70:9200/_cat/indices?v'
```
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana 1 1 2 0 38.4kb 19.2kb
green open .marvel-es-1-2016.10.11 1 1 1369 0 840.1kb 420kb
green open .marvel-es-1-2016.10.10 1 1 4468 0 1.2mb 634.9kb
```
#### elasticsearch日志定期清理日志、索引
索引旧数据需要清理,清理所以可以使用Elasticsearch的API。
例如:
删除某个索引2016年11月份的所有索引,可以使用下面的命令:
```
curl -XDELETE 'http://localhost:9200/customer-2016.11.*'
```
## ElasticSearch参数优化
(提高检索效率)
```
一、Linux操作系统优化
1) 调整系统资源最大句柄数
/etc/security/limits.conf
在文件中增加
* soft nofile 65536
* hard nofile 65536
2) 设置bootstrap.mlockall: 为true来锁住内存。因为当jvm开始swapping时es的效率会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。
同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过`ulimit -l unlimited`命令。
3) 关闭文件更新时间
cat /etc/fstab
/dev/sda7 /data/elasticSearch ext4 defaults,noatime 0 0
4) 提高ES占用内存(elasticsearch.in.sh)
ES_MIN_MEM=30g (一般为物理内存一半,但不要超过31G)
ES_MAX_MEM=30g
官方建议: https://www.elastic.co/guide/en/elasticsearch/guide/current/heap-sizing.html#compressed_oops ```
## 二、Elasticsearch 字段缓存优化
```
1) Fielddata(字段数据)
Elasticsearh默认会将fielddata全部加载到内存。但是,内存是有限的,需要对fielddata内存做下限制:Indices.fieldata.cache.size 节点用于fielddata的最大内存,如果fielddata达到该阀值,就会把旧数据交换出去。默认设置是不限制,建议设置10%。
2) doc-values
其实就是在elasticsearch 将数据写入索引的时候,提前生成好fileddata内容,并记录到磁盘上。因为fileddata数据是顺序读写的,所以即使在磁盘上,通过文件系统层的缓存,也可以获得相当不错的性能。doc_values只能给不分词(对于字符串字段就是设置了 "index":"not_analyzed",数值和时间字段默认就没有分词) 的字段配置生效。
如相应字段设置应该是:
"@timestamp":{
"type":"date",
"index":"not_analyzed",
"doc_values":true,
}
优化参考文档: https://my.oschina.net/davehe/blog/549189 ```
## 安装elasticsearch插件
安装部署访问下面博客页面: http://michaelkang.blog.51cto.com/1553154/1861838
### elasticsearch 安装配置故障排查:
###### elasticsearch服务启动报错:
```
[2016-10-11 16:18:43,974][WARN ][bootstrap ] Unable to lock JVM Memory: error=12,reason=Cannot allocate memory
[2016-10-11 16:18:43,975][WARN ][bootstrap ] This can result in part of the JVM being swapped out.
[2016-10-11 16:18:43,975][WARN ][bootstrap ] Increase RLIMIT_MEMLOCK, soft limit: 65536, hard limit: 65536
[2016-10-11 16:18:43,975][WARN ][bootstrap ] These can be adjusted by modifying /etc/security/limits.conf, for example:
# allow user 'elasticsearch' mlockall
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimited
[2016-10-11 16:18:43,975][WARN ][bootstrap ] If you are logged in interactively, you will have to re-login for the new limits to take effect.
[2016-10-11 16:18:44,165][INFO ][node ] [yunwei-ts-100-71] version[2.4.1], pid[31324], build[c67dc32/2016-09-27T18:57:55Z]
[2016-10-11 16:18:44,165][INFO ][node ] [yunwei-ts-100-71] initializing ...
[2016-10-11 16:18:44,719][ERROR][bootstrap ] Exception
部分内容省略
```
###### 解决办法:
```
1:修改启动文件
systemd:
/usr/lib/systemd/system/elasticsearch.service set: LimitMEMLOCK=infinity
SysV:
/etc/sysconfig/elasticsearch set: MAX_LOCKED_MEMORY=unlimited
Upstart:
/etc/default/elasticsearch set: MAX_LOCKED_MEMORY=unlimited
Then restart Elasticsearch.
2:在limit 文件添加配置如下:
/etc/security/limits.conf
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimited
```
---
## 2.2:安装配置Kibana
##### 2.2.1:添加yum 签名key,添加 kibana.repo 到 /etc/yum.repos.d/ 目录
```
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
cat >/etc/yum.repos.d/kibana.repo <<-EOF
[kibana-4.5]
name=Kibana repository for 4.5.x packages
baseurl=http://packages.elastic.co/kibana/4.5/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
EOF
```
##### 安装软件包,
软件版本: 4.5.4-1
```
yum install kibana -y
```
##### 调整配置文件
```
sudo vi /opt/kibana/config/kibana.yml
......
4 # The host to bind the server to.
5 # server.host: "0.0.0.0"
6 server.host: "0.0.0.0" #
7
8 # If you are running kibana behind a proxy, and want to mount it at a path,
9 # specify that path here. The basePath can't end in a slash.
