hive表存储格式及压缩
2016-10-13 00:00
183 查看
1.textfile
Hive数据表的默认格式,磁盘开销大,数据解析开销大存储方式:行存储
压缩方式:使用Gzip,Bzip2等压缩算法压缩,压缩后的文件不支持split
但在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
--创建数据表: create table if not exists textfile_table( site string, url string, pv bigint, label string) row format delimited fields terminated by '\t' stored as textfile; --插入数据: set hive.exec.compress.output=true; --启用压缩格式 set mapred.output.compress=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; --指定输出的压缩格式为Gzip set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec; insert overwrite table textfile_table select * from T_Name;
2.sequencefile
Hadoop API提供的一种二进制文件,以<key,value>的形式序列化到文件中存储方式:行存储
压缩方式:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
优势是文件和hadoop api中的MapFile是相互兼容的
create table if not exists seqfile_table( site string, url string, pv bigint, label string) row format delimited fields terminated by '\t' stored as sequencefile; --插入数据操作: set hive.exec.compress.output=true; --启用输出压缩格式 set mapred.output.compress=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; --指定输出压缩格式为Gzip set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec; SET mapred.output.compression.type=BLOCK; --指定为Block insert overwrite table seqfile_table select * from T_Name;
3.rcfile
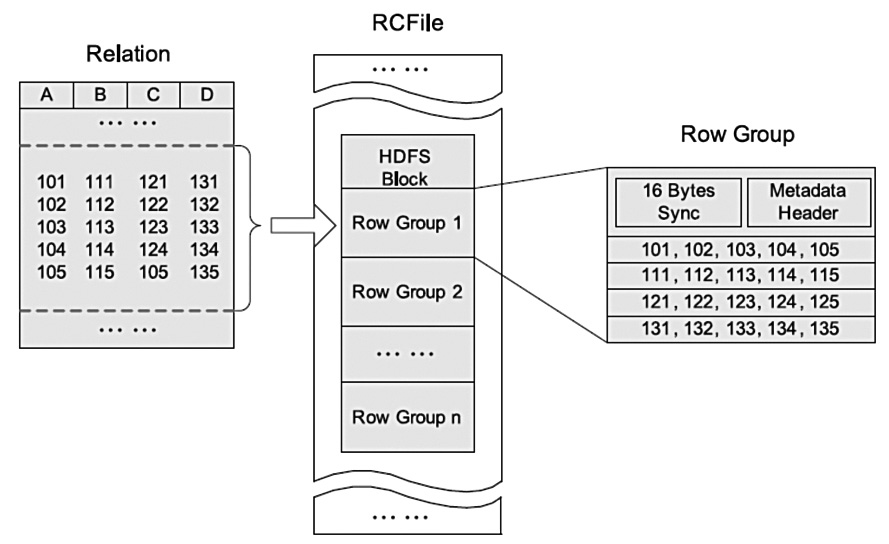
存储方式:数据按行分组,每组内按列存储,默认行组大小是4MB行列混合存储的优点:
同一行的数据位于同一节点,因此元组重构的开销很低
与列存一样,RCFile 能够利用列维度的数据压缩,并跳过不必要的列读取
RCFile的一个行组包括三个部分:
第一部分是行组头部的【同步标识】,主要用于分隔 hdfs 块中的两个连续行组
第二部分是行组的【元数据头部】,用于存储行组单元的信息,包括行组中的记录数、每个列的字节数、列中每个域的字节数
第三部分是【表格数据段】,即实际的列存储数据。在该部分中,同一列的所有域顺序存储。
从图可以看出,首先存储了列 A 的所有域,然后存储列 B 的所有域等
create table if not exists rcfile_table( site string, url string, pv bigint, label string) row format delimited fields terminated by '\t' stored as rcfile; --插入数据操作: set hive.exec.compress.output=true; set mapred.output.compress=true; set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec; insert overwrite table rcfile_table select * from T_Name;
4.orcfile
存储方式:数据按行分组,每块按照列存储,默认行组大小为250MB压缩方式:ZLIB和SNAPPY,默认ZLIB。压缩速度快 快速列存取
效率比rcfile高,是rcfile的改良版本
运用ORC File可以提高Hive的读、写以及处理数据的性能。
与RCFile格式相比,ORCFile有以下优点:
(1)、每个task只输出单个文件,这样可以减少NameNode的负载
(2)、支持复杂的数据类型,如: datetime, decimal, 以及一些复杂类型(struct, list, map, and union)
(3)、在文件中存储了一些轻量级的索引数据
(4)、基于数据类型的块模式压缩:integer类型列用行程长度编码;String类型列用字典编码;
(5)、用多个互相独立的RecordReaders并行读相同的文件
(6)、无需扫描markers就可以分割文件
(7)、绑定读写所需要的内存
(8)、metadata的存储是用 Protocol Buffers的,所以它支持添加和删除一些列
create table Addresses (
name string,
street string,
city string
)
row format delimited fields terminated by '\t'
stored as orc tblproperties ("orc.compress"="NONE");5.自定义格式
用户可以通过实现inputformat和 outputformat来自定义输入输出格式。create table myfile_table(str STRING) stored as inputformat 'org.apache.hadoop.hive.contrib.fileformat.base64.Base64TextInputFormat' outputformat 'org.apache.hadoop.hive.contrib.fileformat.base64.Base64TextOutputFormat';
查询测试
实验所用表为15列,共约300多条非重复记录,总记录数20123648| 格式 | 大小 | 可分割 | * | col5 | count(*) | max(c1) | max(c1) where c5='xxx' |
| textfile | 1.3GB | 是 | 31s | 21s | 23s | 25s | 26s |
| rc-none | 1.0GB | 是 | 31s | 20s | 22s | 25s | 23s |
| rc-gzip | 1.6MB | 否 | 27s | 1s | 1s | 31s | 28s |
| orc-none | 53.3MB | 是 | 20s | 1s | 1s | 21s | 22s |
| orc-zlib | 645.2KB | 是 | 20s | 1s | 1s | 21s | 21s |
| 格式 | 大小 | 可分割 | * | c5 | count(*) | max(c5) | max(c5) where c9='T' | c2,count(*) group by c2 |
| textfile | 3.3G | 是 | 27 | 10 | 12 | 12 | 7 | 28 |
| seq-none | 3.46G | 是 | 25 | 7 | 12 | 12 | 16 | 8 |
| seq-block | 0.91G | 是 | 47 | 16 | 10 | 10 | 10 | 10 |
| orc-none | 1.7G | 是 | 37 | 5 | 5 | 5 | 5 | 8 |
| orc-zlib | 0.66G | 是 | 37 | 6 | 8 | 5 | 5 | 8 |
TextFile 默认格式加载速度最快,可采用Gzip、bzip2等压缩,压缩后的无法split,无法并行处理
SequenceFile 压缩率最低,查询速度一般,三种压缩格式NONE,RECORD,BLOCK
RCfile 压缩率高,查询速度最快,数据加载最慢
ORCfile 压缩率高,查询速度快,数据加载快

相关文章推荐
- 【腾讯Bugly干货分享】舞动的表情包——浅析GIF格式图片的存储和压缩
- Hive 文件压缩存储格式(STORED AS)
- GZIP压缩原理分析(18)——第五章 Deflate算法详解(五09) 算法分析(03) 格式说明(02) 存储类型
- hbase 热修改存储压缩格式
- sphinx索引分析——文件格式和字典是double array trie 检索树,索引存储 – 多路归并排序,文档id压缩 – Variable Byte Coding
- Android中Bitmap格式压缩存储
- 浓缩的才是精华:浅析GIF格式图片的存储和压缩
- hive 存储格式和压缩方式 一:Snappy + SequenceFile
- libjpeg库编码图片为jpg(ffmpeg解码视频存储图片:RGB格式位图压缩为jpg格式图片)
- 创建GZIP压缩格式的HIVE表
- MR 代码优化及Hive优化(Hive中的存储格式与压缩格式)
- 【腾讯Bugly干货分享】舞动的表情包——浅析GIF格式图片的存储和压缩
- Apache Hive 存储方式、压缩格式
- 浓缩的才是精华:浅析GIF格式图片的存储和压缩
- Hive中压缩设置 和 Hive文件存储格式及使用
- 解剖SQLSERVER 第十三篇 Integers在行压缩和页压缩里的存储格式揭秘(译)
- 解剖SQLSERVER 第十三篇 Integers在行压缩和页压缩里的存储格式揭秘(译)
- libjpeg库编码图片为jpg(ffmpeg解码视频存储图片:RGB格式位图压缩为jpg格式图片)
- 创建GZIP压缩格式的HIVE表
- hive 压缩全解读(hive表存储格式和外部表支持加载的压缩的格式)