10 # server.basePath: ""
11
12 # The maximum payload size in bytes on incoming server requests.
13 # server.maxPayloadBytes: 1048576
14
15 # The Elasticsearch instance to use for all your queries.
16 # elasticsearch.url: "http://localhost:9200"
17 elasticsearch.url: "http://localhost:9200" #elasticsearch 地址 《=====
18..
```
==elasticsearch cluster地址,可以写多个节点,kibana 只会取最后一个连接,不支持多节点负载均衡和自动冗余==
```
elasticsearch.url: http://172.16.100.111:9200 elasticsearch.url: http://172.16.100.70:9200 elasticsearch.url: http://172.16.100.71:9200
```
##### 2.2.5:添加开机启动,启动服务;
```
chkconfig --add kibana
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable kibana.service
sudo systemctl start kibana
```
##### 检查,验证服务器端口
```
lsof -n -i:5601
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
node 29895 kibana 11u IPv4 9963707 0t0 TCP *:esmagent (LISTEN)
```
##### 验证访问:
http:172.16.100.70:5601
### 2.4: 安装部署 Kibana Dashboards
##### 下载软件包
```
cd ~
curl -L -O https://download.elastic.co/beats/dashboards/beats-dashboards-1.1.0.zip ```
##### 安装解压软件,解压软件包
```
sudo yum -y install unzip
unzip beats-dashboards-*.zip
```
##### 2.4.3:导入基础显示面板, 将数据导入 Elasticsearch 命令如下:
```
cd beats-dashboards-*
./load.sh
```
指向上面的命令将导入如下查询模板信息
```
[packetbeat-]YYYY.MM.DD
[topbeat-]YYYY.MM.DD
[filebeat-]YYYY.MM.DD
[winlogbeat-]YYYY.MM.DD
```
##### 访问页面,即可查看索引 http://172.16.100.70:5601/
---
## 2.3:安装配置 Logstash
##### 插件简介

##### 官方参考信息: https://www.elastic.co/guide/en/logstash/current/index.html
##### 添加yum 签名key:
```
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch ```
##### 添加 logstash.repo 到 /etc/yum.repos.d/ 目录
```
cat >/etc/yum.repos.d/logstash.repo <<-EOF
[logstash-2.4]
name=Logstash repository for 2.4.x packages
baseurl=https://packages.elastic.co/logstash/2.4/centos
gpgcheck=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
EOF
```
2.3.3:安装软件包
```
yum install logstash -y
```
### 配置日志输入、输出
[tuopu](!http://image.3001.net/images/20150914/14422334919180.png)
##### 2.3.4:调整配置文件
vi /etc/logstash/conf.d/02-beats-input.conf
```
input {
beats {
port => 5044
# ssl => true
# ssl_certificate => "/etc/pki/tls/certs/logstash-forwarder.crt"
# ssl_key => "/etc/pki/tls/private/logstash-forwarder.key"
}
}
```
logstack 输入默认使用5044 端口,如果需要使用ssl 加密传输,可以配置自己证书
##### 创建一个配置文件,10-syslog-filter.conf ,添加 syslog messages,过滤配置。
sudo vi /etc/logstash/conf.d/10-syslog-filter.conf
nsert the following syslog filter configuration:
```
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
syslog_pri { }
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
```
配置完成保存退出,上面的配置是添加一个 syslog 的过滤标签,将输入的日志进行格式化并生成查询表;
##### 再创建一个配置文件 30-elasticsearch-output.conf:
sudo vi /etc/logstash/conf.d/30-elasticsearch-output.conf
添加日志输出配置如下:
```
output {
elasticsearch {
hosts => ["172.16.100.70","172.16.100.71","172.16.100.111"]
sniffing => true #单机模式关闭此选项
sniffing_delay => 5
manage_template => false
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
```
==协议:新插件支持三种协议: node,http 和 transpor。==
配置完成保存退出,这个配置主要实现logstash 将beats 收集的数据发送到elasticsearch ,
如果你想添加对其他应用程序使用的过滤器Filebeat输入,确保名称的文件所以他们之间的输入和输出配置(即02 - 30之间)。
##### 测试配置正确性,返回ok 为正常。
sudo service logstash configtest
##### 2.3.7:添加开机启动,启动服务;
sudo chkconfig logstash on
sudo /etc/init.d/logstash start
==logstash 使用systemctl 有问题,具体原因待查==
##### 检查,验证服务器端口
```
lsof -n -i:5044
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 13426 logstash 15u IPv6 88329771
```
##### 使用 curl 命令发送请求来查看 ES 是否接收到了数据
curl 'http://localhost:9200/_search?pretty'
---
## 添加filebeat客户端
##### 安装部署 Filebeat
##### 添加yum 签名key:
```
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch ```
##### 添加 beats.repo 到 /etc/yum.repos.d/ 目录
```
cat >/etc/yum.repos.d/beats.repo <<-EOF
[beats]
name=Elastic Beats Repository
baseurl=https://packages.elastic.co/beats/yum/el/$basearch
enabled=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
gpgcheck=1
EOF
```
##### 2.5.4:安装filebeat 服务
sudo yum install filebeat -y
##### 2.5.5:添加开机启动,启动服务
sudo systemctl start filebeat
sudo systemctl enable filebeat
### 源码安装filebeat 服务
##### 2.6.1:下载软件包:
curl -L -O https://download.elastic.co/beats/filebeat/filebeat-1.2.3-x86_64.rpm
##### 安装服务
yum install filebeat-1.2.3-x86_64.rpm
##### 配置服务:
sudo vi /etc/filebeat/filebeat.yml
我们将修改现有的发送日志文件配置,仅发送安全、消息日志。在路径下,注释掉——/var/log/*.日志文件。这将防止Filebeat发送所有日志。
filebeat.yml
```
...
paths:
- /var/log/secure
- /var/log/messages
# - /var/log/*.log
...
```
然后找到指定的行document_type:取消它,改变它的值,“syslog”。
filebeat.yml
```
...
document_type: syslog
...
```
==上面的配置指定日志类型为syslog(类型,在Logstash过滤器中使用)==
配置Filebeat连接Logstash服务器的端口5044。
filebeat.yml
```
### Logstash as output
logstash:
# The Logstash hosts
hosts: ["ELK_server_private_IP:5044"]
#配置日志最大装载量
bulk_max_size: 1024
#配置ssl 证书信息,不使用ssl,忽略此配置
filebeat.yml
...
tls:
# List of root certificates for HTTPS server verifications
certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"]
This configures Filebeat to use the SSL certificate that we created on the ELK Server.
```
保存退出
##### 2.6.4:添加开机启动,启动服务
sudo systemctl start filebeat
sudo systemctl enable filebeat
完成以上配置,Filebeat将发送你的syslog消息和secure到你的ELK服务器,其它节点重复以上配置即可。
##### filebeat 调试命令;
whereis filebeat
filebeat: /usr/bin/filebeat /etc/filebeat
##### 测试配置正确性
filebeat -configtest -e
以上配置设置ok,Filebeat(客户端)会将数据发送Logstash发送日志到elk服务器上。Logstash应该Filebeat数据加载到Elasticsearch日期戳的指数,filebeat-YYYY.MM.DD。
##### 导入 Filebeat 索引模板到 Elasticsearch
```
我们计划使用filebeat 处理日志到elasticsearch 收下要导入一个配置模板,elasticsearch 将按照模板格式对数据进行处理;
##### 先下载一个filebeat模板到本地目录;
cd ~
curl -O https://gist.githubusercontent.com/thisismitch/3429023e8438cc25b86c/raw/d8c479e2a1adcea8b1fe86570e42abab0f10f364/filebeat-index-template.json
##### 执行模板导入命令
curl -XPUT 'http://localhost:9200/_template/filebeat?pretty' -d@filebeat-index-template.json
##### 执行成功返回结果如下
{
"acknowledged" : true
}
```
##### 确认elk 服务器是否收到数据,
测试命令如下,在elk 服务器执行
```
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty'
```
##### 2.6.7:导入模板命令:
curl -XPUT 'http://localhost:9200/_template/filebeat' -d@/etc/filebeat/filebeat.template.json
#####参考文档:
``` https://www.elastic.co/guide/en/beats/filebeat/current/index.html https://www.elastic.co/guide/en/beats/libbeat/1.2/setup-repositories.html http://blog.smoker.cc/docker/20160325.html https://www.digitalocean.com/community/tutorials/how-to-install-elasticsearch-logstash-and-kibana-elk-stack-on-centos-7 http://www.tuicool.com/articles/YfAjI3a 安装Logstash:https://www.elastic.co/guide/en/beats/libbeat/1.2/setup-repositories.html
```

相关文章推荐
- Hadoop2.6.2完全分布式集群HA模式安装配置详解
- LVS-DR负载均衡集群的安装配置详解
- CentOS 7下安装 redis 3.0.6并配置集群的过程详解
- Linux集群服务LVS概述与安装配置详解 推荐
- Linux集群服务LVS概述与安装配置详解
- Hadoop-2.5.2集群安装配置详解
- Kibana安装(图文详解)(多节点的ELK集群安装在一个节点就好)
- Filebeat-1.3.1安装和设置(图文详解)(多节点的ELK集群安装在一个节点就好)(以Console Output为例)
- redis cluster 集群 安装 配置 详解
- FastDFS 5.0.1 + nginx + cache 集群安装配置详解
- MySQL数据库集群实现负载均衡的安装配置详解
- MySQL数据库集群实现负载均衡的安装配置详解
- redis cluster 集群 安装 配置 详解
- 深入分析redis cluster 集群安装配置详解
- 深入分析redis cluster 集群安装配置详解
- CentOS6.5下redis安装部署配置指南、常用命令、主从同步集群、redis-php学习资料整合详解
- Hadoop-2.5.2集群安装配置详解
- 王高利:CentOS6.5下redis安装部署配置指南、常用命令、主从同步集群、redis-php学习资料整合详解
- MySQL数据库集群实现负载均衡的安装配置详解
- Hadoop2.6.2完全分布式集群HA模式安装配置详解